

Large Language Models (LLMs) are transforming education, but not all models are equally suited for every task. This article compares four leading LLMs - Claude, GPT-5, Llama 4, and Mistral - based on their performance in teaching, cost, scalability, and customization for educational use. Here’s a quick summary:
-
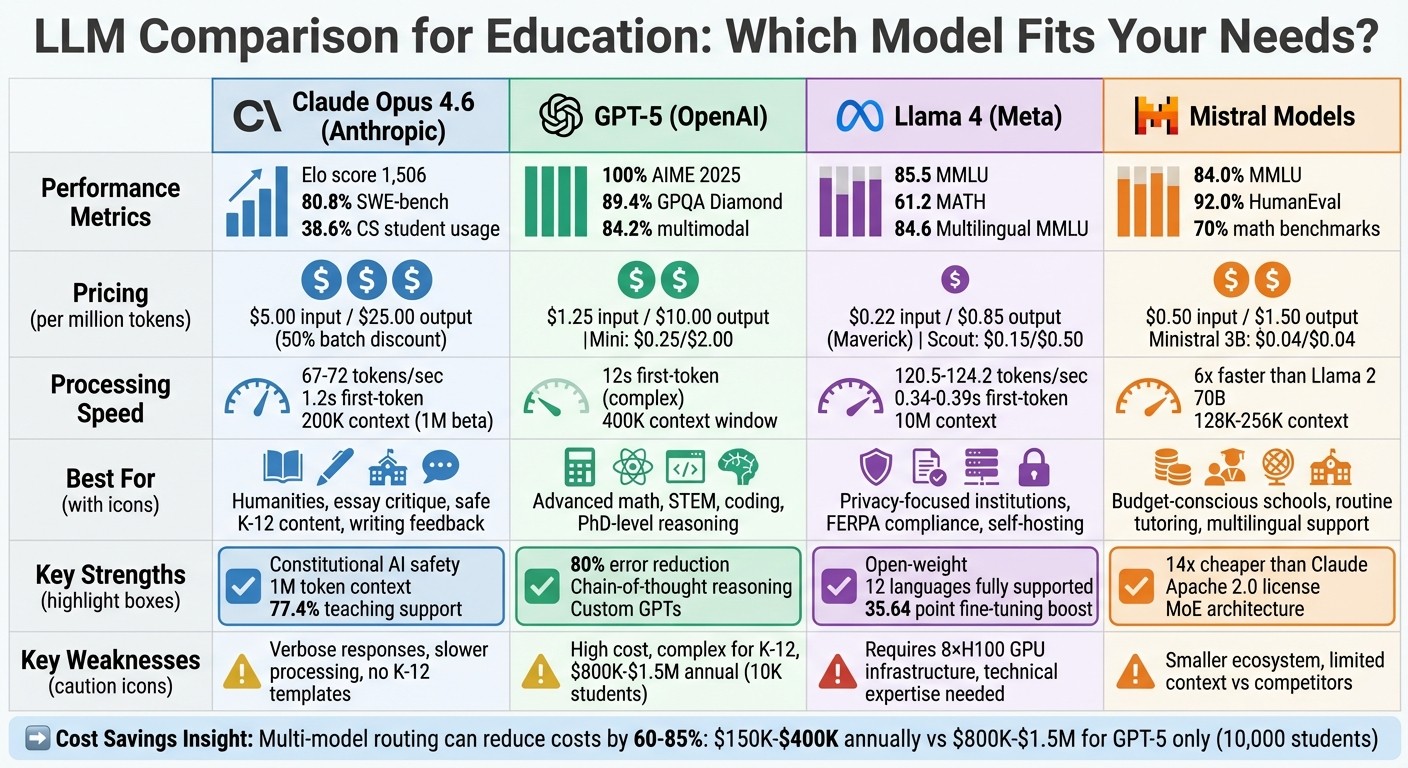
Claude Opus 4.6 : Best for safe and accurate content, excels in humanities and writing tasks, but slower and more verbose. Cost-efficient for batch tasks.
