Turn human feedback into measurable metrics with clear criteria, concise rubrics, effective rating scales, and integrated monitoring for AI quality.

César Miguelañez

Transforming human feedback into measurable metrics is essential for improving AI systems. By defining clear evaluation criteria, using structured workflows, and selecting effective rating scales, you can turn subjective insights into actionable data. This ensures consistent benchmarking, identifies areas for improvement, and supports better decision-making.
Key takeaways:
Define clear criteria: Set specific standards for quality dimensions like clarity, relevance, and coherence by creating text evaluations.
Use structured rubrics: Simplify evaluations with concise, consistent rubrics to reduce variability.
Choose the right rating scales: Balance detail with usability (e.g., Likert scales, binary choices).
Organize feedback effectively: Combine quantitative ratings with qualitative insights for a complete picture.
Integrate with tools: Platforms like Latitude link feedback to metrics for monitoring and optimization.
Define Clear Evaluation Criteria
The first step in turning human feedback into measurable metrics is to define what "good" means for your AI system. Without clear criteria, reviewers may interpret quality in different ways, leading to inconsistent scores that are hard to track over time. In fact, individual reviewers’ assessments can vary by as much as 40% without a standardized framework. Establishing clear criteria lays the groundwork for creating detailed rubrics and quality measures. This structured approach starts with defining key quality dimensions and evolves into scalable rubrics that transform subjective feedback into actionable data.
Identify Key Quality Dimensions
After setting clear criteria, the next step is identifying the dimensions that define clarity, relevance, and coherence. These dimensions help ensure your AI system meets user expectations. For most applications, three core dimensions are essential: clarity (are instructions easy to understand?), relevance (does the output align with user intent?), and coherence (is the response logical and consistent?). These aren't abstract ideas - research shows that prompt engineering with clear instructions and numbered steps result in 87% better compliance, while coherence directly impacts 32% of user satisfaction.
Tailor additional dimensions to your specific use case. For example, a customer service chatbot might prioritize empathy and accuracy, while a code generation tool may focus on syntax correctness and efficiency. Retrieval-augmented generation systems require a strong emphasis on faithfulness to source material to avoid hallucinations. Similarly, public-facing applications may need to include metrics for detecting toxicity or bias to ensure safety. The goal is to align your evaluation dimensions with user priorities and potential risks in real-world use.
Create Scalable Rubrics
Once you've identified your quality dimensions, turn them into rubrics for consistent evaluation. According to Label Studio, "A short set of clear dimensions applied consistently tends to produce cleaner signal than a long checklist that leaves room for interpretation". Keep rubrics concise and focused - overly detailed checklists often lead to inconsistent results.
Standardized rubrics help reduce scoring variability. Design your rubric around observable behaviors rather than subjective opinions. For instance, instead of vaguely rating "quality" on a 1-5 scale, define what each score represents. A score of 5 could mean "complete task fulfillment with no factual errors and an appropriate tone", while a 3 might indicate "partial task completion with minor inaccuracies." Regular calibration sessions using gold-standard examples can further align reviewers and minimize subjective bias.
Use Effective Rating Scales for Quantification
Rating scales are essential for turning subjective judgments into measurable data. They serve as the numerical backbone for aggregating feedback. However, the type of scale you choose can significantly impact the quality of your data. Overly complex scales can exhaust evaluators, while overly simple ones might lack the depth needed for meaningful insights.
Select the Right Scale Type
Choosing the right scale depends on what you're measuring. For side-by-side comparisons of model outputs, paired comparisons are ideal. If you're gauging satisfaction or the intensity of sentiment, Likert scales (e.g., 1–5 or 1–7) are a great fit. Numeric scales (like 0–10) are well-suited for assessing attributes such as helpfulness or fluency, often forming the basis of metrics like the Net Promoter Score.
Balance detail with usability to avoid evaluator fatigue. Scales with 3–5 points are quick to use and easy to interpret but may sacrifice nuance. On the other hand, 7–10 point scales allow for more detailed analysis but can be tiring for respondents. Consider your audience: general consumers or mobile users might prefer visual scales like emojis or stars, while professional evaluators can handle more intricate rating systems.
