

Automated LLM evaluation pipelines are essential for maintaining the quality of AI outputs at scale. Instead of manually reviewing thousands of responses, these pipelines use structured workflows to test and score outputs against predefined standards. By leveraging programmatic checks, semantic analysis, and LLM-based evaluations, you can ensure your model delivers consistent, accurate, and safe results.
Key Takeaways:
-
Automated Pipelines : Test LLM outputs for tone, accuracy, safety, and formatting without human intervention.
-
Golden Datasets : Use real-world examples and edge cases to benchmark performance.
-
Layered Checks : Combine deterministic rules, heuristic scoring, and LLM-as-a-judge methods to evaluate outputs.
-
CI/CD Integration : Embed evaluations into your development pipeline to catch issues before deployment.
-
Human Oversight : Include human reviews for high-risk or subjective cases.
These steps ensure that your LLM-powered applications perform reliably, scale efficiently, and meet user expectations. Read on for a detailed guide to building and automating these pipelines.
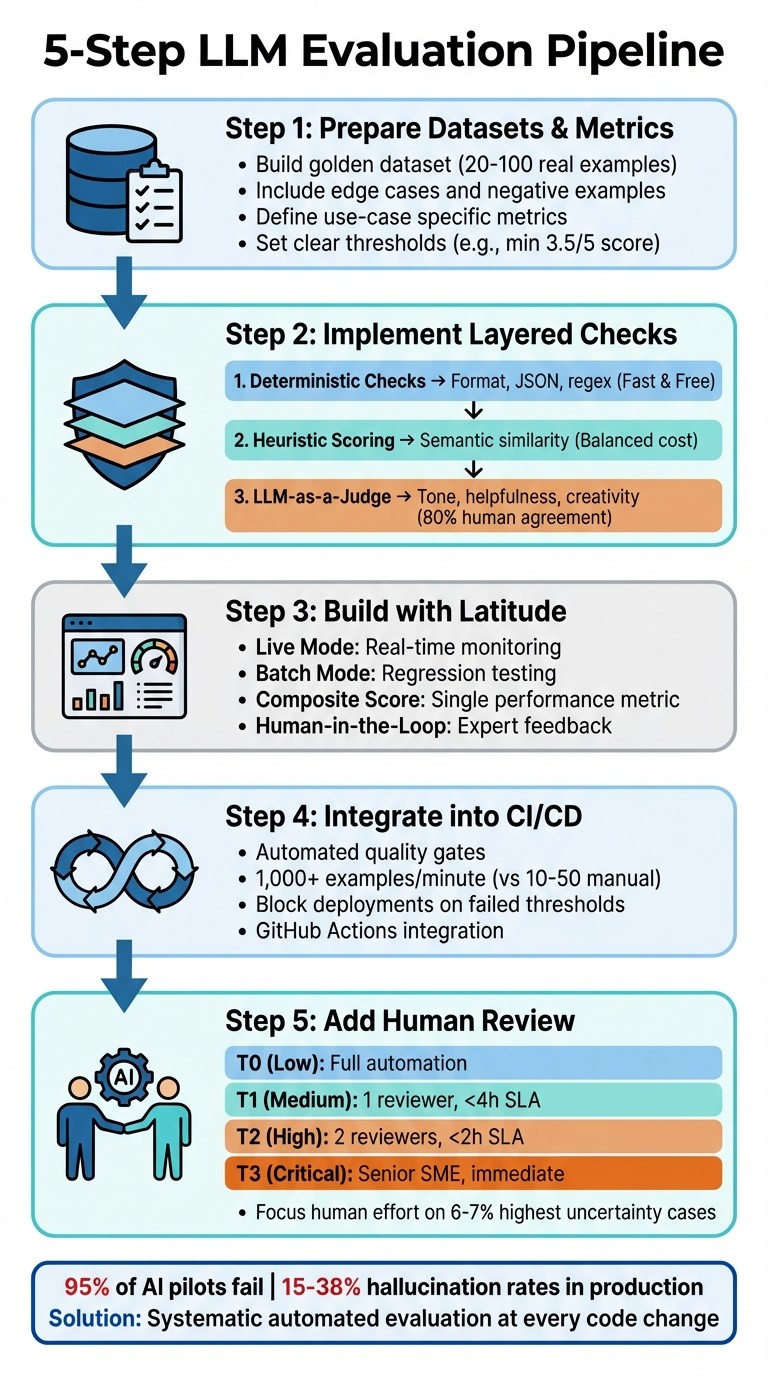
5-Step LLM Evaluation Pipeline Implementation Process
Step 1: Prepare Your Evaluation Datasets and Metrics
Creating a reliable pipeline starts with building strong datasets and defining clear metrics. This foundation ensures your pipeline identifies issues effectively, rather than giving you a false sense of security.
