

Pruning large language models (LLMs) is a game-changer for running AI on edge devices like smartphones or IoT hardware. These models are too large and power-hungry for such devices without optimization. Pruning solves this by removing less critical parts of the model, reducing size, improving speed, and cutting energy use.
Here’s what you need to know:
-
Structured Pruning : Removes entire components (e.g., layers, neurons) for simpler deployment on standard hardware. Balances speed and accuracy but may lose more precision compared to finer methods.
-
Unstructured Pruning : Targets individual weights for maximum size reduction but requires specialized hardware for speed gains.
-
Magnitude-Based Pruning : Eliminates low-value weights, offering flexibility in compression but may introduce biases if not applied carefully.
-
Runtime-Adaptive Pruning (RAP) : Dynamically adjusts pruning during inference based on available resources, ideal for devices with fluctuating memory or workloads.
Each method has trade-offs in accuracy, hardware compatibility, and efficiency. Structured pruning is great for general edge devices, while unstructured pruning suits tasks needing high compression. RAP shines in dynamic environments with tight resource constraints.
Key Insight : Choose your pruning strategy based on your hardware and performance needs. Combining pruning with techniques like quantization and knowledge distillation can further optimize LLMs for edge deployment.
1. Structured Pruning
Structured pruning focuses on removing entire architectural components - like attention heads, channels, or even full layers - instead of individual weights. This approach creates a predictable sparsity pattern, making it easier to work with standard hardware accelerators and ensuring smooth deployment on edge devices. As researchers Guangxin Wu et al. explain:
“Structured pruning… eliminates entire architectural components and maintains compatibility with standard hardware accelerators”.
The main challenge is deciding which components are essential. Techniques like SlimLLM prioritize entire sub-modules based on their contribution to the model’s output, rather than examining individual parameters. For example, in May 2025, researchers Jialong Guo, Xinghao Chen, Yehui Tang, and Yunhe Wang applied SlimLLM to the LLaMA-7B model. They achieved a 20% pruning ratio while preserving 98.7% of the original model’s performance on commonsense reasoning tasks. Their method included Pearson similarity for head pruning and a linear regression strategy to quickly recover performance. Key benefits of structured pruning include reductions in model size, faster inference speeds, strong accuracy retention, and compatibility with standard hardware.
Model Size Reduction
By removing entire components, structured pruning significantly compresses models. SlimLLM demonstrated that pruning 20% of the model’s structure could still retain 98.7% of its performance. This compression directly reduces memory requirements, which is crucial for devices with limited storage or RAM.
Inference Speed Gains
Depth pruning - removing layers - often leads to noticeable latency improvements compared to width pruning, even when the parameter count remains the same. In October 2025, NVIDIA researchers Max Xu and Keval Morabia used the TensorRT Model Optimizer to prune a Qwen3-8B model down to 6B parameters. The result? A 30% speed increase compared to a standard 4B model, with the pruned model achieving an MMLU score of 72.5 versus the 4B model’s 70.0.
Accuracy Retention
Structured pruning strikes a balance between reducing parameters and maintaining accuracy. Width pruning - removing neurons or attention heads - tends to preserve accuracy better than depth pruning but offers less dramatic latency improvements. As the NVIDIA team noted:
“width pruning typically achieves better accuracy than depth pruning, though depth pruning often reduces inference latency more at the same number of parameters”.
This trade-off requires careful consideration based on the specific goals of a deployment.
Hardware Suitability
Structured pruning also ensures models remain compatible with existing GPUs and edge processors, eliminating the need for specialized sparse computation kernels. Researcher Jialong Guo highlights:
“structured pruning… results in a more regular and hardware-friendly sparsity pattern. For its better compatibility with existing hardware architectures, structured pruning has attracted much attention”.
This compatibility is particularly important for organizations that rely on standard hardware, enabling them to deploy optimized models on edge devices without sacrificing privacy or efficiency.