Even-numbered scales can encourage decisive judgments. For tasks requiring clear decisions - such as evaluating negative traits like toxicity - scales without a neutral option (e.g., 1–4 or 1–6) work well. They prevent evaluators from defaulting to the middle. However, when neutrality is a valid response, odd-numbered scales with a middle option are more appropriate.
Once you've chosen the right scale, the next step is ensuring consistent scoring across evaluators.
Ensure Consistency in Scoring
Consistency in scoring is just as important as selecting the scale itself. Start by training evaluators with gold-standard examples to set clear expectations. Calibration sessions, where reviewers score the same samples and discuss their reasoning, can help align their interpretations of the rubric and reduce variability.
Measure scoring consistency with inter-rater reliability metrics. For tasks where two evaluators review the same outputs, use Cohen's Kappa. For projects involving multiple reviewers, Fleiss' Kappa is more appropriate. These tools help identify whether evaluators are interpreting the scale consistently and can highlight the need for additional training.
Collect and Structure Feedback
Organizing feedback effectively helps turn opinions into actionable insights. When feedback is structured with clear categories, ratings, and context, it becomes much easier to analyze and act on. Aim to design workflows that balance capturing detailed insights with keeping the process simple for evaluators.
Design Feedback Workflows
Start by defining the types of feedback you need. For example, if you're evaluating overall performance, numerical ratings work well - they're quick to gather and easy to summarize. On the other hand, if you're focusing on improving prompts or debugging tricky cases, open-ended feedback from experts can provide the depth you need. You can also use implicit signals, such as thumbs up or down, to gather quick user input.
Combine quantitative and qualitative feedback methods for a comprehensive approach. Numerical ratings are perfect for scalability and benchmarking, while open-ended comments provide richer context for solving specific issues. Another effective method is preference-based feedback, where evaluators compare two outputs side-by-side. This approach is particularly useful for training reward models in reinforcement learning workflows.
Make it easy for evaluators to provide feedback. For domain experts, offer clear rubrics and include examples to guide their reviews. For end users, keep it simple - a 1–5 star rating or thumbs up/down option is often enough. The easier it is to give feedback, the more data you'll collect, and the better your metrics will reflect real-world performance.
Structured feedback lays the groundwork for integrating insights with monitoring tools, making it easier to track and improve performance.
Integrate Feedback with Observability Tools
Once feedback workflows are in place, link them to observability tools to connect human evaluations with performance data. Platforms like Latitude enable you to directly associate feedback with specific model outputs, prompts, and parameters. This connection helps identify patterns, like whether certain prompt variations consistently perform poorly, so you can address issues quickly.
Use a mix of real-time and batch monitoring to maintain quality. Real-time monitoring (live mode) allows you to catch quality or safety issues as they happen. Batch mode, on the other hand, is ideal for regression testing against "golden datasets" to ensure new versions of prompts don't negatively impact established benchmarks. Regularly updating your golden dataset with challenging examples or successful edge cases from production logs can further refine your benchmarks over time.
Simplify reporting with composite scores while retaining the ability to drill down. Combine evaluation dimensions like tone, accuracy, and safety into a single composite score for a high-level summary. At the same time, ensure you can analyze individual metrics when needed. For metrics like toxicity or hallucination rates, label them as "negative" in your evaluation tools so optimization algorithms aim for lower scores, not higher ones.
This integrated approach makes it easier to track performance trends and take targeted action.
Map Feedback to Metrics
Once feedback is structured, the next step is turning it into measurable performance metrics. This involves converting insights into actionable data points that track how well your AI is performing and where it needs improvement. By organizing feedback into specific metric categories and setting benchmarks, you create a clear roadmap for optimization.
Categorize Feedback by Metric Type
Organize feedback into meaningful metric categories that highlight different aspects of AI performance. These categories might include:
Accuracy metrics, such as precision and recall
Quality metrics, like coherence and relevance
Safety metrics, including toxicity and bias detection
User satisfaction scores
Each category focuses on a unique area of performance, guiding targeted improvements.
Flag negative metrics for improvement. For example, metrics like toxicity or hallucination rates should be clearly labeled in your evaluation tools. This ensures your optimization efforts reduce these values rather than accidentally increasing them. Mislabeling or neglecting this step could lead to optimizing in the wrong direction.
With feedback categorized, the next step is to establish performance benchmarks.
