

Balancing speed, expenses, and accuracy is critical for building effective AI systems - but you can’t optimize all three at once. When creating AI tools, you’ll have to prioritize two factors while compromising on the third. For example:
-
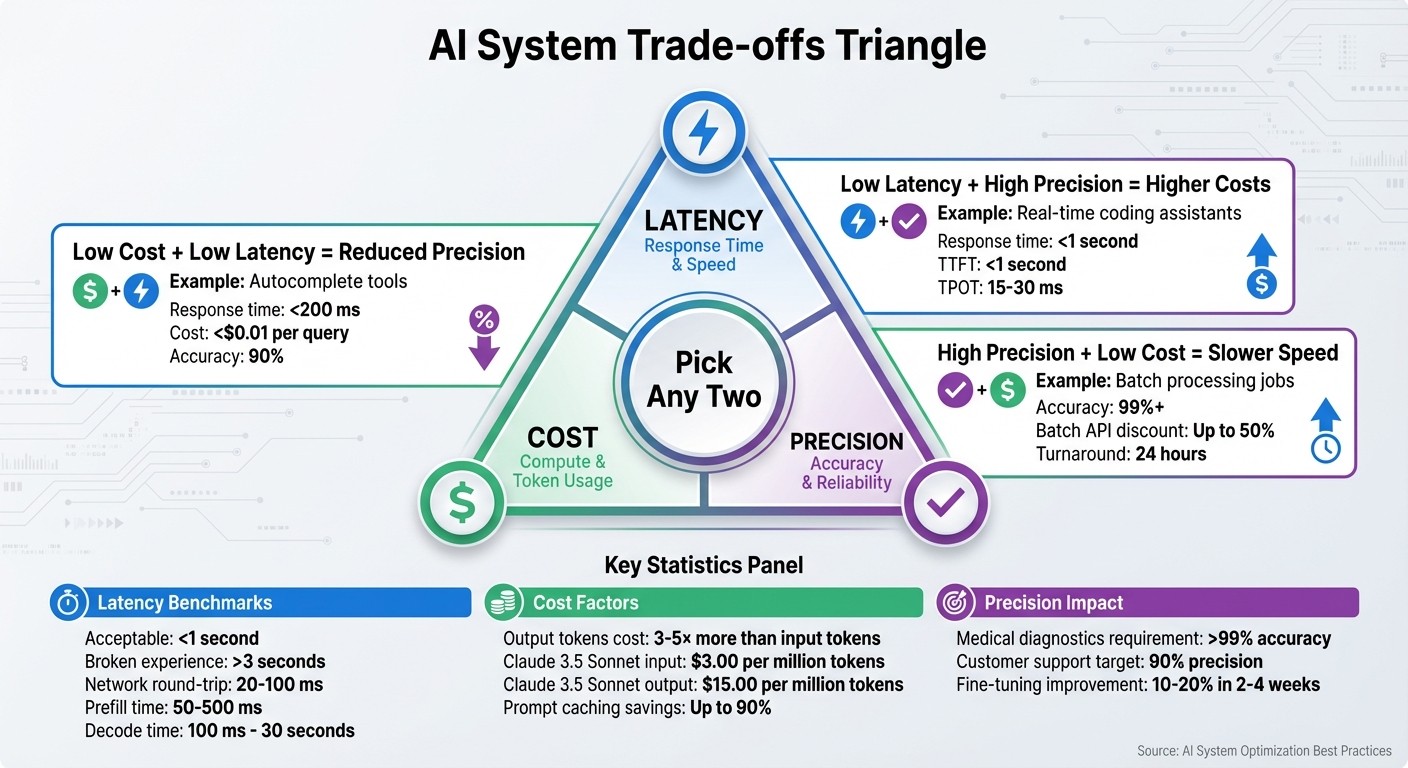
Low latency + High precision = Higher costs (e.g., real-time coding assistants).
-
High precision + Low cost = Slower speed (e.g., batch processing jobs).
-
Low cost + Low latency = Reduced precision (e.g., autocomplete tools).
Each decision impacts user experience, scalability, and profitability. For instance, a chatbot taking over 3 seconds to respond feels broken, while excessive token generation can spike costs. Understanding these trade-offs and aligning them with your use case ensures your AI product remains practical and effective.
Key takeaways:
-
Latency : Users expect responses in under 1 second; delays over 3 seconds are unacceptable.
-
Cost : Output tokens are 3–5× more expensive than input tokens, so controlling response length is vital.
-
Precision : Accuracy should meet business needs without unnecessary complexity or expense.
