

Human feedback is key to improving AI prompts. Instead of relying solely on automated checks, human input ensures AI outputs align with user needs, covering areas like tone, clarity, and intent. Here’s how you can optimize this process:
-
Why it matters : Automated tools miss subjective issues like tone or user intent. Human feedback bridges this gap.
-
Who contributes : Product managers set goals, engineers ensure reliability, domain experts provide insights, and support agents highlight usability issues.
-
How to collect feedback : Focus on critical prompts, use clear instructions with examples, and combine numerical ratings with written comments.
-
Balancing automation and human input : Use pre-trained models for routine checks, and rely on humans for complex cases.
-
Iterative improvement : Establish feedback loops, use golden datasets for benchmarks, and track progress with composite scores.
-
Success metrics : Define clear benchmarks, involve domain experts for accuracy, and standardize evaluations for consistency.
Platforms like Latitude simplify collaboration, enabling teams to analyze feedback, debug issues, and refine prompts efficiently. By combining automation with human insight, you can create prompts that are reliable, user-focused, and continuously improving.
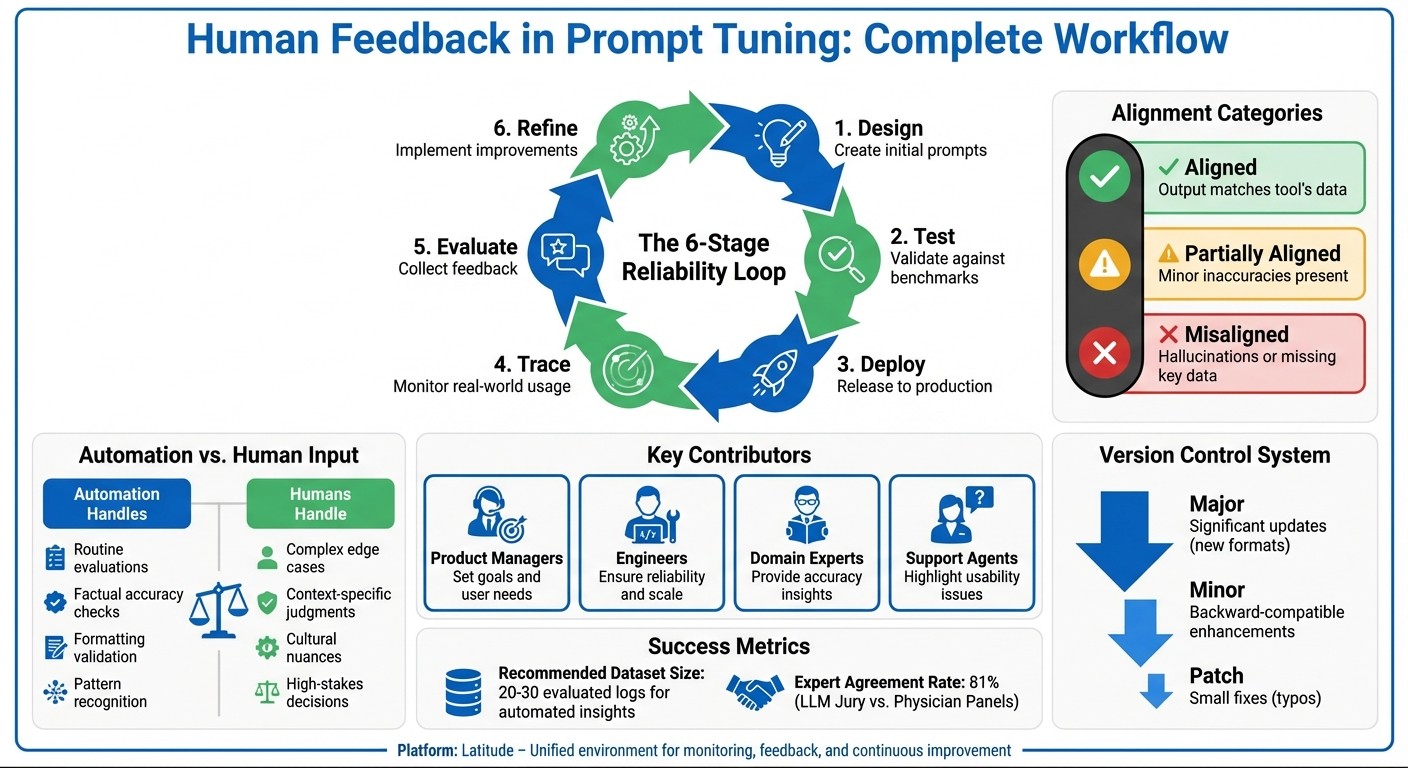
Human Feedback in AI Prompt Tuning: 6-Stage Workflow and Best Practices
Structuring Feedback Collection Workflows
Selecting Prompts for Evaluation
Focus on evaluating prompts that involve critical decisions, direct user interactions, or show inconsistent performance. Use two approaches: batch mode for regression testing against established datasets and live mode to monitor real-world usage. Live mode is particularly useful for spotting performance shifts and edge cases over time. By structuring your evaluation this way, you can create a solid foundation for gathering meaningful feedback.
