

Want to ensure your AI systems are reliable and high-performing? Start by integrating LLM evaluation into your CI/CD pipeline.
Here’s the deal: Traditional CI/CD focuses on catching bugs in deterministic systems. But with large language models (LLMs), the challenge is different. LLMs don’t “break”; they change behavior over time. This means you need continuous evaluation to monitor issues like hallucinations, bias, or semantic drift.
Key takeaways:
-
LLM evaluation assesses accuracy, tone, bias, and reliability instead of just pass/fail outcomes.
-
Automation ensures every code change, prompt engineering update, or model adjustment is tested before production.
-
Evaluation layers include deterministic checks (e.g., JSON validation), semantic scoring, and human review for high-risk tasks.
-
Tools like Latitude help with monitoring, feedback loops, and testing in both development and production environments.
Understanding CI/CD and LLM Evaluation
What is CI/CD?
Continuous Integration (CI) involves automatically testing and merging code changes to detect issues early in the development process. Continuous Deployment (CD) takes it a step further by automating the release of these changes into production environments. Together, CI and CD create a workflow that helps teams catch bugs before they reach users, ensuring smoother updates and faster delivery cycles.
In traditional software development, CI/CD pipelines are set up to run tests on every code commit. If the tests pass, the code progresses; if they fail, developers are quickly notified, allowing them to address issues immediately. This automation reduces manual effort and helps maintain a steady development pace.
What is LLM Evaluation?
LLM evaluation focuses on assessing the quality of large language models across aspects like accuracy, safety, tone, and reliability. Unlike standard software testing, which checks for outright crashes or errors, LLM evaluation looks for more nuanced issues. These include hallucinations, shifts in tone, and subtle inconsistencies that might not be immediately obvious but can affect user experience.
As Dextra Labs explains, “LLMs don’t ‘break’, they drift”. This means that instead of failing outright, models may gradually change their behavior over time. To address this, evaluation methods need to go beyond simple pass/fail metrics. Teams often use a mix of deterministic checks (like regex-based rules) and model-driven assessments to evaluate qualities such as helpfulness and creativity.
This evolving approach to evaluation lays the groundwork for incorporating it into CI/CD workflows.
Why Integrate LLM Evaluation into CI/CD?
Integrating LLM evaluation into CI/CD pipelines fundamentally changes how teams develop AI systems. Instead of treating evaluation as a one-time checkpoint, it becomes a continuous process that runs alongside every code change, prompt modification, or model update. This allows teams to monitor and address potential issues before they reach production.