2. Unstructured Pruning
Unstructured pruning takes a more granular approach by targeting individual weights, regardless of their position in the network. It focuses on parameters with the smallest values, setting them to zero, which results in a sparse weight matrix filled with zeros scattered throughout the model. Unlike structured pruning, which removes entire components for a more uniform sparsity, unstructured pruning offers finer control over compression at the cost of predictability.
This method can achieve much higher compression ratios compared to structured pruning, allowing for flexibility in meeting specific hardware constraints. However, as Nawaz Dhandala from OneUptime points out:
“Unstructured pruning removes individual weights regardless of their position in the network. This approach can achieve high compression ratios but results in sparse matrices that may not translate to actual speedups without specialized hardware”.
Model Size Reduction
Unstructured pruning is particularly effective at reducing the storage requirements of a model - an essential advantage for edge devices with limited flash storage. By eliminating individual weights, models can achieve greater compression while maintaining accuracy, even with significant parameter reduction. This makes it easier to deploy large language models on devices with tight memory constraints. However, these storage savings come with a trade-off: compatibility with standard hardware often becomes a challenge.
Hardware Suitability
One of the main limitations of unstructured pruning lies in its hardware demands. Unlike structured pruning, where the removed components create a predictable and regular structure, the irregular sparsity from unstructured pruning requires specialized computation frameworks to achieve latency improvements. Without tools like sparse matrix libraries or custom hardware - such as certain NPUs or FPGAs - these sparse models may not deliver actual speedups. As Sam Prakash Bheri from Towards AI explains:
“Unstructured Pruning focuses on removing individual weights or connections from the neural network resulting in sparse weight matrices. This technique does not preserve regular structure, which makes it difficult to realize computational speedups without specialized sparse matrix libraries or custom hardware”.
The irregular memory access patterns caused by unstructured sparsity can reduce efficiency on standard processors. Additionally, certain layers, like the first and last, are more sensitive to weight removal and should be pruned cautiously to avoid significant accuracy loss. To address this, weights should be pruned gradually, with fine-tuning after each step to allow the remaining parameters to adapt and compensate for the removed ones.
3. Magnitude-Based Pruning
Magnitude-based pruning builds on earlier pruning techniques by focusing on weight values to identify and eliminate unnecessary parameters. The method works by removing the smallest weights in a model, under the assumption that these weights have minimal impact on the model’s output. Essentially, low-value weights are set to zero, simplifying the model and making it more efficient for edge deployment. This approach capitalizes on a well-known characteristic of neural networks: they often contain more parameters than they actually need. As TechEon’s Senior Data Scientist explains:
“Many neural networks are over-parameterized. They contain redundant connections that can be removed without significantly impacting performance”.
Model Size Reduction
The extent to which a model’s size can be reduced depends on the desired sparsity level and whether weights are pruned individually or in groups. Structured pruning targets entire groups, such as neurons or attention heads, which can simplify hardware implementation. On the other hand, unstructured pruning introduces fine-grained sparsity by removing individual weights. Studies indicate that magnitude-based pruning can achieve up to 30% sparsity in simpler networks with little to no impact on accuracy. Networks with more redundant parameters generally handle higher sparsity levels without a noticeable drop in performance.
Hardware Suitability
The effectiveness of magnitude-based pruning on hardware depends heavily on how it’s applied. Unstructured pruning, while precise, creates irregular sparsity patterns that require specialized hardware or optimized libraries to fully realize performance gains. Standard CPUs and GPUs often struggle with these irregularities. In contrast, structured pruning - removing entire neurons or layers - offers better compatibility with conventional hardware setups. For example, slimming layers (width pruning) usually maintains model accuracy, while removing entire layers (depth pruning) can significantly cut inference time for the same parameter count. Up next, we’ll explore how runtime-adaptive methods push pruning efficiency even further.