Writing Clear Instructions for Annotators
Unclear instructions lead to inconsistent results. To avoid this, provide specific, task-oriented evaluation criteria. For example, define clear alignment categories like:
-
Aligned : Output matches the tool’s data.
-
Partially Aligned : Minor inaccuracies are present.
-
Misaligned : Output includes hallucinations or ignores key data.
Including these categories takes the guesswork out of the process and ensures evaluations stay consistent.
To further guide annotators, offer few-shot examples that showcase positive outputs, negative outputs, and tricky edge cases. These examples clarify expectations and illustrate what “good” looks like. Combine numerical ratings (like Likert scales or pass/fail) with brief written comments. While the ratings help track trends, the comments provide context that numbers alone can’t capture. Clear instructions and examples give annotators the tools they need to provide actionable, reliable feedback.
Balancing Exploration and Exploitation
Once feedback is collected, it’s important to balance trying new ideas with maintaining what already works. Use golden datasets as benchmarks to protect proven approaches while exploring new variations. Before introducing these variations into production, test them against the benchmark dataset to measure their impact.
Start experimenting with prompt engineering concepts in playground mode. Once you identify promising candidates, validate them through structured A/B tests. Ensure that key metrics - like helpfulness and safety - meet minimum acceptable levels before rolling them out. This step-by-step process allows you to innovate without jeopardizing the reliability of your existing prompts.
Using Automation to Scale Human Feedback
Using Pre-Trained Reward Models
Pre-trained reward models are a game-changer for automating routine evaluations and easing the workload of human reviewers. These models learn from past human feedback and apply those patterns to assess new outputs. They shine in measurement and benchmarking , helping to ensure quality across thousands of interactions without requiring constant manual oversight.
That said, these models have their limits. While they’re great at spotting straightforward issues like factual inaccuracies or formatting mistakes, they often fall short when it comes to nuanced or context-heavy judgments that demand domain expertise. The best approach? Use these models to handle the bulk of the work - filtering and flagging outputs - and pass on the trickier cases to human reviewers. This creates a two-tiered system: automation for efficiency and human expertise for complexity.
Semi-Supervised Feedback Approaches
Semi-supervised methods offer a smart way to cut down on annotation time by blending human-labeled examples with larger sets of unlabeled data. For instance, annotators can label just 10-15% of a dataset. The model then uses these examples to predict labels for the remaining data, with humans stepping in only to verify low-confidence predictions.
This method is particularly effective when dealing with high volumes of similar prompts. The model picks up on patterns from the initial annotations and applies them consistently, reducing the need for constant human input. However, when the task requires more judgment or falls outside the model’s capabilities, human reviewers remain essential. It’s a balanced approach that combines the efficiency of automation with the reliability of human oversight.
Preserving Human Judgment in Complex Scenarios
When it comes to debugging, fine-tuning, or making context-specific improvements, human judgment is irreplaceable. These are situations where correction and improvement are key - like refining prompts for edge cases, addressing ambiguous outputs, or ensuring that context takes precedence over automated pattern recognition.
