

Releasing updates to LLM-powered products can introduce subtle issues that degrade quality over time. Automated regression testing helps catch these problems before they impact users.
Here’s what you need to know:
-
Why it matters : LLMs are non-deterministic, meaning outputs vary even with the same input. Traditional tests can’t handle this complexity, but semantic evaluations can identify up to 85% of issues.
-
Risks : 65% of LLM applications fail in production within 90 days due to insufficient testing. Silent failures from model updates, prompt tweaks, or retrieval changes are common.
-
Solution : Automated regression pipelines, like those used by Notion, can boost issue resolution rates by 10x, from 3 fixes/day to 30.
-
Key components :
-
Golden Datasets : Curated examples to test for regressions.
-
Evaluation Metrics : Focus on correctness, faithfulness, safety, style, and performance.
-
Tools : Platforms like Langfuse, LangSmith, and Braintrust integrate testing and observability to bridge pre-deployment checks with live monitoring.
-
-
Challenges : Non-determinism in LLM outputs requires statistical methods, version control for prompts and datasets, and layered evaluations (e.g., programmatic checks, LLM judges, human review).
Automated regression testing ensures that updates don’t compromise quality, combining offline tests and live monitoring for continuous improvement.
Foundations of LLM Regression Testing
Regression testing plays a critical role in ensuring production-level stability, especially for large language models (LLMs). To make it effective, you need to establish clear quality benchmarks and build robust datasets.
Defining Quality and Regression for LLMs
To measure quality, start by aligning your product goals with quantifiable metrics. For LLMs, quality often falls into these categories:
-
Task correctness : Does the model achieve its intended goal?
-
Faithfulness : Are the claims grounded in the provided context?
-
Safety : Does the output comply with policy guidelines?
-
Style : Does it align with the brand’s tone and voice?
-
Operational performance : How does it perform in terms of latency and token usage?
Once these dimensions are identified, set clear thresholds for regression. For example, a 3% drop in accuracy or a 5% decrease in tone consistency can trigger a warning or block a merge in CI/CD pipelines. Without these hard metrics, regression risks becoming subjective and harder to address.
“LLM evaluation isn’t about finding a single ‘accuracy’ number. It’s about measuring multiple quality dimensions - correctness, tone, safety, completeness - and tracking each one over time.” - MachineLearningPlus
With these metrics defined, the next step is to capture them in a reliable dataset.
Building and Maintaining Golden Datasets
A golden dataset is a carefully curated collection of inputs paired with expected outputs, complete with a defined schema and changelog. It serves as the backbone for your regression testing.
Start small - around 25–50 cases - to catch early failures. Over time, expand this to 200–500 rows as you identify more failure scenarios in production. A strong dataset should include:
-
Normal inputs : Standard use cases or “happy path” scenarios.
-
Edge cases : Inputs that test the boundaries of expected behavior.
-
Adversarial inputs : Examples like jailbreak attempts designed to test robustness.
-
Off-topic requests : Inputs the system should appropriately decline.
To maintain the dataset’s reliability, follow two key rules. First, version your datasets along with prompts and code so you can reproduce past evaluations precisely. Second, conduct quarterly reviews to remove outdated rows or those that no longer align with the current product.
Evaluation Strategies and Metrics
To ensure comprehensive testing, use multiple evaluation methods, each suited to specific quality checks:
| Evaluator Type | Best For | Trade-off |
|---|---|---|
| Programmatic/Regex | Format validation, JSON structure, PII detection | Fast and cost-effective, but lacks nuance |
| Semantic Similarity | Detecting meaning shifts or paraphrasing | More flexible than exact matching, but can miss small factual errors |
| LLM-as-a-Judge | Assessing tone, safety, and open-ended tasks | Provides human-like judgment but is slower and more expensive |
| Human Review | High-stakes or subjective quality checks | Most accurate but not scalable |
For retrieval-augmented generation (RAG) systems, include the RAG Triad in your evaluations:
-
Context relevance : Is the retrieved document relevant to the query?
-
Faithfulness : Is the response grounded in the retrieved context, avoiding hallucinations?
-
Answer relevance : Does the response directly address the user’s question?
Additional techniques can enhance consistency. For example, when using LLM-as-a-Judge , ask the model to generate chain-of-thought reasoning before assigning a score. This approach makes the results more consistent and easier to audit. Another effective method is pairwise preference judging , where the model compares a new output against a baseline. Relative comparisons often yield more stable results than absolute scores.