-
GPT-5 : Excels in STEM, advanced reasoning, and coding but is expensive and complex for younger students.
-
Llama 4 : Offers privacy and self-hosting, ideal for institutions needing data control but requires significant infrastructure.
-
Mistral Models : Affordable and efficient, great for routine tasks, but with smaller ecosystems and limited context windows.
Quick Comparison :
| Model | Strengths | Weaknesses | Best For |
|---|---|---|---|
| Claude Opus 4.6 | Writing feedback, safe content | Verbose, slower | Humanities, essay critique |
| GPT-5 | STEM, advanced reasoning | High cost, complex explanations | Advanced math, programming |
| Llama 4 | Privacy, self-hosting | High infrastructure needs | FERPA-compliant institutions |
| Mistral | Affordable, fast processing | Limited context, smaller ecosystem | Budget-conscious tutoring |
Each model has unique strengths, making a multi-model approach ideal for balancing cost and performance in education.
LLM Comparison for Education: Claude vs GPT-5 vs Llama 4 vs Mistral
1. Claude Family (Anthropic)
Anthropic’s Claude family has positioned itself as a strong option for educational use, particularly in settings where accuracy and safety are critical. Claude Opus 4.6 currently leads educational benchmark tests, boasting an Elo score of approximately 1,506 as of February 2026. Its “Constitutional AI” framework ensures content remains age-appropriate and safe - an essential feature for K–12 environments.
Educational Benchmark Performance
Claude Opus 4.6 shines in coding tasks, achieving an 80.8% success rate on SWE-bench Verified, a benchmark designed to test real GitHub bug resolution. It also performs well on PhD-level science benchmarks, consistently ranking among the top in bug detection rates. Educators primarily use Claude for tasks like curriculum design, academic research, and assessing student performance. Notably, Computer Science students account for 38.6% of the platform’s interactions.
Cost Efficiency
Claude operates on a three-tier pricing model based on task complexity. For Claude Opus 4.6, input tokens cost $5.00 per 1 million, while output tokens are priced at $25.00 per 1 million. More affordable options are available through the mid-tier Sonnet and the budget-friendly Haiku models. Teachers report saving an average of 5.9 hours per week using AI tools like Claude. For tasks such as code review, the return on investment can reach an impressive 19,000% compared to human labor costs. Additionally, batch processing for non-real-time tasks, such as bulk grading or content generation, qualifies for a 50% discount.
Latency and Scalability
Claude processes between 67 and 72 tokens per second, with an average time-to-first-token of 1.2 seconds. Its expansive context window - 200,000 tokens, with a 1-million-token beta - enables the analysis of entire textbooks or lengthy student portfolios in a single request, eliminating the need for complex chunking strategies.
Customization and Fine-Tuning
One of Claude’s standout features for education is its Artifacts tool. This allows educators to create functional resources - like chemistry simulations, automated grading rubrics, and interactive games - directly within the chat interface, without requiring advanced prompt engineering expertise. A faculty member from Northeastern University shared:
“AI is useful for giving students and me individualized, interactive learning experiences beyond what one instructor could provide”.
However, the platform does have some limitations. It lacks built-in K–12 curriculum templates and direct integration with gradebooks or systems like IEP/504 plans. Institutional deployments require enterprise agreements through “Claude for Education” or “Claude Campus”, which can add complexity to the procurement process. Despite these challenges, Claude is used in a support role for 77.4% of university teaching tasks, functioning as a collaborative tool rather than a fully automated solution.
Next, we’ll explore how GPT-5 tackles these educational challenges with its unique approach.