4. Runtime-Adaptive Pruning (RAP)
Edge devices often face unpredictable resource availability, making it essential for models to adjust dynamically. That’s where Runtime-Adaptive Pruning (RAP) steps in. Unlike fixed compression strategies, RAP adjusts sparsity levels during inference based on real-time conditions. A reinforcement learning (RL) agent evaluates signals like input sequence length, batch size, and available memory, deciding in real time which components to keep or prune. This flexibility sets RAP apart from static pruning methods. Notably, edge devices can experience memory fluctuations of 5–10% due to competing applications and varying workloads.
Inference Speed Gains
RAP enhances inference by pruning both feed-forward weights and the KV cache in attention layers. This prevents out-of-memory errors that could otherwise disrupt the process. For instance, a Llama2-7B model processing 4,000 tokens at a batch size of 16 requires 32 GB of memory just for the KV cache - more than twice the 14 GB needed for static parameters. RAP’s pruning decisions are computed by a 2-layer MLP RL agent, which operates with negligible overhead.
This dynamic pruning not only speeds up inference but also ensures the model continues to perform effectively, even under resource constraints.
Accuracy Retention
RAP demonstrates impressive accuracy retention, even when operating under strict memory limits. For example, with an 80% memory budget, RAP achieved an average score of 57.08% on commonsense tasks using Llama2-7B, surpassing LLMPruner (48.63%) and ShortGPT (47.53%). Similarly, with Llama3-8B, RAP maintained a performance of 59.77% under the same budget, compared to LLMPruner’s 45.37%. This is achieved through Greedy Sequential Importance analysis, which removes blocks with minimal impact on performance while considering inter-layer dependencies - something static methods often overlook.
Researchers from the University of Macau noted:
“RAP outperforms state-of-the-art baselines, marking the first time to jointly consider model weights and KV-cache on the fly”.
Hardware Suitability
RAP is particularly effective on GPU-accelerated edge devices, such as the NVIDIA Jetson Orin or new GenAI NPUs tailored for generative AI workloads. Its controller requires less than 10 MB of memory overhead and adds only 0.1% FLOPs overhead, making it an efficient choice for resource-limited environments. To deploy RAP, you’ll need sensors that monitor sequence length, batch details, and real-time memory availability, enabling the pruning agent to make informed decisions. When memory is abundant, the system retains most components; when resources are tight, it prunes more aggressively.