Select the Right Datasets
The most effective datasets come directly from production logs, capturing real user interactions and edge cases. Start by collecting a sample of actual requests and responses from your application. Alok Kumar from AI Engineer Lab emphasizes:
“A model that performs well on public datasets might fail when exposed to your prompts, your documents, and your users’ behavior.”
Testing just 30 high-quality, real-world examples can uncover significant performance differences between models. Focus on quality over quantity - begin with 20–100 examples that represent a range of user intents. Include edge cases and “negative” examples, such as those that highlight undesirable outputs like toxicity or hallucinations.
Once you’ve created this golden dataset , treat it as your go-to benchmark for regression testing. Any time your LLM produces a problematic output in production, add that input to your golden dataset to avoid repeating the same issue. If real data doesn’t cover certain scenarios, fill the gaps with synthetic data generated by AI to test unseen variations.
With your dataset ready, the next step is to define metrics that reflect your specific needs.
Define Your Evaluation Metrics
Your evaluation metrics should directly tie to your use case. For instance, a customer support bot might prioritize helpfulness and tone, while a code generator would focus on accuracy and formatting. Key dimensions to track include correctness, safety, completeness, and adherence to brand voice.
Alok Kumar compares evaluation to unit testing:
“Think of evaluation as unit testing for AI systems. It protects your product from regressions as models, prompts, and datasets evolve.”
Choose metrics that can be consistently monitored over time, and set clear thresholds. For example, you might require a minimum score of 3.5 out of 5 before deploying to production. This ensures you maintain a high standard while adapting to changing needs.
Once your metrics are in place, make sure your dataset includes enough variety to test these dimensions thoroughly.
Ensure Dataset Diversity
Use metadata tags to organize examples by type (factual, creative, reasoning, safety) and difficulty level (easy, medium, hard). This approach helps you identify specific weaknesses, like a model excelling at simple queries but struggling with complex reasoning.
Incorporate examples that push your model’s limits: straightforward requests, ambiguous phrasing, adversarial inputs, and queries requiring multiple skills. Regularly update your golden dataset as you uncover new failure modes in production. Treat this dataset as a living document that evolves with your product and user base, ensuring your evaluations stay relevant and comprehensive.
Step 2: Implement Layered Evaluation Checks
Relying on just one evaluation method won’t cut it. The best systems use multiple layers of checks, starting with quick, low-cost methods and moving to more advanced techniques only when necessary. This approach keeps things efficient while ensuring thorough coverage.
Set Up Deterministic Checks
Think of deterministic checks as your first safety net. These checks handle structural requirements like ensuring JSON schema adherence, staying within character limits, and matching regex patterns consistently. They’re reliable because they deliver the same result every time, making them ideal for catching format issues and length violations. Tools like Latitude are great for managing this process.
Run these checks in two modes:
-
Live Mode : For real-time monitoring.
-
Batch Mode : For regression testing.
Set strict thresholds - like a minimum score of 3.5 out of 5 or a simple pass/fail. If scores fall below this limit, trigger alerts. To keep things running smoothly, integrate these checks into your CI/CD pipeline to block deployments if new prompt versions fail to meet objective metrics. Since deterministic checks are incredibly fast and nearly free, they’re a no-brainer.
Apply Heuristic Scoring for Semantic Evaluation
Once the basic structure is validated, move on to semantic evaluation using heuristic scoring. This step focuses on meaning rather than just surface-level text matching. By comparing outputs to a golden dataset, you can ensure the response conveys the right information, even if the wording isn’t identical.