2. GPT-5 (OpenAI)
OpenAI’s GPT-5 introduces a chain-of-thought reasoning system that efficiently handles both simple and complex queries. Straightforward questions are answered quickly, while more challenging STEM problems are processed with deeper analysis. This makes GPT-5 especially effective in areas like advanced mathematics, physics, and computer science. Here’s a closer look at its performance and features.
Educational Benchmark Performance
GPT-5 Pro demonstrates impressive results in educational benchmarks:
-
AIME2025 Math Benchmark : Achieved a perfect 100% accuracy using Python tools and its “thinking mode” - a test designed to challenge elite high school mathematicians. Even without tools, it scored 94.6%.
-
PhD-Level Science Questions (GPQA Diamond) : Reached an 89.4% accuracy rate.
-
SWE-bench Verified (Coding Tasks) : Scored 74.9% on coding-related benchmarks.
-
Error Reduction : With thinking mode enabled, factual errors were reduced by 80% compared to its predecessor.
-
Multimodal Understanding : Scored 84.2% on benchmarks requiring analysis of diagrams, charts, and illustrations alongside text.
These results highlight GPT-5’s ability to excel across a range of academic challenges.
Cost Efficiency
GPT-5’s pricing reflects its advanced capabilities:
-
Standard Model : Costs $1.25 per million input tokens and $10.00 per million output tokens. For institutions serving 10,000 students, annual costs range from $800,000 to $1.5 million.
-
GPT-5 Mini : A lower-cost option at $0.25 per million input tokens and $2.00 per million output tokens , achieving 87% accuracy on extraction tasks.
Schools can reduce expenses by routing 80–90% of routine queries to GPT-5 Mini and reserving the full model for more complex tasks. This hybrid approach can cut costs by 60–80%. Additionally, the Batch API offers a 50% discount for tasks like grading or content generation that don’t require immediate responses.
Latency and Scalability
While GPT-5 delivers exceptional reasoning, it does come with a trade-off in processing speed:
-
Complex Tasks : The flagship model takes approximately 1,067 seconds to process 20 complex tasks, compared to 227 seconds for GPT-5 Mini.
-
Speed Improvements : The March 2026 GPT-5.2 update significantly improved performance, reducing the time-to-first-token for complex queries from 46 seconds to 12 seconds - a 74% improvement.
-
Context Window : With a 400,000-token context window, GPT-5 can analyze entire textbooks or semester-long student portfolios in a single request, maintaining nearly perfect recall accuracy across the entire input.
OpenAI describes the user experience as:
“less like ‘talking to AI’ and more like chatting with a helpful friend with PhD-level intelligence”.
Customization and Fine-Tuning
GPT-5 offers extensive customization options tailored to educational needs:
-
Custom GPTs : Educators can create specialized tools by uploading syllabi, rubrics, and lecture notes directly into the system, all without requiring coding skills.
-
Preset Personalities : Options like Cynic, Robot, Listener, and Nerd help align the AI’s communication style with various student demographics.
-
Privacy Features : For institutions prioritizing data security, GPT-oss - a 120-billion-parameter open-weight version under the Apache 2.0 license - supports on-premise deployment without per-token API costs. Granular memory controls also allow users to delete specific stored information, ensuring student privacy.
These features make GPT-5 a versatile tool for educators, combining advanced performance with cost-saving measures and robust customization options.
3. Llama 4
Meta’s Llama 4 family provides an open-weight architecture that institutions can self-host. This setup is particularly appealing for schools and universities that prioritize data privacy or wish to avoid recurring API fees. The family includes three variants: Scout for long-context tasks, Maverick for production use, and Behemoth for training smaller models. Its design balances performance and cost efficiency, as outlined below.
Educational Benchmark Performance
Llama 4 Maverick demonstrates strong results across various benchmarks. It scores 85.5 onMMLU and 61.2 on MATH , all while utilizing just 17 billion active parameters. For visual reasoning tasks - essential for grading diagrams or analyzing charts - it achieves impressive scores: 90.0 onChartQA and 94.4 onDocVQA.