This adaptive approach aligns perfectly with the goal of optimizing LLMs for edge deployment, ensuring they can handle real-world resource constraints effectively.
Advantages and Disadvantages
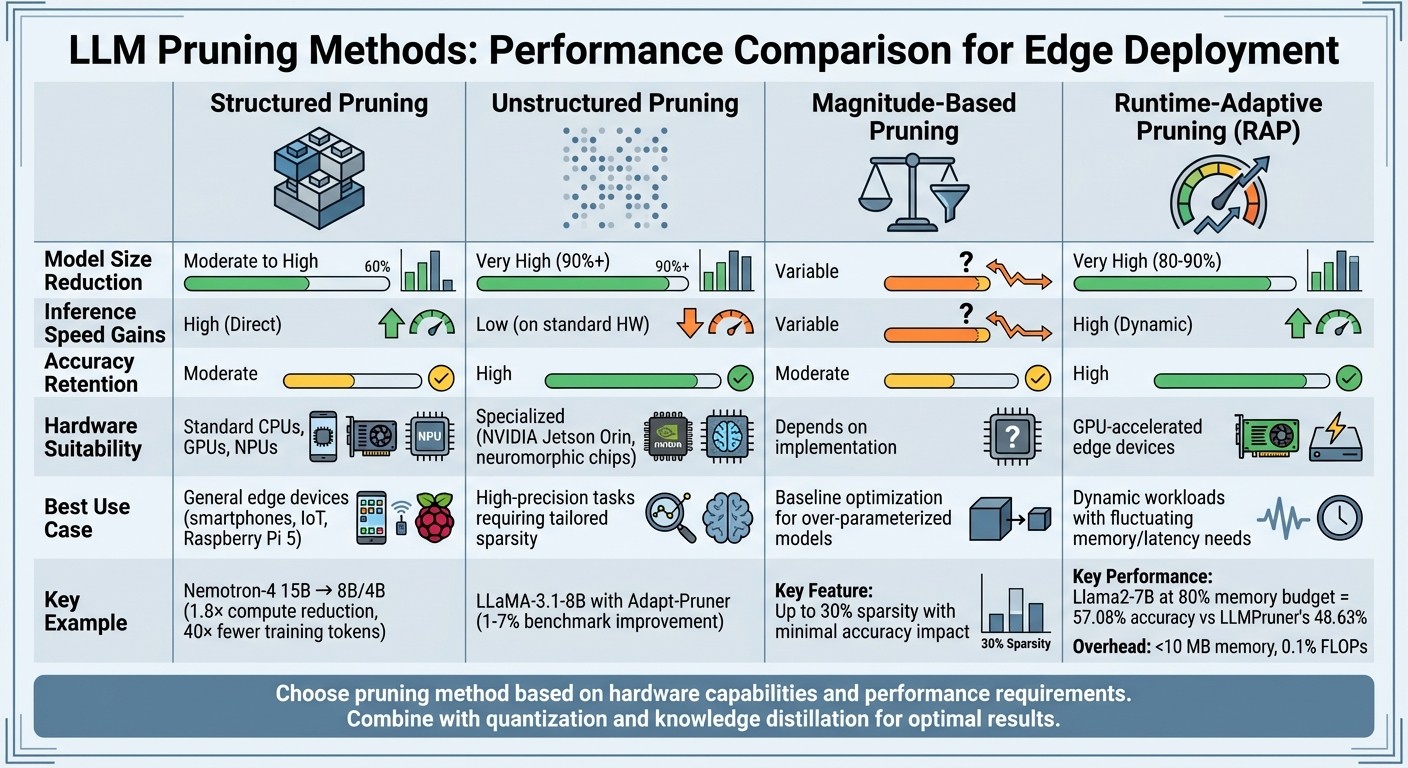
Comparison of LLM Pruning Methods for Edge Devices
Table 1 breaks down the core metrics for four pruning methods - Structured, Unstructured, Magnitude-Based, and Runtime-Adaptive - when applied to edge devices.
| Pruning Method | Model Size Reduction | Inference Speed Gains | Accuracy Retention | Hardware Suitability | Best Use Case Scenario |
|---|---|---|---|---|---|
| Structured | Moderate to High | High (Direct) | Moderate | Standard CPUs, GPUs, NPUs | General edge devices (smartphones, IoT, Raspberry Pi 5) |
| Unstructured | Very High (90%+) | Low (on standard HW) | High | Specialized (e.g., NVIDIA Jetson Orin, neuromorphic chips) | High-precision tasks requiring tailored sparsity |
| Magnitude-Based | Variable | Variable | Moderate | Depends on implementation | Baseline optimization for over-parameterized models |
| Runtime-Adaptive (RAP) | Very High (80–90%) | High (Dynamic) | High | GPU-accelerated edge devices | Dynamic workloads with fluctuating memory/latency needs |
Here’s a closer look at these methods and their practical applications, including the trade-offs involved.
Structured Pruning removes entire neurons or channels, creating smaller, dense models that work efficiently on standard hardware like smartphones or Raspberry Pi devices. For instance, in July 2024, NVIDIA researchers used structured pruning with knowledge distillation to shrink the Nemotron-4 15B model into 8B and 4B versions. This cut compute costs by 1.8× and reduced training tokens by 40×. However, because it eliminates entire components, structured pruning can have a more pronounced impact on accuracy compared to more granular methods.
Unstructured Pruning focuses on maximizing compression by zeroing out individual weights. While this achieves significant file size reductions, the benefits are hardware-dependent. Standard processors can’t automatically skip zero-valued weights, meaning latency improvements aren’t guaranteed. A notable example occurred in February 2025, when Rui Pan’s team applied the Adapt-Pruner technique to the LLaMA-3.1-8B model. Their approach improved commonsense benchmark scores by 1% to 7% without compromising efficiency.