To make this work, build a library of 15–20 high-quality examples that cover key scenarios. These examples set the standard for semantic similarity scoring. Use:
-
Pointwise Scoring : For ongoing production monitoring.
-
Pairwise Comparisons : For A/B testing.
Heuristic scoring strikes a balance between rigid deterministic checks and the higher costs of LLM evaluations. It’s a middle ground that effectively identifies semantic issues without breaking the bank.
Use LLM-as-a-Judge Methods
For the final layer, bring in an LLM to evaluate aspects like tone, helpfulness, and creativity. As David Montague from Pydantic puts it:
“Evaluation is easier than generation - the judge sees both question and answer, making it a much narrower task than open-ended generation”.
LLM judges can match human evaluators about 80% of the time, which is similar to the agreement rate between two human reviewers.
Here’s how to structure your evaluation pipeline:
-
Start with inexpensive deterministic checks.
-
Move to heuristic scoring for semantic validation.
-
Use LLM evaluations only after clearing the earlier steps.
Set the LLM’s temperature to 0 for consistent scoring. Always instruct it to explain its scores - this helps debug issues and refine your evaluation criteria.
Be mindful of potential biases:
-
LLMs can favor verbose answers or inflate scores by 5–7%.
-
Position effects can cause up to 40% inconsistency.
To counter these, use a judge model from a different family than your generator and run pairwise comparisons twice, swapping the order each time.
| Scenario | Evaluator Type | Reason |
|---|---|---|
| Format/JSON Validation | Programmatic Rule | Fast, cheap, and completely consistent. |
| Tone & Style | LLM-as-a-Judge | Regex can’t handle this; applies broadly to all outputs. |
| Hallucination Detection | LLM-as-a-Judge | Requires comparing output meaning to the original source. |
| High-Stakes Medical/Legal | Human-in-the-Loop | LLMs lack the expertise and reliability needed for critical domains. |
| Regression Testing | LLM-as-a-Judge | Captures nuanced expectations for specific test scenarios. |
Step 3: Build and Automate Evaluations with Latitude
Bring all your evaluation checks together on one platform. Latitude, an open-source AI engineering tool, combines observability, automated evaluations, and structured feedback collection - making it easier to manage everything in one place.
Monitor LLM Behavior with Latitude
Understanding how your LLM performs in real-world scenarios is critical. Latitude’s monitoring tools let you track performance when real users interact with your model. The platform offers two modes: Batch Mode for regression tests and Live Mode for continuous monitoring.
For essential metrics like safety checks and format validation, you can enable Live Evaluation in the settings. This feature automatically runs checks on every production request - even without ground truth data - so you can catch regressions as they happen. Latitude supports multiple evaluation methods, including LLM-as-Judge for subjective analysis, Programmatic Rules for objective criteria, and Human-in-the-Loop for expert input. These results can be combined into a single Composite Score , giving you a clear, high-level summary of your prompt’s performance.
This comprehensive monitoring lays the groundwork for deeper human insights.
Collect Human Feedback for Better Evaluations
Automated checks can only go so far. To catch subtleties that algorithms might miss, Latitude enables you to collect structured feedback from domain experts. Whether it’s legal professionals reviewing contract summaries or customer service managers analyzing chatbot interactions, human input adds depth to your evaluations.
Expert reviews can also refine your golden datasets with validated examples. While these evaluations require active participation and aren’t suited for live mode, they are crucial for batch testing - especially when comparing prompt versions or transitioning to new models. Traits like toxicity or hallucinations can be flagged as “negative” in Latitude’s settings, allowing the platform to optimize for lower scores on those metrics.
Automate Continuous Improvement
Improvement comes from closing the feedback loop. Latitude helps you connect observation, evaluation, and iteration into a continuous cycle. For example, you can trigger batch evaluations whenever you update a prompt. The Composite Score makes it easy to spot which updates enhance performance and which might introduce problems.
You can also integrate these evaluations into your development workflows. Use live evaluations for quick safety and formatting checks, while batch mode - with curated test cases - handles more in-depth assessments like tone or helpfulness. This approach ensures thorough coverage while keeping costs manageable.