In multilingual scenarios, the model shines with an 84.6 on Multilingual MMLU , surpassing GPT-4o’s 81.5. It also scores 69.8 on GPQA Diamond for STEM applications, outperforming GPT-4o by more than 16 points. Research further shows that fine-tuning for specific grade levels boosts alignment by 35.64 points compared to standard prompting.
Cost Efficiency
Llama 4 uses a Mixture-of-Experts architecture, activating only 17 billion out of 400 billion parameters, which significantly reduces computational costs [33,34]. The API pricing for Maverick is $0.22 per million input tokens and $0.85 per million output tokens , making it about 86% cheaper for input and 94% cheaper for output compared to Gemini 2.5 Pro [36,38].
Scout, the more budget-friendly option, comes in at $0.15 per million input tokens and $0.50 per million output tokens. For self-hosted setups, Scout can run on a single NVIDIA H100 GPU with Int4 quantization, while Maverick requires an 8×H100 node [33,37]. The open-weight license means institutions can use the model indefinitely after the initial hardware investment, avoiding ongoing API fees.
Latency and Scalability
Scout delivers 120.5 tokens per second with a 0.39-second time-to-first-token , while Maverick processes 124.2 tokens per second with a 0.34-second latency. Maverick also supports a 10-million-token context window , far exceeding Claude 3.7 Sonnet’s 200,000 tokens and Gemini 2.5 Pro’s 1 million tokens [36,38]. This larger context window allows institutions to analyze entire textbooks, year-long student portfolios, or extensive research databases in a single prompt.
“a best-in-class performance to cost ratio with an experimental chat version scoring ELO of 1417 on LMArena” - Meta AI
Customization and Fine-Tuning
The open-weight design offers educators full control over customization. Schools can fine-tune these models on proprietary curricula and rubrics without relying on external APIs [39,40]. Llama 4 Maverick supports 12 languages fully and has capabilities across more than 200 languages, making it ideal for diverse student populations [40,41].
For privacy-sensitive applications, institutions can use Supervised Fine-Tuning and Direct Preference Optimization to align the model with specific teaching styles while keeping data secure [39,40]. Built-in safety tools like Llama Guard and Prompt Guard automatically detect and flag harmful inputs or outputs. These features empower educators to adapt the model to their unique curricular needs and student requirements.
4. Mistral Reasoning Models
When it comes to educational applications, Mistral models strike an impressive balance between performance and affordability. Thanks to Mistral AI’s MoE (Mixture of Experts) design, only a portion of the model’s parameters are activated during use - like Mixtral 8x7B, which utilizes 12.9 billion parameters out of its total 46.7 billion. This approach delivers high-level performance while maintaining the efficiency of smaller models, making it a practical choice for budget-conscious educational institutions.
Educational Benchmark Performance
The Mathstral 7B model is a standout for STEM-focused tasks, consistently outperforming Llama 3 8B on key math benchmarks such as GSM8K, MathOdyssey, and GRE Math. It manages to achieve about 70% on MMLU, all while maintaining its compact 7-billion-parameter size. On the other hand, Mistral Large 2 matches the performance of much larger models like Llama 3.1 405B in areas like code generation and mathematics, despite being only a third of its size at 123 billion parameters. It scores an impressive 84.0% on MMLU (5-shot) and 92.0% on HumanEval. The latest addition, Mistral Small 4 , released in March 2026, combines instruct, reasoning, and coding capabilities into a single efficient model. These results highlight the models’ ability to deliver strong performance without breaking the bank.
Cost Efficiency
Mistral’s pricing model makes it a top choice for large-scale educational use. For instance, Mistral Large 3 is priced at $0.50 per million input tokens and $1.50 per million output tokens, which is roughly 2.5 times cheaper for input and 10 times cheaper for output compared to competitors. In a competitive three-round refinement test, Mistral Large 3 cost just $0.0233 compared to Claude Opus 4.5’s $0.3160 - a 14-fold difference - while earning a higher quality score of 9.4 out of 10 versus Claude’s 8.1. For more routine tasks like tutoring, Ministral 3B offers even lower costs at $0.04 per million tokens for both input and output.
