

Human feedback is key to making large language models (LLMs) more accurate, safe, and aligned with user expectations. It involves real people evaluating and refining model outputs, ensuring they meet practical needs and avoid mistakes like hallucinations or harmful responses. This often starts with mastering prompt engineering concepts to set clear constraints.
Here’s what you need to know:
-
Reinforcement Learning with Human Feedback (RLHF): This process uses human rankings to guide models toward better performance. For instance, OpenAI’s InstructGPT showed that smaller models could outperform larger ones when fine-tuned with human feedback.
-
Constitutional AI(CAI): Reduces the need for extensive labeling by using predefined principles to guide models. It improves safety and transparency while requiring less human intervention.
-
Efficiency Gains: Methods like Direct Preference Optimization (DPO) cut training time by 66% while maintaining or improving performance.
-
Challenges: Human feedback can be subjective, costly, and time-consuming, but structured tools like Latitude help streamline the process.
Bottom Line: Incorporating human feedback into LLM fine-tuning improves accuracy, reduces errors, and ensures models behave as intended. Tools and workflows make it easier to scale this process for production use.
Research Studies on Human Feedback in LLM Fine-Tuning
Reinforcement Learning with Human Feedback (RLHF)
RLHF fine-tunes large language models (LLMs) to better align with human intent. This process involves three steps: supervised fine-tuning, where the model learns from labeled data; ranking outputs based on human feedback; and refining the model’s behavior using Proximal Policy Optimization (PPO).
In January 2022, OpenAI introduced InstructGPT, showcasing the effectiveness of RLHF. Surprisingly, human evaluators preferred responses from a smaller 1.3 billion–parameter InstructGPT model over those from the much larger 175 billion–parameter GPT-3. This achievement came despite the smaller model using over 100 times fewer parameters. Even more impressively, the RLHF process required less than 2% of the computational resources used during the original pretraining. This suggests that RLHF doesn’t add new capabilities but instead helps models better align with human expectations, effectively “unlocking” their potential.
Meta’s Llama 2-Chat, released in July 2023, introduced additional advancements. It utilized two separate reward models - one focused on helpfulness and the other on safety - and incorporated a rejection sampling step. This ensured that the model was trained only on the most highly rewarded outputs. Typically, training a reward model requires around 50,000 labeled samples, often pairing a 175B LLM with a smaller 6B reward model. These developments have paved the way for alternative methods like Constitutional AI.
Constitutional AI and Its Contributions
Anthropic’s Constitutional AI (CAI) offers a different approach to reducing reliance on extensive human labeling. Instead of requiring thousands of labeled outputs, CAI uses a “constitution” - a set of high-level principles defined by humans - to guide the model’s behavior.
This method operates in two phases. First, the model critiques and revises its own outputs based on the constitution. Then, the AI generates preference data, which is used to train a reward model through Reinforcement Learning from AI Feedback (RLAIF).
“The only human oversight is provided through a list of rules or principles, and so we refer to the method as ‘Constitutional AI’.” - Anthropic
CAI significantly improves scalability by reducing the need for human-labeled data. It also trains models to be “harmless but non-evasive”, meaning they don’t simply reject sensitive queries but instead explain the ethical reasoning behind their responses. Additionally, CAI incorporates chain-of-thought reasoning, which enhances transparency in decision-making.
Other Research Findings
Beyond RLHF and CAI, researchers are exploring new ways to optimize human feedback mechanisms. For example, a 2025 study found that span-level feedback increased annotation time by only 9% but generated over nine times more training pairs per response. Columbia University researchers proposed a “Lamarckian” approach, where human feedback helps models iteratively refine their outputs. This method creates “improvement chains” that are more efficient than traditional feedback systems.
Another innovation, Mixed Preference Optimization (MPO), combines Direct Preference Optimization for datasets with large reward gaps and online RLHF for challenging examples. This hybrid workflow addresses distribution shifts in production settings, making human feedback more practical for real-world applications. These advancements are helping to streamline feedback processes and improve the overall efficiency of model training.