Designing Automated Regression Testing Pipelines
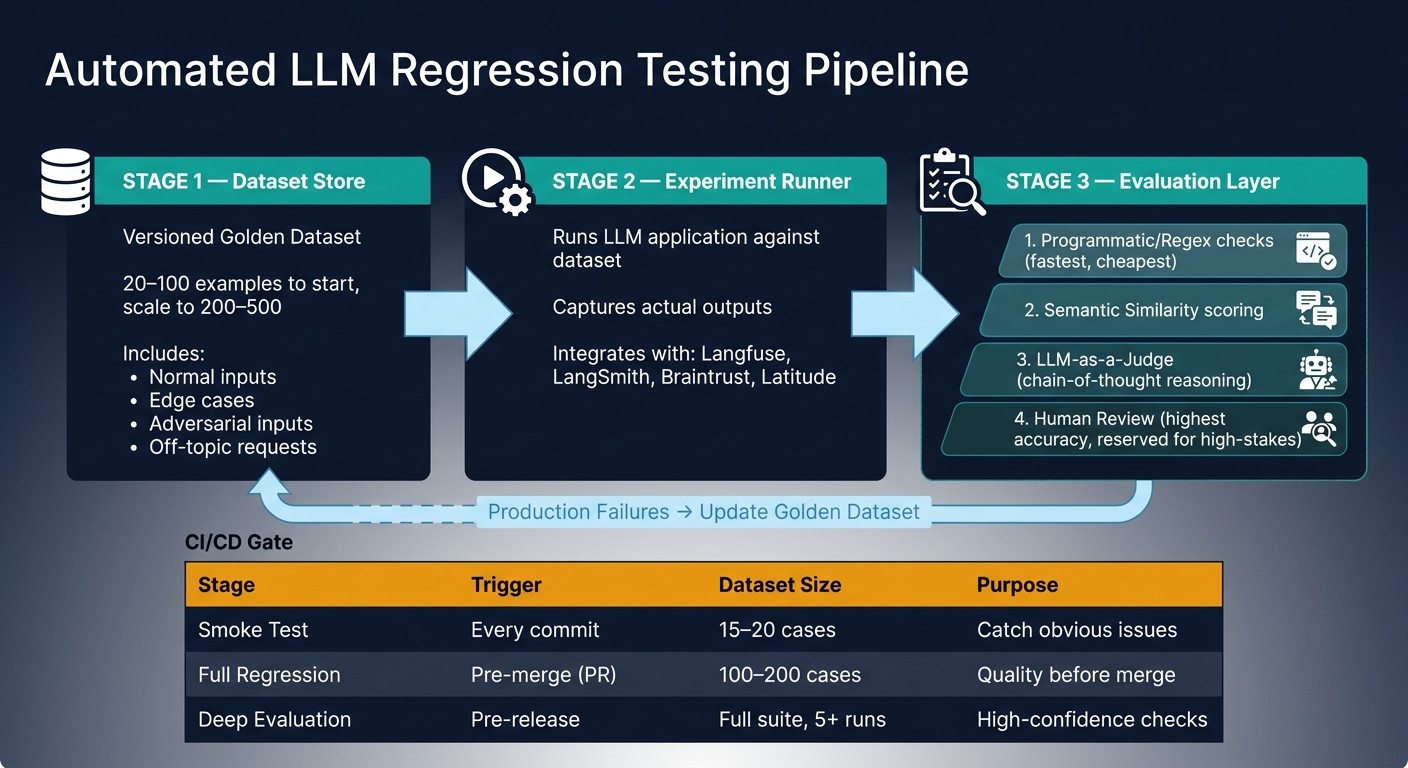
Automated LLM Regression Testing Pipeline: Key Steps & Components
Once you’ve established a solid golden dataset and clear evaluation metrics, the next step is to design an automated testing pipeline. This pipeline ensures that any regressions in your system are identified and addressed before they impact users.
Core Components of a Regression Pipeline
A regression pipeline typically includes three essential parts: a dataset store , an experiment runner , and an evaluation layer.
-
Dataset Store : This is where your versioned golden dataset resides. It contains the inputs, expected outputs, and metadata you’ve prepared earlier.
-
Experiment Runner : This component runs your LLM application against the dataset and captures its actual outputs.
-
Evaluation Layer : Here, the outputs are scored using a combination of programmatic checks, semantic evaluations, and methods like LLM-as-a-Judge.
Several tools can help streamline these processes:
-
Langfuse and LangSmith : These platforms support trace logging and experiment running, allowing for side-by-side variant comparisons.
-
Braintrust : Offers an all-in-one solution for managing datasets, prototyping in a playground environment, and scoring in real-time production scenarios.