Set Baselines and Performance Targets
Start by determining baseline values for each metric. Use your current AI system to evaluate performance across all categories. These baseline numbers (e.g., a hallucination rate of 12% or a user satisfaction score of 3.8 out of 5) act as reference points. Without them, you can’t measure whether changes are improving or hindering performance.
Define performance targets based on baseline data and business goals. For instance, if the baseline hallucination rate is 12%, you might aim for an initial target of 8%, with a long-term goal of 5%. For applications where safety is critical, enable live monitoring of key metrics by toggling "Live Evaluation." This allows you to catch regressions in real time rather than discovering issues after they’ve impacted users.
As your AI system improves, update these targets. What starts as an ambitious goal can eventually become your new baseline, driving continuous progress. By mapping feedback to metrics, you create a system that supports ongoing monitoring and aligns with optimization efforts.
Best Practices Checklist
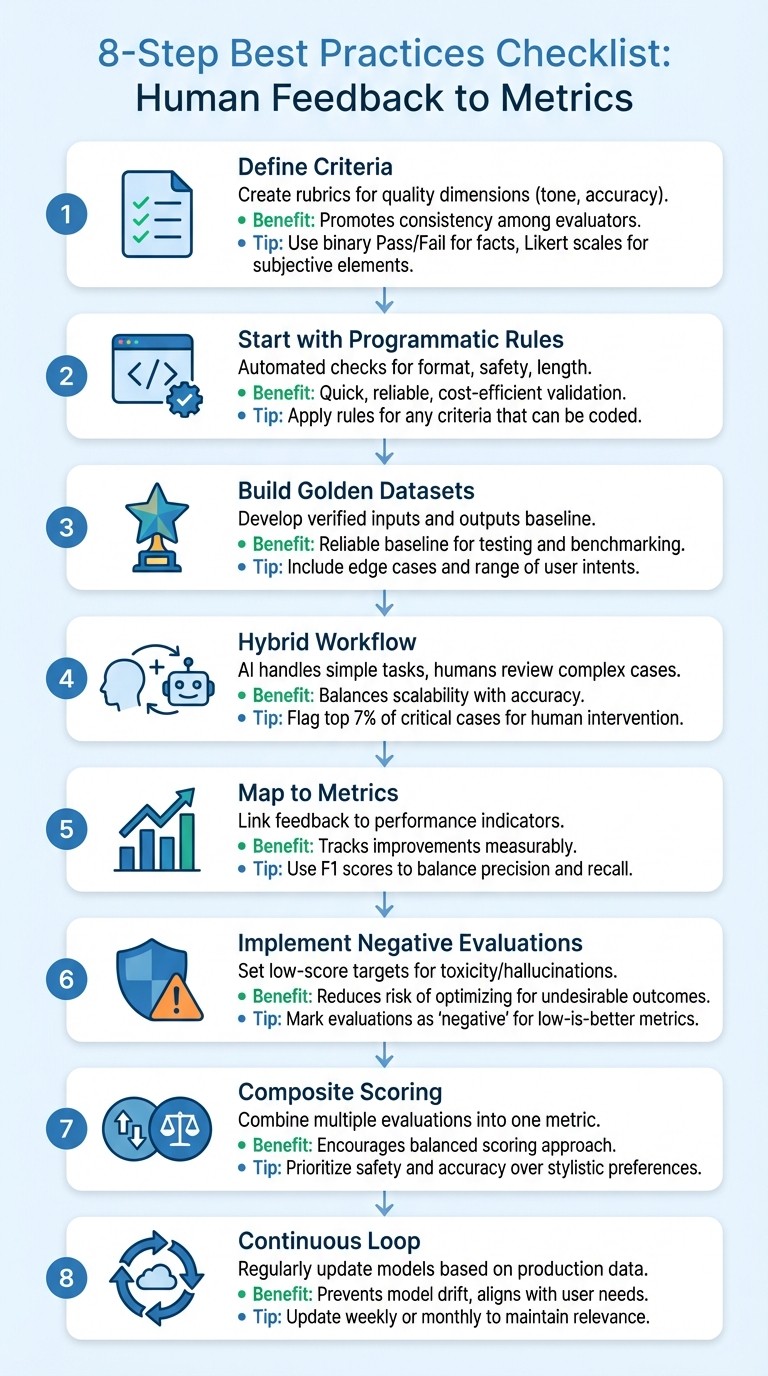
8-Step Checklist for Transforming Human Feedback into AI Metrics
To effectively translate human feedback into measurable metrics, follow this checklist. It combines programmatic rules, AI-based evaluations, and human oversight to ensure quality while keeping costs under control. Below is a consolidated table outlining actionable steps.