Magnitude-Based Pruning is a straightforward method that removes weights with the smallest absolute values. While simple, it doubles as a regularizer, often improving a model’s generalization to new data. However, this method may unintentionally prune parameters critical to underrepresented subgroups, potentially leading to biases.
Runtime-Adaptive Pruning (RAP) adjusts pruning levels on the fly, optimizing performance based on available resources. This makes it ideal for environments where memory usage fluctuates by 5–10% due to competing workloads. RAP is particularly effective on GPU-accelerated edge devices, requiring less than 10 MB of additional memory and adding only 0.1% FLOPs overhead. It balances model size reduction with faster inference, adapting dynamically to changing conditions.
Understanding these trade-offs is key to selecting the right pruning method for deploying optimized LLMs on edge devices.
Conclusion
Structured pruning is a better fit for standard edge devices, while unstructured pruning works best with specialized hardware. The choice between these methods depends on your hardware’s capabilities and the need to maintain model accuracy. Devices like smartphones or Raspberry Pi 5 benefit from structured pruning, which produces smaller, dense models that run efficiently without requiring advanced hardware. On the other hand, unstructured pruning can achieve higher compression rates but needs devices equipped with sparse-matrix acceleration, such as those using NVIDIA Sparse Tensor Cores.
It’s also essential to understand your model’s architecture. For modern large language models (LLMs) like Llama 3.2, Mistral, or Qwen, pruning should be GLU-aware. For instance, ensuring symmetry in pruning between gate_proj and up_proj layers is critical to avoid model failures. A study on Llama 3.2-1B revealed that reducing MLP neurons by 40% caused only a 2% drop in comprehension accuracy but over a 50% decline in word prediction accuracy. This highlights how pruning impacts different tasks in varying ways.
Effective pruning often requires a multi-step optimization process. Start with pruning, follow it with knowledge distillation, and conclude with quantization. Adapt your strategy based on the device: aggressive TinyLLM techniques are ideal for ultra-low-power microcontrollers with less than 512 KB memory, while 4-bit quantization works well for devices like the Raspberry Pi 5, which has up to 8 GB of RAM.
Once you deploy optimized models, consistent monitoring is crucial. Pruned and quantized models, especially at 4-bit precision, can experience numerical drift, which may lead to instability. Tools like Latitude can help track model performance, gather expert feedback, and run evaluations to ensure your edge-deployed LLM remains reliable over time.
The best pruning strategy matches your hardware, respects the architecture of your model, and involves ongoing evaluation to maintain performance.
FAQs
How do I choose between structured, unstructured, and RAP pruning for my device?
Choosing the right pruning method depends on your device’s resources and performance objectives:
-
Structured pruning : This method eliminates entire neurons, filters, or layers, which makes it more compatible with hardware but could lead to a drop in accuracy.
-
Unstructured pruning : Instead of removing large chunks, it targets individual weights. This approach often preserves accuracy better but requires hardware capable of handling sparse matrices.
-
RAP pruning : A middle ground that balances sparsity and efficiency, tailored to suit your specific hardware and application requirements.
Will pruning actually speed up inference on CPUs/GPUs, or just shrink the model?
Pruning helps reduce the size of a model and speeds up its inference by cutting out redundant parameters. By doing this, it lowers the computational demand, making the model run more efficiently on both CPUs and GPUs. This approach improves resource usage without sacrificing the model’s core functionality.
How can I prevent accuracy drops or bias after pruning an LLM?
To reduce accuracy loss or bias when pruning a large language model (LLM), it’s essential to use importance-aware techniques. These involve redistributing the importance of parameters before pruning, ensuring that crucial components of the model remain intact. Approaches like learnable transformations or adaptive importance metrics can play a key role in preserving the model’s core functionality.
After pruning, post-pruning fine-tuning can help restore performance. This might include methods like training low-rank adapters or fine-tuning biases, which can help the model regain its reliability and effectiveness.