To succeed, focus on your application’s priorities, monitor performance in real time, and use strategies like model tiering, prompt caching, and feedback loops to balance these factors effectively.
AI System Trade-offs: Balancing Latency, Cost, and Precision
How Latency, Cost, and Precision Interact
These three factors - latency, cost, and precision - are closely linked. Adjusting one often affects the others, making it important to weigh trade-offs carefully when deciding where to allocate resources. Let’s break down each dimension to better understand these interactions.
Latency: Speed and User Experience
Latency is influenced by the amount of data being processed and the computational demands of the task. For most large language models, the main bottleneck isn’t processing power - it’s memory bandwidth, or how fast data moves between storage and processors. Techniques like quantization can reduce inference latency by 2–4× without sacrificing accuracy.
Here’s a breakdown of where time is spent during processing:
-
Network round-trip: 20–100 ms, depending on distance
-
Prefill time: 50–500 ms, based on the number of input tokens
-
Decode time: 100 ms to 30 seconds, depending on output length
-
Post-processing: 5–50 ms
Since output tokens are generated one at a time, longer responses naturally increase latency. Setting a max_tokens limit can help control response time by capping how long the model spends generating text.
Speed improvements often connect directly to cost savings, which leads us to the next dimension.
Cost: Budget and Resource Management
Costs in language models are tied to token processing, but there’s an imbalance: output tokens typically cost 3–5× more than input tokens. For example, in Claude 3.5 Sonnet, input tokens cost around $3.00, while output tokens cost $15.00.
This pricing structure makes controlling output length a powerful way to manage costs. A model generating 500-token responses will cost significantly more than one limited to 100 tokens, even if the inputs are identical. Additionally, in chat applications where the entire conversation history is sent with each message, costs can escalate rapidly. By the 16th message, the cost may be 16× higher than the first.
System architecture also plays a big role in cost efficiency. Features like prompt caching can reduce expenses dramatically - by as much as 90% for stable prefixes on some platforms and 50% on others. On the flip side, systems that don’t manage context growth or rely on premium models for every task can quickly become expensive.
As cost management shapes system design, precision requirements further refine these decisions.
Precision: Accuracy and Business Outcomes
Precision ensures that your AI delivers meaningful results, but improving accuracy often increases both latency and cost. Larger models generally offer higher precision, but they come with slower response times and higher expenses.
For simpler tasks, such as classification or JSON formatting, lower precision is often sufficient. Smaller, more affordable models can handle these tasks effectively. For instance, a fintech company in Q3 2024 discovered that 40% of its support queries were straightforward requests like “reset password.” By routing these queries to Claude 3 Haiku and caching static responses, the company cut its monthly LLM expenses from $6,000 to $1,800.
It’s also worth noting that precision improvements can hit a point of diminishing returns. Once a model meets the accuracy threshold needed for a specific business case, further enhancements may not justify the added cost and latency. The goal should be to achieve the minimum precision required for success, then optimize for speed and cost from there.
Balancing precision often means accepting trade-offs in latency and cost. This highlights just how interconnected these three dimensions are and why thoughtful calibration is essential for achieving the best outcomes.
How to Balance Latency, Cost, and Precision
Striking the right balance between latency, cost, and precision begins with a clear understanding of your specific use case. The priorities of a medical diagnostic tool, for instance, differ drastically from those of a customer service chatbot. Once you’ve identified what matters most for your application, you can apply practical strategies to optimize these three factors without losing sight of your core goals.
Match Metrics to Your Use Case
Every application has its own set of priorities when it comes to these metrics:
-
Medical diagnostics require precision rates exceeding 99% to avoid potentially life-threatening errors. In such cases, smaller, fine-tuned models are the way to go. These models achieve the necessary accuracy while keeping costs in check.
-
Real-time chatbots prioritize speed. For instance, response times under 200 ms are critical for keeping users engaged. Teams often use distillation techniques to compress larger models into faster versions without sacrificing too much accuracy. In even more time-sensitive scenarios, like those in autonomous vehicles, latency must drop below 100 ms. This is achieved by running quantized models on edge devices, which may trade off minor precision for the sake of speed.
-
Fraud detection systems provide an interesting example of balancing all three factors. By caching frequently used queries, teams can cut latency by up to 50% while maintaining the same level of precision. Similarly, customer support bots can achieve 90% precision while keeping costs below $0.01 per query.
To manage these trade-offs effectively, consider creating a prioritization matrix. Start with the business impact, then align your metrics with service-level agreements (SLAs). Regularly benchmark your performance and adjust as needed to maintain balance.