Checklist Table
Step Name | Description | Benefits | Implementation Tips |
|---|---|---|---|
Define Criteria | Create rubrics tailored for specific quality dimensions like tone and accuracy. | Promotes consistency among human and AI evaluators. | Use binary (Pass/Fail) for concrete facts and Likert scales for subjective elements like tone. |
Start with Programmatic Rules | Begin with automated checks for format (e.g., JSON), safety filters, and length constraints. | Quick, reliable, and cost-efficient validation. | Apply rules for any criteria that can be coded. |
Build Golden Datasets | Develop a "gold standard" dataset of verified inputs and outputs. | Provides a reliable baseline for testing and benchmarking. | Include edge cases and a range of user intents. |
Hybrid Workflow | Assign straightforward tasks to AI while reserving complex or high-stakes cases for human review. | Balances scalability with accuracy for nuanced scenarios. | Use RLTHF to flag critical cases (e.g., the top 7%) for human intervention. |
Map to Metrics | Link feedback categories directly to performance indicators. | Tracks improvements in a measurable way. | Use F1 scores to balance precision and recall for relevance. |
Implement Negative Evaluations | Set low-score targets for traits like toxicity or hallucinations. | Reduces the risk of optimizing for undesirable outcomes. | In Latitude, mark these evaluations as "negative" to signal low scores are better. |
Composite Scoring | Combine multiple evaluation types into one performance metric. | Encourages a balanced approach to scoring. | Prioritize safety and accuracy over stylistic preferences in the final score. |
Continuous Loop | Regularly update reward models and prompts based on production data. | Helps prevent model drift and aligns with changing user needs. | Update models on a weekly or monthly basis to maintain relevance. |
When calculating composite scores, prioritize critical factors like safety and factual accuracy over subjective elements such as tone. This ensures that optimization efforts align with both user expectations and business objectives.
Conclusion
Turning human feedback into measurable metrics is key to advancing AI systems. Using the checklist outlined earlier, structured feedback and clear performance goals can transform subjective insights into actionable data that drives meaningful progress.
Striking the right balance between automation and human oversight is equally important. Automated systems can efficiently handle routine checks and scale evaluations for aspects like tone and relevance. However, human input remains essential for addressing edge cases, domain-specific challenges, and critical decisions.
Live monitoring brings everything together by making the process actionable in real-time environments. Activating live evaluations for key metrics - such as safety and format validation - helps catch issues as they happen. Combining live and batch evaluations ensures continuous oversight throughout the AI's development and deployment.
Platforms like Latitude play a vital role in this process, offering tools for observability, structured feedback, and automated evaluations. Whether you're analyzing golden datasets in batch mode or keeping an eye on production logs, these tools help teams move from reactive problem-solving to proactive quality control.
FAQs
How do I pick the right rubric dimensions?
To choose the right rubric dimensions, aim for feedback that is specific, actionable, and relevant. Focus on dimensions that assess critical aspects of model performance, such as accuracy, relevance, coherence, or hallucination rates. Ensure these dimensions align with your evaluation objectives, and incorporate quantitative metrics like precision or recall to make assessments more meaningful. Customize the rubric to fit your specific use case for a more targeted and effective evaluation process.
What rating scale should I use?
Common rating scales often include preference rankings, numerical ratings, or iterative reviews. The ideal scale depends on how you’re collecting feedback and what you aim to achieve with your evaluation. These tools are particularly useful for turning human feedback into measurable data, helping refine LLM performance.
How do I measure rater agreement?
To assess how well human evaluators agree when reviewing model outputs, it's important to measure their consistency. Metrics such as inter-rater reliability scores are often used for this purpose. Popular methods include Cohen's Kappa and Krippendorff's Alpha, which both account for agreement that goes beyond random chance. These tools help ensure that human feedback is dependable and consistent, which is essential for turning subjective judgments into measurable evaluation metrics.