-
Helicone: Focuses on observability and cost tracking, helping monitor token usage during evaluations.
-
Latitude: Automatically generates evaluations from real-world production issues and tracks failure patterns, ensuring your pipeline reflects actual user behavior.
By integrating offline test results with live production data, these tools help bridge the gap between pre-deployment testing and ongoing monitoring.
Integrating Regression Testing into CI/CD
To balance speed and thoroughness, a tiered gate system works well for regression testing:
| Stage | Trigger | Dataset Size | Purpose |
|---|---|---|---|
| Smoke Test | Every commit | 15–20 cases | Quickly catch obvious issues |
| Full Regression | Pre-merge (pull request) | 100–200 cases | Ensure quality before merging |
| Deep Evaluation | Pre-release | Full suite, 5+ runs per case | High-confidence final checks |
You can integrate these stages into GitHub Actions or GitLab CI by making API calls to your evaluation platform as part of the pipeline. It’s crucial to maintain environment parity - the metrics and traces used in CI/CD should align with those used in production monitoring.
Handling Non-Determinism in LLM Testing
LLM outputs can vary, even with identical prompts. This non-determinism can lead to false alarms if you’re relying on simple pass/fail checks. To tackle this, statistical methods are essential.
-
Run Tests Multiple Times : Execute each test case at least three times, ideally five, and focus on confidence intervals rather than single scores.
-
Establish a Baseline : Determine your system’s noise floor by running the evaluation suite 5–10 times on an unchanged system. This helps calculate the standard deviation of scores and differentiate true regressions from natural fluctuations.
Additional measures can further enhance reliability:
-
Pin Judge Models : Use a specific version of your judge model (e.g.,
gpt-4o-2024-05-13) to avoid unexpected changes from provider updates. -
Flag Unstable Test Cases : Mark cases with high variability as “unstable” and assign them less weight in overall scoring.
As one engineering team from Particula Tech noted:
“The teams that catch regressions before users do aren’t running better tools, they’re running straightforward LLM-as-a-judge patterns with statistical rigor.” - Particula Tech
Tools and Platforms for Regression Testing
Evaluation and Testing Frameworks
The rapid evolution of open-source tools has given teams powerful options for creating CI/CD quality gates without the need for heavy infrastructure. Take DeepEval, for example. This pytest-friendly tool comes with over 14 built-in metrics, supports custom natural-language rubrics through G-Eval, and integrates directly with GitHub Actions using a straightforward command (deepeval test run). As of early 2026, it has garnered around 8,000 stars on GitHub. On the other hand, RAGAS - boasting about 10,000 stars - specializes in evaluating RAG pipelines using its “RAG Triad” metrics: Faithfulness, Answer Relevancy, Context Precision, and Context Recall. Notably, it doesn’t require ground-truth labels, making it a flexible option.
For teams juggling multiple models, promptfoo stands out. It uses YAML-driven configurations to test combinations of prompts and models side-by-side. Plus, it includes a red-teaming suite with over 500 adversarial vectors to test vulnerabilities like prompt injection and PII extraction. Combining lightweight CI/CD frameworks like these with strong annotation platforms can provide a full picture of regression tracking.
“The best eval tool is one your stack can actually reach.” - Inference Research
While these frameworks simplify testing, observability platforms play a key role in refining regression suites using production data.
LLM Observability Platforms
Observability platforms extend your testing capabilities by analyzing real-world production data. LangSmith offers a “Comparison View” tailored for regression testing, making it easy to set baseline runs and quickly spot improvements or issues. Its seamless integration with LangChain and LangGraph makes it an ideal choice for teams in that ecosystem. The platform also includes a free tier with up to 5,000 traces per month.
For teams needing scalability, Langfuse provides an open-source, OpenTelemetry-native solution. It handles more than 10 billion observations monthly and is used by 19 of the Fortune 50 companies. Canva’s AI team, for instance, uses Langfuse for hierarchical traces and evaluation features to monitor their generative design tools in production. The free tier covers 50,000 observations per month, and self-hosting is available for free.
Latitude approaches observability differently with its “Reliability Loop.” This feature captures production traffic, clusters similar failures into issues, and automatically generates regression tests from those issues. In 2026, Boldspace leveraged Latitude to boost a key quality metric by 56% and doubled conversion rates from 4% to 8% for AI-assisted campaigns.