Use Observability for Continuous Improvement
Testing environments can only reveal so much. Real-world production use often uncovers patterns and issues that weren’t apparent during testing. That’s why real-time metric tracking is essential for spotting problems early and making improvements. Focus on metrics like latency percentiles (p50, p95, p99), inference costs (e.g., $0.002 per 1,000 tokens), and precision scores such as F1-scores above 0.85.
Set up dashboards with real-time alerts for issues like latency spikes (e.g., a 20% increase). Weekly automated evaluations can help detect precision drift, allowing teams to retrain models or make adjustments before accuracy takes a hit.
Latitude is one example of a platform that simplifies this process. It logs key metrics such as latency, costs, and outputs while running automated evaluations against precision benchmarks. This structured approach helps teams identify and fix issues like precision drift early, improving overall balance by 15–25% without adding manual workload. Human feedback loops further enhance optimization as the system scales.
A practical workflow might include these steps:
-
Log all key metrics in your models.
-
Use visualization dashboards for easy monitoring.
-
Set alerts for thresholds (e.g., latency exceeding 1 second).
-
Automate weekly evaluations to spot trends.
-
Conduct monthly reviews to remove low-performing configurations.
This process can reduce costs by 20–40%. While automated monitoring is key, integrating human feedback is equally important for refining precision.
Improve Precision with Human Feedback
Incorporating structured feedback loops is a powerful way to refine models without increasing latency or costs. For example, simple thumbs-up/down interfaces let users provide quick feedback on responses. Labeling just 1–5% of interactions is often enough for effective fine-tuning, which can improve precision by 10–20% in as little as 2–4 weeks.
To avoid slowing down your system, batch feedback for offline processing. This also helps control costs by working with smaller datasets - typically under 10,000 samples. Active learning can further optimize this process by flagging uncertain predictions for human review. This method targets high-impact cases and can boost precision by 15% with minimal labeling effort.
For instance, Duolingo has successfully used feedback to fine-tune its translation models. By focusing updates on specific areas rather than retraining entire models, they’ve maintained low latency (under 300 ms) while improving accuracy.
Andrew Ng suggests following the 80/20 rule : automate 80% of processes while using human feedback to handle the remaining 20% of edge cases. This approach can deliver significant precision gains without a proportional increase in costs. Teams using iterative feedback loops have reported up to 25% precision improvements after just three cycles, with only a 5% increase in costs. To maintain quality and avoid bias, it’s important to rotate annotators regularly during this process.
Frameworks for Analyzing Trade-offs
Balancing latency, cost, and precision in AI systems can feel like walking a tightrope. Every system operates within a triangle of quality, latency, and cost - and trying to optimize all three at once? Nearly impossible. The trick lies in identifying which trade-offs align with your goals and using proven frameworks to guide your decisions. Below are some structured approaches to help you navigate these challenges.
Cost-Benefit Analysis for Optimization
Start by aiming for “good enough” accuracy, then work backward to find the most efficient way to maintain that level. This prevents you from building a system that’s cheap and fast but ultimately ineffective.
Break down costs and latency into smaller components. For example, token costs are often imbalanced - output tokens can be 3–5 times more expensive than input tokens.
Take this example: a fake news classifier set a goal of 90% accuracy, under $5 per 1,000 articles, with a latency of less than 2 seconds. Initially, GPT-4o with few-shot learning hit 91.5% accuracy but cost $11.92. By fine-tuning GPT-4o-mini with 1,000 examples, the same accuracy was achieved for just $0.21.
To find the break-even accuracy, compare the financial benefit of correct predictions against the cost of errors. For instance, if a correct classification saves $50 in review time and an error costs $300 to fix, you’ll need to hit a specific accuracy threshold to justify automation.
Planning for Scale
Scaling introduces new trade-offs. For example, sending the full conversation history with every interaction can quickly become expensive. A 50-turn conversation might cost $0.025 per request, adding up to $250 daily for 10,000 requests. You can mitigate this by using techniques like history truncation or summarization.
At scale, model tiering becomes critical. Assign simpler tasks (like classification) to smaller, cost-effective models like GPT-4o-mini ($0.15 per million input tokens) and reserve larger models (GPT-4o at $2.50 per million input tokens) for complex reasoning. This approach can cut costs to less than 2% of what you’d spend using a single large model for everything.
Prompt caching is another effective strategy. Providers like Anthropic offer discounts of up to 90% on cached input tokens. To improve cache hit rates, structure your prompts by placing static elements (like system instructions and few-shot examples) at the beginning, with dynamic content at the end.