Step 4: Integrate Evaluations into CI/CD Workflows
Why Add Evaluations to CI/CD Pipelines
Adding evaluations into your CI/CD pipeline acts as a built-in quality checkpoint, ensuring issues like broken prompts or reduced model performance are caught before reaching production. These automated quality gates enforce specific thresholds, stopping builds from moving forward if standards aren’t met.
Here’s the reality: 95% of AI pilots fail , and production hallucination rates can range between 15% and 38%. Manual evaluations just can’t keep up with the speed of development. While manual testing might handle 10–50 examples per hour, automation can process 1,000+ examples per minute. By embedding evaluations into your workflow, you switch from reacting to problems after they occur to proactively maintaining quality.
“The best LLM applications aren’t built through endless manual testing sessions. They’re built through systematic, automated evaluation that runs with every code change.” - Braintrust Team
Tools and Steps for CI/CD Integration
To integrate evaluations into your CI/CD setup, you’ll need three key components: a golden dataset of test cases, evaluation metrics (your rubrics), and an automated runner like a CLI tool or GitHub Action. For instance, GitHub Actions can execute evaluations on every pull request, immediately flagging any quality changes.
Here’s how to get started:
-
Use GitHub Actions to automate evaluations. Store your LLM provider API keys as encrypted environment secrets in your CI/CD platform to ensure security.
-
Implement caching strategies to cut API costs and speed up evaluation runs.
-
Configure your pipeline to exit with a non-zero code if thresholds aren’t met, effectively blocking merges when quality standards fail.
For a layered approach, combine quick, deterministic checks (like JSON validity or PII detection) with more complex statistical metrics (such as BLEU or ROUGE). You can also use LLM-as-a-judge methods for deeper semantic evaluations.
Once your CI/CD integration is in place, the next challenge is scaling these evaluations.
Scale Your Evaluation Process
After embedding evaluations into your workflow, scalability becomes essential as your model evolves. Start by running smoke tests - a small set of critical test cases - on pull requests for fast feedback, while scheduling full evaluation suites to run nightly. This method strikes a balance between speed and thoroughness.
To handle larger workloads, parallelize testing with matrix strategies in GitHub Actions. This allows you to test multiple models (e.g., GPT-4 vs. Claude-3) or configurations at the same time. Compare new results against baseline reports to identify subtle quality changes over time. If you’re using LLM-as-a-judge in CI/CD, first validate its accuracy by measuring alignment with human labels using metrics like True Positive Rate (TPR) and True Negative Rate (TNR).
Keep practicality in mind. While small sample sizes (like 5 cases) don’t offer much statistical confidence, evaluating 20–30+ cases provides a solid basis for production decisions. To maintain performance, set a Time-To-Live (TTL) for evaluation caches - 24 hours, for example - to allow for periodic fresh evaluations while keeping tests efficient.
Step 5: Add Human-in-the-Loop Review
After setting up automated checks and integrating CI/CD, adding human oversight ensures quality in areas where precision and judgment are crucial.
When to Use Human Review
While automation can handle large volumes efficiently, it falls short in tasks that require nuanced decision-making. Human reviewers are essential for high-stakes scenarios, complex edge cases, and evaluating subjective elements like tone, creativity, or cultural appropriateness.
A smart way to manage this is through a risk-tiered approach. For example, low-risk tasks like simple summarization can rely on full automation, while medium- and high-risk cases - like legal advice or regulatory compliance - should involve human oversight. This method not only maintains quality but can also cut review costs by 40–55%. By combining automation with targeted human input, you can address the subtleties that machines might overlook.
Design Effective Feedback Loops
To make human reviews impactful, start with structured guidelines:
-
Annotation playbooks : Use detailed rubrics, such as a 1–5 scale, to guide reviewers.
-
Golden datasets : Create a reference set of 200–500 examples to ensure calibration and monitor drift.