Finally, Braintrust focuses on experiment tracking and annotation. It has helped teams like Notion’s product group increase their issue-resolution rate from 3 fixes per day to 30 after adoption.
| Platform | Primary Strength | Free Tier | Best For |
|---|---|---|---|
| LangSmith | Regression comparison view | 5,000 traces/month | LangChain/LangGraph teams |
| Langfuse | Open-source, OpenTelemetry scale | 50,000 observations/month | Self-hosted setups, data residency |
| Braintrust | Experiment tracking & annotation | 1 million trace spans/month | Enterprise CI/CD gating |
| Latitude | Auto-generated evals from production | 5,000 traces/month | Connecting production to evals |
Incorporating these platforms into your regression pipeline doesn’t just catch issues early - it ensures your testing evolves based on real-world data.
Connecting Tooling to Workflow Orchestration
After choosing a platform, the next step is to integrate its SDK into your CI/CD pipeline. Most of these platforms offer Python or TypeScript SDKs, making integration with GitHub Actions straightforward. Use evaluation API calls to set pre-merge gates, ensuring builds fail if scores dip below a defined threshold (e.g., 0.7).
Additionally, schedule periodic jobs using tools like Airflow to monitor and address gradual quality drift in production.
“One pattern I noticed is that great AI researchers are willing to manually inspect lots of data. And more than that, they build infrastructure that allows them to manually inspect data quickly.” - Jason Wei, OpenAI
Running and Scaling Regression Testing in Production
Continuous Evaluation and Feedback Loops
Offline testing is great for catching issues before deployment, but it can’t predict every query your users might send. That’s why smart teams pair pre-deployment checks with online evaluations by running tests asynchronously on a small slice of live production traffic. A good starting point is sampling 5% of live traffic - this keeps costs manageable while helping you spot shifts that your fixed Golden Dataset might miss.
To keep your regression tests aligned with real-world behavior, create a feedback loop. Add production failures immediately to your Golden Dataset. This way, your regression tests evolve with actual user interactions, capturing new failure modes and improving future evaluations. Tools like Latitude make this easier by clustering production failures into trackable issues and automatically generating new tests from them.
Next, let’s dive into strategies for tackling gradual quality degradation through drift management.
Managing Prompt and Model Drift
Over time, both prompt drift and model drift can erode the quality of your large language model (LLM). Prompt drift happens when small wording changes unintentionally alter the model’s behavior. Model drift occurs when an upstream provider updates the model, causing your existing prompts to perform differently.
Take CallSphere’s experience in April 2026 as an example. Their team noticed an 11% drop in booking revenue over a week. The culprit? A single prompt edit that changed “you are a helpful assistant” to “you are a helpful, concise assistant.” The addition of “concise” led the model to skip booking confirmations entirely. To prevent issues like this, they built a 1,200-row regression suite to catch silent failures like these.
“A regression in agent-land is a statistical claim, not a binary one.” - CallSphere Blog
To combat drift, version your prompts, evaluators, and thresholds just like you version your code. Instead of relying solely on absolute scores, use semantic diffing - comparing new outputs with a baseline. This approach often catches subtle quality declines that aggregate metrics might miss. And for comparing prompt versions, use the Wilcoxon signed-rank test instead of a t-test, as LLM scores rarely follow a normal distribution. These steps build on earlier evaluation strategies to ensure statistical soundness.
Governance and Cost Trade-offs
As you scale, managing evaluation costs becomes essential. Running expensive LLM-based checks on every output isn’t practical. Instead, use a layered evaluation system:
-
Start with free, deterministic checks like regex or JSON schema validation.
-
Move to heuristic scoring for intermediate evaluations.
-
Reserve LLM judges or human reviewers for complex, uncertain, or high-stakes outputs.
For example, running a 700-row evaluation suite costs about $4.20 in OpenAI credits and takes 6 minutes. While this is fine for merge gates, it’s too costly for continuous evaluation of all production traffic.
Human oversight should also be tailored to the risk level of the task. Here’s a framework to guide reviewer requirements:
| Tier | Risk Level | Reviewer Requirement | Example Use Case | SLA |
|---|---|---|---|---|
| T0 | Low | 0 (Fully Automated) | Simple summarization, low-risk Q&A | Instant |
| T1 | Medium | 1 Human Reviewer | General customer support responses | < 4 hours |
| T2 | High | 2 Independent Reviewers | Legal, financial, or medical advice | < 2 hours |
| T3 | Critical | Senior SME | Safety incidents, regulatory compliance | Immediate |
For safety and compliance, always run 100% of production traffic through deterministic checks like PII detection, toxicity checks, and prompt injection scans. These checks are low-cost but critical - missing even one incident in these areas can have serious consequences. Save sampled evaluations for semantic quality metrics where the cost-to-benefit ratio makes sense.