Automated tools can flag potential issues, but it takes human expertise to fully understand and resolve them. Domain experts are especially critical for catching subtleties that models often miss, such as cultural nuances, industry-specific language, or strategic business needs. For high-stakes outputs, customer-facing interactions, or scenarios where errors could have serious consequences, keeping humans in the loop is non-negotiable. This blend of automation and human insight ensures both scalability and quality.
Iterative Refinement and Continuous Improvement
Establishing Feedback Loops
The best way to refine prompts isn’t through quick fixes - it’s through ongoing cycles. A solid process involves six key stages: design, test, deploy, trace, evaluate, and refine. This structured approach, often called a Reliability Loop, ensures your prompts stay aligned with real-world user needs instead of relying on assumptions.
Improvement should be grounded in data, not guesswork. While manual tweaks can help during the early stages or for big adjustments, they become less practical as edge cases grow. Use human judgment to define what “good” looks like, but pair it with systematic log analysis. Production logs and curated datasets provide a reliable foundation for making decisions, moving beyond intuition. These feedback loops are essential for making measurable progress with each iteration.
Tracking Progress Across Iterations
Once feedback loops are in place, tracking progress ensures that every refinement adds value and remains sustainable. To do this effectively, create a golden dataset - a diverse set of inputs, expected outputs, and tricky edge cases. This dataset acts as a benchmark for spotting regressions and measuring improvements. Combine evaluation results into composite scores to monitor trends and catch issues early.
Keep an eye on these scores across different versions to identify patterns. For example, if you’re tackling issues like toxicity or hallucinations, configure your evaluations to aim for lower scores in those areas. When you spot low scores, dig into the logs to find the root causes, and add those cases to your golden dataset. This creates an evolving benchmark that grows alongside your prompts.
For automated prompt suggestions, aim to analyze at least 20–30 evaluated logs for meaningful insights. If you’re working with fewer logs, manual review tends to be more reliable.
Adapting Prompts to New Challenges
User needs change, models evolve, and new edge cases pop up - so your prompts need to adapt. Regularly monitor production trends using live evaluations to catch performance drifts early. These drifts might result from shifts in user behavior, new types of queries, or subtle changes in how the model performs. By combining automated tracking with human insight, you can stay ahead of these challenges.
When rolling out updates, use semantic versioning to make the impact of changes clear. For example:
-
Major versions indicate significant updates, like new response formats.
-
Minor versions cover enhancements that are backward-compatible, such as adding optional parameters.
-
Patch versions address smaller fixes, like typo corrections.
This level of clarity helps teams manage updates smoothly, ensuring your prompts remain both reliable and responsive.
Measuring Success and Ensuring Quality
Defining Success Metrics
To keep the optimization process on track, having clear success metrics is a must. Start by using composite scores - these combine multiple evaluation results into a single report, giving a clear picture of prompt performance. Some metrics aim for higher scores, while others, like those assessing toxicity or hallucinations, require lower scores. Before implementing changes, set acceptance criteria with minimum score thresholds. This step ensures that updates meet quality standards and prevents issues like regressions. These measurable benchmarks pave the way for incorporating expert insights, which are discussed next.
Incorporating Domain Expertise
Domain experts bring a unique perspective that automation can’t replace: they define golden labels , or what “correct” truly means. For instance, researchers tested the MedFactEval framework by involving expert physician panels to establish ground truth. The automated LLM Jury that followed achieved an 81% agreement rate with these expert evaluations, effectively matching human performance.
Experts are also invaluable for identifying recurring issues. In December 2025, NurtureBoss, an AI startup, worked with Hamel Husain to manually review hundreds of interaction traces. Using axial coding , they categorized failures into specific problems like date handling, handoff errors, and conversation flow. These three areas accounted for most of the errors, leading to a focused validation system. Similarly, in June 2024, Salus AI used expert-driven analysis to refine prompts for marketing call compliance in premium health screenings. By combining expert insights with retrieval-augmented generation (RAG), they boosted model accuracy from 80% to between 95% and 100%.