Streamline the review process with tools like thumbs up/down buttons, “suggest edit” options with captured changes, and hotkeys to minimize fatigue. Set clear service-level agreements (SLAs) based on urgency. For instance, live support escalations might require a response in under 2 minutes, whereas asynchronous reviews could allow up to 4 hours. Every piece of feedback should lead to action - whether that means tweaking a prompt, retraining the model, or updating safety measures.
Teams that run weekly retraining cycles report quality improvements that are 2.1x faster compared to monthly updates. Calibration sessions, where reviewers align on rubrics and discuss edge cases, further enhance consistency. In critical fields like law or medicine, a double-review process with two independent reviewers and an arbitration mechanism can ensure accuracy and fairness.
Balance Automation with Human Oversight
The key to success lies in a hybrid approach. Use automation to handle objective errors (e.g., formatting issues or safety violations) and leverage large language models (LLMs) for scalable evaluations of subjective qualities. Reserve human input for the 6–7% of outputs with the highest uncertainty. This layered strategy combines the efficiency of machines with the expertise of human reviewers.
To maintain high standards, start with binary thresholds, like PASS/FAIL judgments from experts. Rotating reviewers across categories can prevent burnout and keep annotations consistent.
| Tier | Risk Level | SLA | Reviewer Requirement | Example Use Case |
|---|---|---|---|---|
| T0 | Low | Auto | 0 Reviewers | Simple summarization, low-risk Q&A |
| T1 | Medium | <4h | 1 Reviewer | General customer support responses |
| T2 | High | <2h | 2 Reviewers | Legal, financial, or medical advice |
| T3 | Critical | Immediate | Senior SME | Safety incidents, regulatory compliance |
Best Practices for LLM Evaluation Pipelines
Building effective automated evaluation pipelines requires careful planning, consistent updates, and teamwork across your organization. These practices help ensure your process stays reliable as your product grows.
Combine Quantitative and Qualitative Evaluations
The strongest pipelines blend quantitative and qualitative methods. Quantitative evaluations - such as deterministic format checks and heuristic scoring - are fast, scalable, and perfect for CI/CD workflows. However, they often miss subtleties like tone or creative reasoning. On the other hand, qualitative approaches, including human reviews and LLM-as-a-judge methods, excel at capturing subjective elements like nuance and ethical considerations. Pairwise comparisons, rather than absolute scoring, tend to produce more consistent qualitative results.
A well-rounded pipeline typically includes four layers:
-
Deterministic checks : Catch formatting issues and personal data leaks.
-
Heuristic scoring : Measure semantic similarity.
-
LLM-as-a-judge : Evaluate subjective qualities.
-
Human reviews : Handle edge cases and complex decisions.
This layered approach merges the speed of automation with the depth of human insight.
| Method Type | Strengths | Limitations |
|---|---|---|
| Quantitative (Deterministic/Heuristic) | Fast, objective, scalable, and cost-effective; ideal for CI/CD gating. | Misses nuances, tone, and complex reasoning; “exact match” criteria often fall short. |
| Qualitative (Human/LLM-as-Judge) | Captures nuance, coherence, and ethical implications; aligns closely with human judgment. | Can be slow, costly, and harder to scale; LLM judges may show position bias. |
By combining these methods, your pipeline can balance efficiency and thoroughness, setting the stage for continuous improvement.
Iterate on Your Evaluation Process
Your pipeline should grow and adapt with your product. Begin with a golden dataset of 15–20 high-quality examples that reflect key use cases and edge cases. Over time, expand this to 200–500 examples, ensuring at least 30% are challenging or adversarial cases rather than straightforward scenarios.
“The single most important thing in LLM evaluation is your dataset. Bad evals with good data beats good evals with bad data every time.”
– Jeffrey Ip, Cofounder, Confident AI
To keep your evaluation suite relevant, regularly review production logs for negative interactions and edge cases. When testing prompt variants, use statistical methods like the Wilcoxon signed-rank test (instead of a t-test), as LLM scores are typically ranked rather than normally distributed. A p-value below 0.05 indicates that observed improvements are statistically significant.
Set up drift detection to monitor quality over time. For instance, automate alerts if daily average scores drop by more than 1% over a rolling window. Just like source code, version your prompts and evaluation datasets to ensure reproducibility and track changes effectively.