Conclusion and Implementation Checklist
Key Steps for Setting Up a Regression Pipeline
To build an effective regression pipeline, there are five main steps to focus on:
-
Start by creating a Golden Dataset with 20–100 examples that reflect real user intents, edge cases, and negative examples, such as hallucinations. This dataset acts as the foundation for your testing process.
-
Move on to defining specific metrics and rubrics. Avoid vague goals and instead aim for measurable criteria, like ensuring outputs “cite sources from provided context.”
-
Introduce layered evaluation to your process. Begin with deterministic checks (like JSON schema or regex), then use heuristic scoring, and finally, reserve LLM-as-a-judge for more nuanced or complex outputs.
-
Integrate quality gates into your CI/CD pipeline. Tools like GitHub Actions can help block deployments when outputs fall below defined thresholds. Use a smoke test with 20–30 critical cases for quick feedback during pull requests, while running full test suites nightly.
-
Finally, close the feedback loop by continuously updating your Golden Dataset with failures from production. Platforms like Latitude simplify this by clustering production failures and generating evaluations from them.
Checklist for US-Based Engineering Teams
This checklist summarizes the core steps to ensure thorough testing and continuous improvement in your regression pipeline:
-
Golden Dataset : Include 20–100 examples that address real user intents, edge cases, and known failure modes.
-
Metrics defined : Establish specific rubrics for quality dimensions like correctness, tone, safety, and completeness.
-
Layered evaluators : Implement a progression from deterministic checks to heuristic scoring, LLM-as-a-judge, and human review.
-
Temperature set to 0 : Use a temperature of 0 for both the tested model and any LLM judge to ensure consistent results.
-
Cross-family judge : Use a different model family (e.g., Claude evaluating GPT-4 outputs) to avoid bias.
-
CI/CD gates : Set up evaluations in GitHub Actions (or similar) with strict score thresholds.
-
Smoke test suite : Run 20–30 critical test cases for quick feedback, complemented by full test suites during nightly runs.
-
Caching implemented : Cache unchanged test cases to save on API costs.
-
Versioning in place : Track prompts, datasets, and evaluators like source code for better organization.
-
Drift alerts configured : Enable alerts to monitor if daily average scores drop by more than 1% over a rolling window.
-
Statistical testing : Use the Wilcoxon signed-rank test for comparing variations in prompts.
-
Production feedback loop : Automatically add new production failures to the Golden Dataset for continuous refinement.
-
Governance tiers defined : Map human review requirements to risk levels (T0–T3).
This checklist ensures your team stays on track with robust testing practices and keeps your pipeline aligned with real-world use cases.
FAQs
What’s the minimum “golden dataset” I need to start?
The minimum “golden dataset” consists of a curated set of 30 to 200 input-output pairs. These pairs should highlight critical scenarios, edge cases, and key behaviors relevant to your application. By doing so, this dataset ensures coverage of essential functionalities while also helping to pinpoint potential failure points. Prioritize scenarios that align closely with your specific use case to make the dataset as impactful as possible.
How do I detect regressions when LLM outputs change run-to-run?
To spot regressions in outputs from large language models (LLMs), it’s essential to implement automated pipelines that consistently compare new results against established benchmarks. This process ensures that any unexpected changes in performance, accuracy, or behavior are caught early.
Here’s how you can stay on top of potential issues:
-
Layered Evaluation : Use multiple checks to assess outputs. These might include metrics for semantic similarity, correctness, and safety. Each layer adds a different perspective, giving you a well-rounded view of the model’s performance.
-
Automation Tools : Leverage tools that can monitor and score outputs automatically. They simplify the process of identifying deviations and allow you to address problems before they escalate.
-
“Before” and “After” Datasets : Create datasets with identical prompts to compare results over time. This makes it easier to spot shifts in tone, accuracy, or content.
-
CI/CD Integration : Incorporate these checks directly into your continuous integration/continuous deployment (CI/CD) pipeline. This ensures that every update to the model is tested for regressions before being deployed.
By setting up these systems, you can maintain the quality and reliability of your LLM outputs while streamlining the process of detecting and addressing regressions.
What tests should block a deploy vs just raise an alert?
In automated regression testing for large language models (LLMs), deployment-blocking tests focus on critical areas such as safety, correctness, and reliability. These tests are designed to catch major issues, like unsafe content generation or significant factual inaccuracies, that could severely impact the model’s performance or trustworthiness.
On the other hand, alert-only tests identify less critical concerns, such as minor changes in tone or slight shifts in meaning. These issues are flagged for later review rather than halting deployment. This dual approach helps balance the need for safety and accuracy with the flexibility required for continuous development.