By combining automated pipelines with semantic evaluations, teams can track and refine model behavior over time. The focus shifts from asking, “Did something break?” to “What changed, and does it matter?”
“LLMs don’t fit into CI/CD. CI/CD has to evolve around LLMs. Evaluation is no longer a gate, it’s a continuous signal.” - Dextra Labs
Core Components of LLM Evaluation in CI/CD
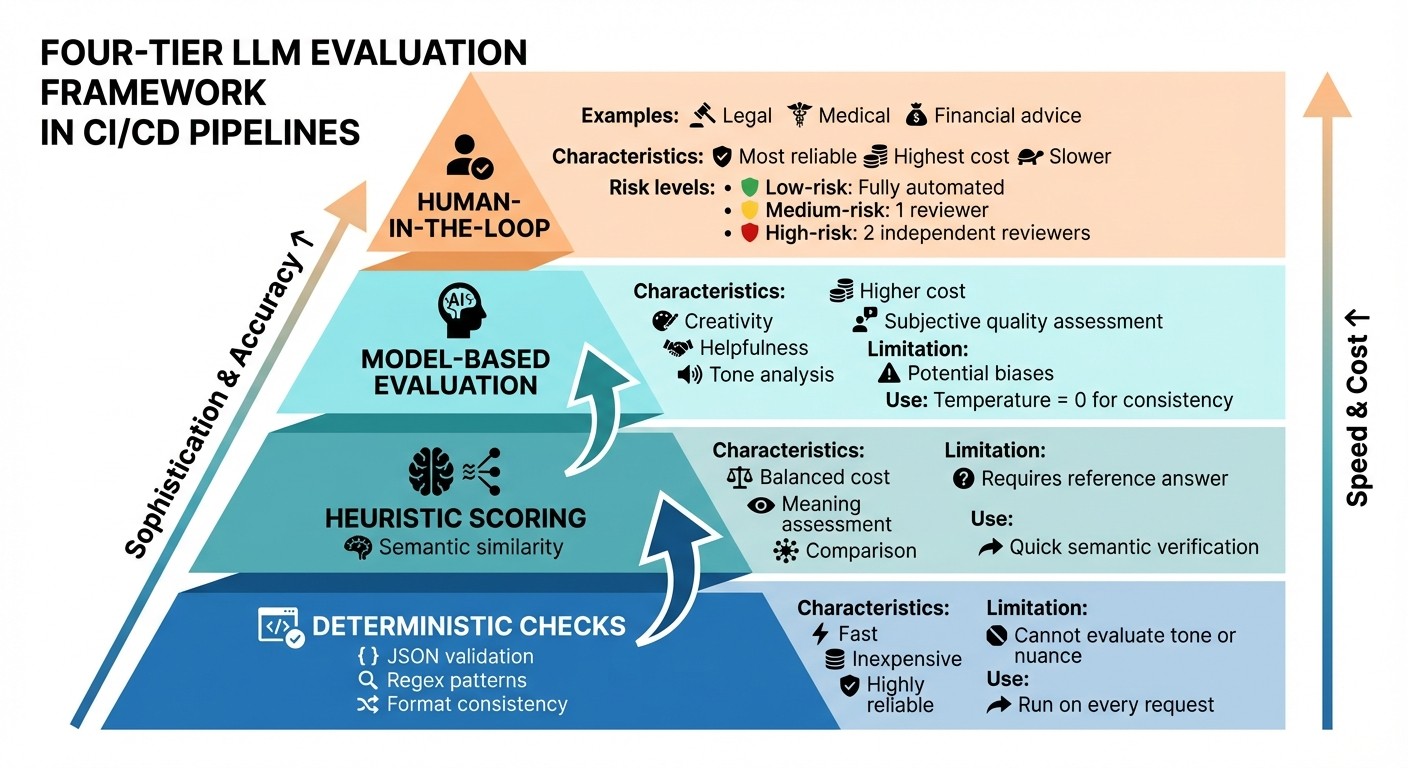
Layered LLM Evaluation Framework for CI/CD Pipelines
Creating a dependable evaluation system for large language models (LLMs) hinges on three main elements: datasets that reflect real-world scenarios , metrics that measure both technical accuracy and subjective quality , and thresholds that dictate when it’s safe to deploy changes. Together, these elements form a feedback loop that helps catch problems early.
Building Evaluation Datasets
An effective evaluation dataset includes several key components: the query itself , relevant context (especially critical for retrieval-augmented generation systems), a reference answer to serve as a baseline, descriptions of expected behavior for qualitative assessments, and metadata tags to classify issues by difficulty or failure type.
Rather than focusing on keyword matching, semantic evaluation emphasizes understanding the meaning behind responses. This involves techniques like embedding similarity and using LLMs to judge whether answers convey the correct information, even if phrased differently. Teams are shifting away from one-time evaluations toward continuous validation , where tests run automatically with every deployment to catch issues early in the development cycle.
Once datasets are in place, choosing the right evaluation metrics becomes the next step.
Evaluation Metrics and Methods
Different methods address different evaluation needs. Programmatic rules , such as regex or JSON validation, are ideal for checking format consistency. They’re fast, inexpensive, and highly reliable, but they can’t evaluate tone or nuance. Heuristic scoring , which uses semantic similarity, balances cost with the ability to assess meaning, though it requires a reference answer for comparison. LLM-as-a-judge techniques are effective for evaluating subjective qualities like creativity or helpfulness but come with higher costs and potential biases. For high-stakes applications, such as legal or medical use cases, human-in-the-loop reviews remain the most reliable option, despite being slower and more expensive.
For metrics tracking negative attributes, like toxicity or hallucination scores, tools must aim to minimize these values. These metrics are essential to the feedback loop that drives the CI/CD process.
Once metrics are defined, the final step is setting clear thresholds to guide deployment decisions.