It’s also essential to set hard limits to control costs. Use the max_tokens parameter on API calls to prevent models from generating unnecessarily long responses that could lead to a 20× cost increase on output tokens. For batch processing, consider Batch APIs, which can provide up to a 50% discount with a 24-hour turnaround.
Comparison: Optimizing Each Factor
Different priorities require different architectural decisions. Here’s how these trade-offs play out:
| Focus | Trade-off | Best Use Case | Key Strategy |
|---|---|---|---|
| Quality + Latency | Cost | Real-time coding assistants, high-frequency trading | Use powerful models with streaming |
| Quality + Cost | Latency | Overnight document analysis, legal discovery batch jobs | Process in batches; fine-tune smaller models |
| Latency + Cost | Quality | Autocomplete suggestions, casual gaming NPCs | Use the smallest model that meets your needs |
For interactive applications, aim for a Time to First Token (TTFT) under 1 second and a Time Per Output Token (TPOT) between 15–30 ms. While streaming doesn’t reduce overall latency, it can make the system feel faster. For reliability, target a P95 total latency under 8 seconds and a 99.5% success rate.
Platforms like Latitude can help you track latency, cost, and precision metrics in real time. This visibility allows you to quickly spot when one factor - like a model update increasing output length - starts to drift, so you can adjust before it impacts your budget or user experience. These comparisons highlight how prioritizing different factors shapes system architecture in practical scenarios.
Conclusion
Key Takeaways
When building reliable AI systems, you’re often faced with a tough choice: balancing quality , latency , and cost. You can usually optimize for only two of these at a time, so it’s crucial to decide which two align best with your goals. Starting with an accuracy-first mindset ensures your system meets business requirements for precision before you begin fine-tuning for speed or cost efficiency. Once accuracy is locked in, you can look for ways to streamline performance without compromising the user experience.
The best-performing teams rely on practical strategies to manage these trade-offs. Techniques like model tiering, prompt caching, setting strict max_tokens limits, and leveraging streaming can help you strike the right balance between cost, speed, and precision. These aren’t just theoretical ideas - they’re actionable tools that directly affect both your expenses and your users’ satisfaction.
Another critical element is continuous monitoring. AI systems are inherently unpredictable, which means they come with what’s called an “Unreliability Tax.” This refers to the extra compute power, engineering effort, and time required to catch potential failures before they impact users. To stay ahead, track metrics like latency (p50, p95, p99), token usage, cost per request, and precision outcomes in real time. For example, if a model update unexpectedly increases output length, you need the visibility to respond quickly. These insights allow you to make adjustments and drive meaningful improvements.
Next Steps
To move from an 80% prototype to a polished, production-ready system with 95%+ performance, you’ll need disciplined workflows and robust tools. Start by setting clear accuracy benchmarks tied to the financial impact of errors - how much does a correct prediction save, and what’s the cost of a mistake?. Use this data to guide your optimization efforts. For example, you can implement routing strategies that allocate resources based on task complexity: quick single-shot calls for simple tasks and more extensive token budgets for complex reasoning.
Platforms like Latitude can help streamline this process. With tools to monitor latency, cost, and precision metrics, collect user feedback, and validate improvements through evaluations, you can continuously refine your AI features. This structured approach turns optimization into a data-driven process, helping you maintain the perfect balance for your specific needs. By combining these insights with disciplined workflows, you can ensure your AI systems deliver consistent, high-quality results.
FAQs
How do I choose which two to optimize: latency, cost, or precision?
When deciding between latency , cost , and precision , think about what your application needs most. For tasks that demand real-time performance, prioritize low latency , even if it means spending more or sacrificing some precision. If your application relies heavily on accuracy, then precision should take precedence, even if it increases costs or slows things down. On the other hand, if keeping expenses low is your main goal, focus on reducing costs while ensuring latency and precision stay within acceptable limits. The right balance will depend entirely on your specific use case and objectives.
What’s the fastest way to cut LLM costs without hurting quality?
The fastest way to cut costs for large language models (LLMs) without sacrificing quality is through quantization techniques. Methods like 8-bit or 4-bit quantization can reduce memory and GPU usage by as much as 75% , all while keeping accuracy largely intact.
How can I measure precision in production, not just in tests?
To evaluate precision in production, rely on real-world data and maintain consistent monitoring. Use a mix of benchmarks, human evaluations, and live testing to gauge reliability over time. Key metrics such as relevance , hallucination rates , and coherence provide insight into actual performance. Tools like Latitude can transform production failures into regression tests, allowing for continuous refinement and ensuring the system evolves alongside changing user behavior.