Enable Cross-Team Collaboration
As your evaluation process becomes more sophisticated, collaboration across teams is crucial. Product managers, engineers, and domain experts need to align on goals and methods. A shared golden dataset acts as a single source of truth, integrating diverse inputs, expected outputs, and tricky edge cases.
To streamline decision-making, follow the “5 Metric Rule” : track 1–2 custom metrics specific to your use case and 2–3 general system metrics. Too many metrics can overwhelm teams and slow progress. Assign clear ownership for managing risks and performance, and document your testing procedures so all team members understand their roles.
Incorporate evaluation results into your standard review process. Just as code changes require peer review, updates to prompts or models should include evaluation outcomes as part of the approval workflow. Use centralized prompt management tools with version control and side-by-side comparison features to help product managers and engineers collaborate effectively. Regular cross-functional meetings to review trends and refine criteria can further strengthen your pipeline.
“Evaluation becomes intentional rather than reactive when objectives are established in advance.”
– Avinash Chander
Conclusion
Creating an automated LLM evaluation pipeline demands a steady focus on maintaining quality and reliability. Start with a golden dataset that addresses both core use cases and edge scenarios, and expand it as your product evolves.
From there, use a combination of programmatic checks, LLM-as-a-judge methods, and human reviews to gain a well-rounded view of your model’s performance.
“Evaluation isn’t about finding a single ‘accuracy’ number. It’s about measuring multiple quality dimensions - correctness, tone, safety, completeness - and tracking each one over time.”
This insight from MachineLearningPlus highlights the importance of assessing various aspects of quality - like correctness, tone, safety, and completeness - over time.
To ensure meaningful results, establish clear measurement standards rather than relying on vague rating scales. Define each score level with observable traits, set minimum quality thresholds (e.g., a score of 3.5 out of 5), and use drift checks to flag when scores deviate significantly from the baseline. Validate improvements with statistical testing to confirm progress.
Monitor negative metrics, such as toxicity and hallucinations, aiming to minimize them as much as possible. Real-time monitoring in production is also critical to detect performance drifts caused by model updates or unexpected user interactions. These strategies help your pipeline adapt to the changing needs of your product and users.
Collaboration across teams is essential for success. Product managers, engineers, and domain experts should have shared access to evaluation results, clear accountability for quality metrics, and regular discussions on trends. This teamwork ensures that evaluation processes can scale effectively. With tools like Latitude, you can build a structured workflow to observe model behavior, gather human feedback, run evaluations, and continuously refine your LLM-powered features.
FAQs
How do I choose the right metrics for my LLM app?
Choosing the right metrics starts with understanding your evaluation goals and the specific qualities you want to measure - whether that’s accuracy , safety , or relevance. Metrics like accuracy , precision , recall , and F1 scores provide a way to quantify performance effectively. Latitude’s framework offers flexibility by supporting both objective evaluations and subjective assessments, making it easier to tailor metrics to match your app’s unique requirements.
How big should my golden dataset be to start?
Creating a golden dataset means striking the right balance between thoroughness and practicality. It should include examples that address critical scenarios as well as those tricky edge cases, all while staying manageable in size. The goal? To make sure your dataset mirrors real-world use cases closely enough to provide a dependable evaluation.
A smart approach is to start small. Begin with a targeted selection of high-quality examples that cover the most important scenarios. From there, you can gradually expand, adding more examples to improve both coverage and reliability as your needs evolve. This way, you build a dataset that’s both focused and adaptable over time.
How can I reduce bias in LLM-as-a-judge scoring?
To make scoring systems fairer and more balanced, it’s essential to use strategies like calibration, guardrails, and alignment techniques. Start by calibrating evaluators to reflect human preferences accurately. Introduce guardrails to minimize potential biases, and use counter-prompts as a way to check for any unintended bias in the system.
Aligning LLM evaluators with human annotations is another critical step. This helps maintain consistency and ensures fairness across evaluations. Additionally, carefully designed evaluation templates and the use of multiple evaluation methods can strengthen the process. Regular monitoring for bias is key to keeping scoring systems as fair and impartial as possible.