“Mistral matches Claude’s depth at 14x lower cost.” - AI Crucible
Many of Mistral’s core models, including Mistral 7B, Mixtral 8x7B, and Mathstral 7B, come with an Apache 2.0 license. This allows schools to self-host the models without paying ongoing API fees. Additionally, Mistral 7B can run on consumer-grade hardware with just 8 GB of VRAM, delivering tokens 34% faster than Llama 3.1 8B. These features make it appealing for institutions that value data control and affordability.
Latency and Scalability
Speed and scalability are key strengths of Mistral models. Mixtral 8x7B processes inference six times faster than Llama 2 70B, and Mistral 7B generates responses 34% faster than Llama 3.1 8B. Mistral Large 3 supports a 256,000-token context window, while Mistral Large 2 offers a 128,000-token context window. While these are smaller than GPT-5.2’s 400,000 tokens or Gemini 3 Pro’s 1 million, they are still sufficient for tasks like analyzing multi-chapter textbooks or semester-long portfolios. The MoE architecture ensures that even larger models maintain fast and efficient performance without the heavy computational demands of dense transformers.
Customization and Fine-Tuning
Mistral models also shine in their adaptability. They support Parameter-Efficient Fine-Tuning (PEFT) techniques like LoRA and QLoRA, which allow educators to customize the models for specific curricula without the expense of full retraining. Using 4-bit quantization tools like bitsandbytes, institutions can fine-tune these models on consumer-grade hardware. A great example of this flexibility is Mathstral 7B, which is pre-tuned for STEM subjects and mathematical reasoning. For dynamic applications, such as incorporating current events into lessons, Mistral models can integrate with Retrieval-Augmented Generation (RAG) to access external data in real time.
As the Mistral AI Team puts it:
“Mistral 7B - The best 7B model to date, Apache 2.0.” - Mistral AI Team
Strengths and Weaknesses
Each AI model brings its own set of strengths and challenges when applied in educational settings.
GPT-5 stands out in STEM fields, thanks to its precise calculations and advanced coding capabilities. It achieved an impressive 90.5% on the ARC-AGI-1 benchmark, becoming the first model to cross the 90% threshold. However, its explanations can be tough for K–12 students to grasp, and its premium pricing makes it less appealing for routine use.
Claude Opus 4.5 shines in humanities and writing tasks, delivering detailed academic feedback and identifying bugs in production code with a 93% success rate - outperforming GPT-4’s 87%. Its 1-million-token context window is ideal for analyzing lengthy documents. That said, it tends to produce verbose responses and operates more slowly in real-time scenarios. Its “Constitutional AI” safety measures are valuable for handling sensitive educational content but can sometimes constrain creative outputs.
Llama 4 prioritizes privacy by enabling self-hosting, making it a strong option for FERPA-compliant institutions. However, it demands significant local GPU infrastructure and technical expertise, which can be a barrier for smaller organizations. While its API pricing is competitive, the operational costs can outweigh the savings for institutions with limited resources.
Mistral models are highly cost-effective, with Mistral Large 3 priced at just $0.50 per million input tokens - 2.5 times cheaper than other models. In a three-round test, it cost a mere $0.0233 compared to Claude Opus 4.5’s $0.3160, while scoring higher (9.4 vs. 8.1 out of 10). Its Mixture of Experts (MoE) design allows for inference speeds six times faster than Llama 2 70B. However, its ecosystem is smaller, and the 128,000-token context window limits its ability to handle extremely long documents.