To streamline processes, use binary judgments like PASS/FAIL for expert reviews. This approach reserves expert time for complex or high-stakes cases, while simpler evaluations can be handled by automated systems. Expert involvement is a cornerstone of a reliable evaluation system, as detailed in the next section.
Quality Assurance in Feedback Processes
Standardizing human evaluations is crucial. Use 5-point rating rubrics and calibration protocols to ensure consistency across reviewers. Incorporating double-blind reviews further reduces bias and strengthens the reliability of your gold standard data, which serves as the benchmark for all evaluations.
A hybrid approach works best: combine LLM-as-Judge models for scalable, nuanced scoring with human reviews for critical validations. For example, in September 2025, the MedVAL framework, created by Asad Aali and Akshay S. Chaudhari, analyzed 840 physician-annotated outputs across six medical tasks. By classifying errors by risk level and type (like hallucinations), they used self-supervised distillation to improve the F1 score for safe/unsafe classification from 66.2% to 82.8%.
Finally, maintain an evolving golden dataset as a benchmark for regression testing. This ensures that your quality standards remain aligned with the challenges of real-world applications.
Conclusion: Key Takeaways and Next Steps
Summary of Best Practices
Human feedback turns prompt tuning into a more structured and effective process. To get started, focus on choosing prompts wisely - especially in scenarios where model performance has the most impact. Provide annotators with clear and consistent instructions, and strike a balance between testing new ideas and refining what already works. Use composite scoring to evaluate multiple performance factors and set clear minimum thresholds for acceptance before implementing changes. Combine automated validation using LLM-as-Judge tools with human reviews for critical cases, ensuring expert insights are applied where they matter most. Create feedback loops that tie real-world outcomes back to prompt adjustments, and maintain a golden dataset for regression testing as your benchmark evolves. Implementing these steps requires collaboration across teams.
Building Collaborative AI Quality Processes
These best practices thrive on teamwork. Prompt tuning isn’t something you can tackle alone - it needs collaboration across teams like product managers, engineers, and domain specialists. Domain experts help define what “correct” looks like by setting golden labels and spotting recurring issues. Engineers develop systems for collecting and analyzing feedback at scale. Product teams ensure that all improvements align with user needs and business goals. Use binary decisions like PASS/FAIL for expert reviews to save their time for more complex cases, while simpler evaluations can rely on automated systems. This approach ensures quality standards are not only technically sound but also practical and aligned with real-world needs.
Using Platforms Like Latitude
Platforms such as Latitude help simplify and unify this collaborative process. By offering an all-in-one environment, Latitude allows teams to monitor model behavior, gather feedback, and drive continuous improvements without juggling multiple tools. Instead of piecing together separate systems for observability, evaluation, and collaboration, Latitude provides a centralized space where product, engineering, and domain teams can work together seamlessly. This includes debugging, tracking quality metrics, and refining prompts - all in one place. For teams aiming to build dependable AI products, an integrated platform like Latitude reduces friction and speeds up the journey from feedback to meaningful improvements.
FAQs
How many logs do I need for reliable human feedback?
The amount of feedback logs needed to achieve reliable human input depends on the specific task and its context. In most cases, gathering several instances of feedback allows for a more precise evaluation and fine-tuning of prompts. This aligns with established practices for prompt optimization. Simply put, the more data you collect, the better your chances of gaining useful insights and making meaningful improvements.
When should humans review outputs instead of automated judges?
Humans play a crucial role when addressing nuanced issues like tone, relevance, safety, or subjective preferences. These areas often involve complex criteria that automated systems might not handle effectively. For tasks requiring an initial quality check or a deeper understanding, human judgment ensures accuracy and appropriateness.
What should go into a golden dataset for prompt evaluation?
A golden dataset is a collection of carefully selected inputs paired with their expected outputs. It’s designed to cover essential scenarios, edge cases, and particularly tricky examples. For every input, there’s a clearly defined output - whether it’s a string, JSON structure, specific key details, or a label.
Often formatted as a CSV file, this dataset serves as a reliable benchmark. It ensures consistency in evaluations and helps safeguard prompt quality by catching regressions during updates.