Results and Insights from Human Feedback Experiments
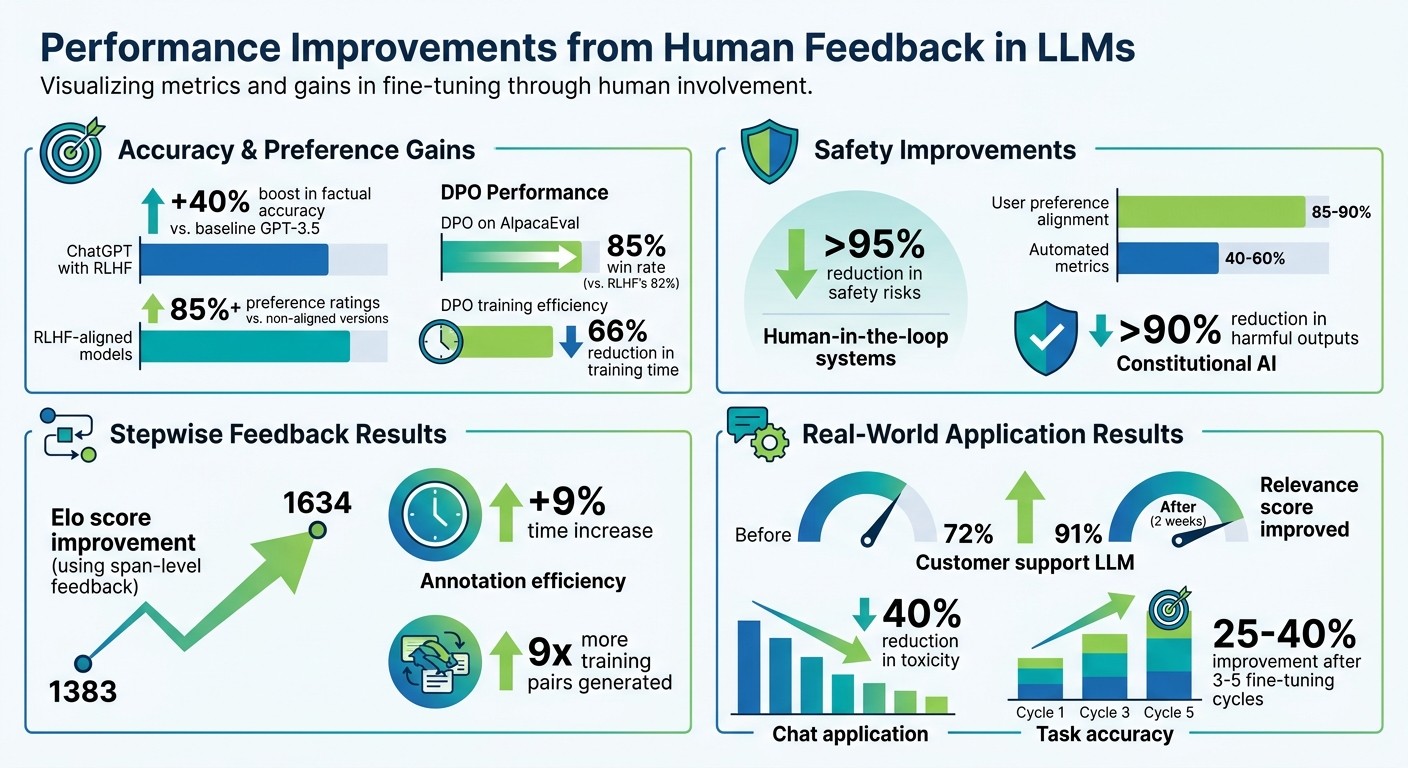
Human Feedback Impact on LLM Performance: Key Metrics and Improvements
Performance Improvements After Feedback
Incorporating human feedback has proven to significantly enhance both accuracy and user preference metrics. For example, ChatGPT, which utilizes Reinforcement Learning from Human Feedback (RLHF), saw a 40% boost in factual accuracy when compared to the baseline GPT-3.5 model. RLHF-aligned models consistently achieve preference ratings of 85% or higher , showcasing their effectiveness over non-aligned versions.
Direct Preference Optimization (DPO) has emerged as a more efficient alternative to traditional RLHF. On AlpacaEval, DPO delivered an 85% win rate , outperforming RLHF’s 82%, while also cutting training time by 66%.
Safety enhancements are another major benefit. Human-in-the-loop systems significantly reduce safety risks - by over 95% - and achieve 85–90% alignment with user preferences , far surpassing automated metrics, which typically range between 40–60%. Additionally, Constitutional AI has demonstrated its ability to lower harmful outputs by more than 90%.