Setting Pass/Fail Thresholds
Thresholds depend on the level of risk. Low-risk tasks, like basic summarization, can often be fully automated without human review. Medium-risk scenarios, such as customer support responses, usually require a single human reviewer before deployment. High-risk applications - like those involving legal, financial, or medical advice - typically demand validation from two independent reviewers before going live.
Thresholds act as signals to inform deployment decisions. For example, a small drop in semantic similarity might prompt further investigation but not block deployment, while a sudden increase in toxicity scores could trigger an immediate rollback. The key is to set these boundaries based on actual user impact and business needs. This ensures the system remains adaptive and responsive to real-world demands.
Setting Up LLM Evaluation in CI/CD Pipelines
Once you’ve designed effective evaluation components, the next step is to seamlessly integrate them into your CI/CD pipeline. This ensures that every prompt change goes through automated validation before it reaches production.
Configuring GitHub Actions and GitLab CI
Start by securing your API keys, such as OPENAI_API_KEY and LATITUDE_API_KEY, by storing them as masked and protected variables in your CI settings. This keeps sensitive information safe while enabling integration with external services.
Set up workflow triggers to run tests whenever relevant files are modified. For instance, use pull_request triggers with path filters like prompts/** to automatically validate prompt changes before merging. The process should include checking out the code, setting up the runtime environment (Node.js or Python), installing necessary dependencies, and ensuring the pipeline exits with a non-zero status if thresholds - like a 90% success rate or accuracy above 0.85 - aren’t met. This prevents merging until issues are resolved.
For GitLab CI, you can define a .gitlab-ci.yml file using a Node image to install evaluation tools and run tests. To optimize performance and reduce costs, implement caching for LLM API responses in .promptfoo/cache. Store test results as JSON or JUnit reports so they appear directly in the GitLab pipeline interface. Use the parallel feature to distribute large test suites across multiple nodes, cutting execution time significantly. Additionally, configure CI jobs to post evaluation summaries or links to detailed results as comments on merge requests. This allows reviewers to assess changes without leaving the platform.
Version Control for Prompts, Datasets, and Models
Treat your prompts like source code by storing them in files such as .promptl or .js within your Git repository. This enables branching, tracking changes, and rolling back to previous versions if a new prompt performs poorly. Include metadata in each prompt file to document version numbers, authors, and intended use. Maintain a CHANGELOG.md file to log updates, test results, and the impact on performance.
Build a golden dataset of 20–100 high-quality examples sourced from production logs. These examples should represent real-world scenarios and be tagged by difficulty or failure type. This organization helps prioritize testing based on risk levels. Such meticulous version control supports consistent monitoring and iterative improvements in production.
Using Latitude for Observability and Continuous Evaluation
Latitude helps bridge the gap between development and production by offering two evaluation modes. Use Batch Mode to run regression tests on golden datasets during CI/CD workflows, and enable Live Mode to monitor production traffic. Live Mode flags quality drops in real time, ensuring that issues are caught as they happen. You can toggle “Live Evaluation” in Latitude settings to track critical metrics like safety checks and formatting validation, preventing regressions from slipping through.
Latitude’s structured workflow allows you to observe model behavior, gather feedback from domain experts, and conduct evaluations - all within a single platform. This creates a continuous feedback loop where production insights inform future testing. When running LLM-as-a-judge evaluations in automated pipelines, set the temperature to 0 for consistent and reproducible scoring. To optimize for both speed and cost, layer your evaluations: start with fast, deterministic checks (like JSON schema or regex validation), move to heuristic scoring, and finally use LLM-as-a-judge for subjective qualities. This structured approach ensures efficiency without compromising on quality.
Scaling and Monitoring LLM Evaluations in Production
Once you’ve set up your integrated CI/CD pipeline, the next step is scaling and monitoring evaluations in production. This ensures your system stays reliable and adaptable as it handles real-world use cases.
Production Monitoring and Feedback Loops
Real-time monitoring is key to catching performance issues before they affect users. Use Live Mode to keep tabs on safety checks, format validation, and relevance metrics as your system processes actual production traffic. Unlike batch testing with golden datasets, Live Mode identifies problems as they happen.
Organize your monitoring efforts using tiered risk levels to manage resources effectively:
-
Low-risk tasks (e.g., simple text summarizations) can rely entirely on automation.
-
Medium-risk scenarios (like customer support responses) should include a single reviewer for oversight.