Here’s a quick comparison of these models:
| Model | Primary Strength | Key Weakness | Best Use Case |
|---|---|---|---|
| GPT-5 | STEM accuracy, coding capabilities | High cost; complex for K–12 | Advanced mathematics, programming |
| Claude Opus 4.5 | Writing feedback; long-document analysis | Verbose; slower responses | Essay critique; research papers |
| Llama 4 | Privacy, self-hosting, data control | High operational overhead | FERPA-compliant environments |
| Mistral | Cost efficiency; multilingual support | Smaller context window; limited ecosystem | Budget-conscious institutions; routine tutoring |
Conclusion
Picking the right large language model (LLM) for education isn’t about finding a one-size-fits-all solution - it’s about aligning each model’s strengths with specific educational needs. For example, GPT-5 shines in advanced mathematics and coding tasks, making it ideal for university-level STEM courses. On the other hand, Claude Opus 4.5 excels in providing detailed writing feedback, which is perfect for humanities subjects. Llama 4 stands out in handling multimodal analysis for visual or creative disciplines, while the Mistral models offer strong reasoning capabilities at a lower cost, making them great for routine tutoring sessions. Together, these options suggest that a multi-model approach can unlock the full potential of AI in education.
“No single LLM is best for all educational applications. The winning strategy is to use multiple models and implement intelligent routing.”
Cost efficiency is another critical factor. By implementing intelligent routing, institutions can significantly reduce expenses. For instance, they can assign routine tasks to Mistral models (costing $0.50–$2.00 per million input tokens) and reserve more complex operations for GPT-5 (costing $10.00–$15.00 per million output tokens). This approach can lower AI-related costs by 60–85%, translating to annual expenses of $150,000–$400,000 for a student body of 10,000, compared to $800,000–$1.5 million if GPT-5 were used exclusively.
Platforms like Latitude simplify this process by offering tools to manage and evaluate multiple models. These tools allow educators to monitor model performance, compare outputs side-by-side on specific datasets, and refine results using human feedback. Institutions using such platforms have reported an 80% reduction in critical errors and up to an 8x improvement in prompt iteration speed for educational tasks.
To ensure flexibility and adaptability, avoiding vendor lock-in is crucial. By adopting an LLM-agnostic strategy and leveraging robust evaluation tools, schools and universities can effectively balance cost, quality, and teaching goals - meeting the diverse needs of both educators and students.
FAQs
Which LLM should I use for K–12 vs. college?
When working with K–12 education, it’s best to use domain-specific language models designed for early learning and student support. These models are better equipped to handle age-appropriate content and cater to the unique educational needs of younger students.
For college and higher education, however, advanced general-purpose models like GPT-5 or Claude are a better fit. These models shine when it comes to reasoning, tackling complex problems, and generating in-depth academic content.
In short, prioritize tailored models for younger learners and high-performing models for advanced academic levels to meet the specific demands of each educational stage.
How can schools cut LLM costs without losing quality?
Schools have the opportunity to cut down on LLM-related expenses without sacrificing quality by turning to open-source models. These models come at no cost but do require the right hardware and a certain level of technical know-how to tailor them to specific needs.
To manage costs even further, schools can explore efficient deployment methods, such as self-hosting these models. Additionally, introducing smart usage policies can make a big difference. For instance, automating repetitive tasks while reserving human oversight for more critical outputs ensures that performance stays aligned with educational objectives.
What’s the best setup for FERPA-safe student data?
To protect student data under FERPA, it’s crucial to blend technical protections with strict compliance measures. Start by using Data Processing Agreements (DPAs) to clearly define and limit how data can be used. Enforce strict access controls to ensure only authorized individuals can view sensitive information, and apply de-identification techniques to anonymize data whenever possible.
Additionally, carefully manage data flows and restrict third-party access to minimize exposure. If working with vendors, verify that they fully comply with FERPA regulations. For organizations seeking even greater control, on-premise solutions can be a good option. These systems allow you to store and process data locally, reducing potential risks tied to cloud-based platforms.