A 2025 study highlighted the potential of stepwise span-level feedback, which boosted the Elo score from 1383 to 1634. This approach, described as “Lamarckian” due to its focus on inheriting useful adaptations during revisions, enables models to refine themselves with fewer training cycles, improving alignment and efficiency.
These advancements not only refine model accuracy and safety but also pave the way for their application in demanding production environments.
Use Cases and Applications
The benefits of human feedback extend beyond performance metrics, offering practical advantages across various applications. In customer service, for instance, RLHF ensures responses are more helpful and contextually appropriate, addressing user concerns effectively rather than deflecting sensitive queries.
In content generation, feedback plays a critical role in refining tone, style, and factual accuracy. This allows models to be continuously improved in production environments without overburdening annotation teams, creating a sustainable feedback loop.
Multi-agent systems are also reaping the rewards of targeted feedback. By identifying and improving underperforming agents within larger systems, teams can make precise adjustments without retraining entire architectures. This approach not only cuts computational costs but also preserves overall system performance.
Challenges and Limitations of Human Feedback
Annotation Bias and Subjectivity
Human feedback comes with its own set of hurdles. Annotators inevitably bring their personal experiences, cultural influences, and individual tastes to the table, which can lead to inconsistencies in the training data. For instance, when multiple reviewers assess the same model output from top LLMs, their opinions on what makes a response “good” or “helpful” often differ. This subjectivity can nudge the model toward catering to a narrow set of preferences, potentially leaving out the diverse needs of a wider audience. A good example of this is when annotators lean heavily toward formal language - this could make it harder for the model to produce more relaxed, conversational responses when the situation calls for it.
Cost and Scalability of Feedback Collection
Gathering human feedback isn’t just labor-intensive; it’s also expensive. Professional annotators can charge anywhere from $20 to $200 per hour, turning large-scale feedback efforts into a costly endeavor. Compare this to automated metrics, which cost mere pennies per evaluation. However, automated tools often miss nuances and edge cases that human reviewers are better equipped to catch. Another challenge is the time required - human reviews can take days or even weeks, which slows down workflows that thrive on quick iteration cycles. Interestingly, span-level feedback, where annotators highlight specific sections of text they like or dislike, offers more actionable insights while only slightly increasing the time required compared to simpler A/B ranking methods.
Addressing Challenges with Structured Tools
Structured tools and workflows can ease these challenges while maintaining high-quality feedback. Fine-grained span-level feedback, for example, allows reviewers to identify exactly which parts of a response work well and which don’t. This reduces ambiguity and provides clearer training signals. Standardizing the feedback process in this way can also help minimize the influence of individual biases. Platforms like Latitude offer solutions by combining systematic workflows for observing model behavior, collecting targeted feedback, and conducting evaluations. By blending automated monitoring with carefully planned human reviews, teams can strike a balance between capturing nuanced insights and meeting production demands. This approach creates a more efficient system for integrating feedback into fine-tuning workflows.
Integrating Human Feedback into Production Fine-Tuning Workflows
Observing and Debugging Model Behavior in Production
When integrating human feedback into production workflows, the first step is understanding how your model behaves in real time. Observability tools are key here - they log inputs, outputs, and interactions, revealing patterns that automated metrics might overlook. Teams usually monitor metrics like latency, error rates, token usage, and output quality scores to catch issues early. On a daily basis, production teams review 5-10% of anomalous outputs, focusing on edge cases where the model might hallucinate, wander off-topic, or produce biased responses.
Tools like LangSmith, Phoenix, and Grafana play a big role in spotting specific failure modes by analyzing traces of LLM calls. Common problems include factual inaccuracies - initial deployments often show hallucination rates as high as 15-20% - and context drift, where the model strays from key elements in the prompt. To address these, teams use semantic similarity checks and embedding drift detection. For instance, if a cosine similarity score drops below 0.7 for relevant responses, it triggers alerts. These alerts guide teams to collect precise human feedback on problematic interactions, providing the groundwork for expert-driven improvements at scale.
Structured Feedback Collection with Latitude
Once problematic outputs are flagged, the next step is gathering expert feedback in a way that scales effectively. Latitude offers a dashboard where domain experts can label LLM outputs using custom rubrics - like scoring accuracy or helpfulness on a 1-5 scale - and conduct A/B tests with different prompts. The platform exports feedback datasets in RLHF-compatible formats like JSONL, making it seamless to incorporate annotations into fine-tuning workflows. Most teams annotate 100-500 examples weekly, which can reduce error rates by 20-30% over iterative cycles.