-
High-stakes applications (such as legal, financial, or medical advice) demand two reviewers, with response times adjusted based on the risk level.
To create a feedback loop, integrate production data - like user interactions, system performance, and expert reviews - back into your evaluation pipeline. For instance, if users flag problematic outputs, add those examples to your golden dataset. This way, future CI/CD evaluations can automatically catch similar issues. Such a process not only improves your system but also encourages collaboration across teams to refine model accuracy and reliability.
Cross-Team Collaboration
For effective scaling, collaboration between teams is critical. Product managers need access to AI quality metrics to make informed decisions about new features and user experience. Meanwhile, engineers depend on structured input from domain experts who can identify nuanced issues that automated tests might overlook. A unified workflow, like Latitude, can help teams monitor model behavior, provide feedback, and track progress over time by combining evaluation signals with production feedback.
Clearly defining ownership and accountability in the evaluation process is essential. Here’s how responsibilities can be divided:
-
Engineering teams manage deterministic checks, such as JSON schema validation and regex patterns. These are quick, cost-effective, and run on every request.
-
Product teams set heuristic scoring criteria to measure semantic relevance and similarity.
-
Domain experts conduct subjective evaluations, assessing qualities like tone and helpfulness through LLM-as-a-judge frameworks.
Conclusion
Adding LLM evaluations to your CI/CD pipeline is no longer just a nice-to-have - it’s a critical step for ensuring your AI products perform reliably in production. Without regular evaluations, you risk unseen quality issues caused by model provider updates, prompt changes, or shifts in your retrieval data.
An effective CI/CD strategy uses a layered evaluation process to catch problems at every stage. Here’s how it works:
-
Deterministic checks handle straightforward tasks like formatting errors.
-
Heuristic scoring quickly and affordably verifies semantic meaning.
-
Model-based evaluations dive deeper, assessing subjective factors like tone and helpfulness.
-
Human review tackles high-stakes decisions where automation isn’t enough.
Each layer addresses specific challenges, creating a system that identifies and resolves issues before they make it to production.
By using data-driven debugging, teams can pinpoint the root cause of problems - whether it’s the prompt, retrieval step, or model itself. This approach is particularly crucial in industries like healthcare and finance, where errors like toxicity, prompt injection, or PII leaks can lead to serious consequences and compliance risks.
Successful teams view their evaluation pipelines as dynamic systems. They update golden datasets with real-world feedback, prioritize resources based on risk levels, and define clear responsibilities across engineering, product, and domain experts. Tools like Latitude streamline this process, offering a centralized platform to monitor model behavior, gather feedback, run evaluations, and continuously improve - all in one place.
FAQs
What should my first “golden dataset” include?
Your initial “golden dataset” should consist of thoughtfully chosen inputs and expected outputs that address key test cases, edge scenarios, and the behaviors you want your prompt to exhibit. This dataset serves as a benchmark, helping you identify regressions and ensure consistent performance over time.
How do I pick pass/fail thresholds for LLM evals?
When establishing pass/fail thresholds for evaluating large language models (LLMs), it’s essential to define criteria that align closely with your specific use case. These criteria might include factors like accuracy , safety , or relevance.
Start by analyzing historical data or existing benchmarks to pinpoint cutoff points that clearly separate acceptable outputs from unacceptable ones. This helps ensure your thresholds are both practical and grounded in real-world expectations.
For more nuanced decision-making, consider blending deterministic rules (like hard limits) with probabilistic assessments. This approach allows you to account for varying levels of uncertainty in model outputs.
Ultimately, your thresholds should reflect the purpose of your model, your tolerance for risk, and its performance data. As you continue to evaluate and gather insights, don’t hesitate to adjust these thresholds to improve alignment with your evolving needs.
What should run in CI vs production monitoring?
In continuous integration (CI), automated evaluations play a critical role in catching regressions early. They test aspects like output quality, safety, accuracy, and performance using predefined datasets. This helps ensure that any changes made don’t compromise the model’s quality before it’s deployed.
On the other hand, production monitoring focuses on tracking live metrics such as response quality, latency, safety, and anomalies. By identifying issues like hallucinations or performance drops, it helps maintain the model’s reliability in real-world environments. Real-time observability and feedback loops are key to sustaining consistent performance once the model is live.