Latitude’s SDK enables teams to log live predictions from their LLMs for review. Domain experts can evaluate these outputs on specific criteria, such as medical accuracy, and compile scores and comments into structured datasets. Built-in evaluation tools allow teams to compare model versions and fine-tune using integrated trainers. For example, a customer support LLM improved its relevance score from 72% to 91% in just two weeks of structured feedback collection. Once feedback is collected, continuous evaluation ensures these gains are not only achieved but also maintained over time.
Continuous Evaluation and Iteration
After collecting structured feedback, the focus shifts to continuous evaluation - monitoring and refining model performance in real time. This step helps detect model drift and measure the impact of feedback. Metrics like BLEU or ROUGE for generation quality, human preference win rates (targeting 60% or higher), and domain-specific evaluations become essential. Automated evaluation suites should run after every feedback cycle, flagging regressions if scores drop by more than 5%.
The most effective workflows combine automation with human oversight. Automated methods, such as using models like GPT-4 to score outputs at scale, are validated against human benchmarks with a correlation above 0.8. Periodic human audits - covering around 10% of evaluations - help capture subtleties that automation might miss. A/B testing fine-tuned models against baselines ensures improvements are validated before full deployment. For instance, weekly evaluations in one chat application reduced toxicity by 40%. According to a 2024 Hugging Face report, companies using this iterative approach saw task accuracy improve by 25-40% after 3-5 cycles of fine-tuning.
Conclusion
Key Takeaways
Incorporating human feedback is crucial for developing large language models (LLMs) that align with practical expectations and perform reliably in real-world environments. Techniques like Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO), and Guidance through Preference Optimization (GRPO) each address different needs, from capturing human subtleties to improving training efficiency. A newer method, Reinforcement Learning from Verifiable Rewards (RLVR), focuses on objective accuracy by using verifiable checks, such as passing code tests or solving math proofs, to evaluate performance. Recent innovations, including systems like DeepSeek-R1 and OpenAI o1, showcase progress in step-by-step reasoning.
To effectively integrate human feedback into production workflows, a structured approach is necessary. This includes robust observability to detect edge cases, expert annotation through tools like Latitude for collecting high-quality feedback, and continuous evaluation to track and refine improvements. Balancing quantitative metrics for benchmarking with qualitative insights for debugging is key to shaping model behavior. Together, these elements - observability, expert feedback, and ongoing evaluation - create a framework for adapting LLMs to real-world applications.
Next Steps
Here’s how to put these ideas into action. Start by identifying your LLM’s weak points, such as hallucinations, irrelevant responses, or errors in specialized areas. Then, establish regular feedback cycles that combine automated evaluations with human input.
For projects where consistent quality is non-negotiable, consider using Latitude to simplify feedback collection and streamline evaluation and fine-tuning processes. The ultimate goal is to build a continuous feedback loop, where every interaction in production becomes an opportunity for learning and improvement. This ensures your LLM can keep pace with evolving user needs and expectations.
FAQs
When should I use RLHF vs DPO?
Reinforcement Learning from Human Feedback (RLHF) is perfect for aligning models with more intricate human preferences. It’s especially useful for tasks that demand ongoing, detailed feedback. By incorporating this iterative approach, RLHF can help tackle challenges like minimizing hallucinations or addressing biases in AI responses.
On the other hand, Direct Preference Optimization (DPO) is a straightforward alternative for less complex tasks. This method skips reinforcement learning entirely, instead focusing on preference comparisons to fine-tune models. DPO works well when resources are tight or when the task doesn’t require deep, iterative refinement.
How much human feedback is needed to fine-tune an LLM?
The level of human feedback needed varies depending on the method being used. However, studies indicate that well-curated feedback , like rankings, ratings, and iterative reviews, plays a crucial role in aligning models more closely with human preferences. Interestingly, even a relatively small but carefully chosen dataset can lead to noticeable improvements in fine-tuning processes.
How do I reduce annotator bias in feedback?
To reduce annotator bias, it’s essential to implement structured review processes that involve diverse panels. This approach ensures that feedback reflects a variety of perspectives across different demographics. Using clear evaluation criteria and rubrics can also help minimize subjective differences, making assessments more consistent. Additionally, it’s important to regularly monitor and validate feedback workflows. This allows you to spot and address any potential biases, ultimately supporting efforts to make the process more balanced and equitable over time.