

Cross-domain model transfer is about making large language models (LLMs) work effectively across different fields, like switching from customer support to legal analysis. However, transferring models, prompts, or fine-tuned modules isn’t straightforward. Common issues include performance drops, domain mismatches, and “catastrophic forgetting”, where models lose prior knowledge when trained on new tasks.
Key strategies to address these challenges include:
-
LoRA(Low-Rank Adaptation): Cuts costs by 90% and maintains performance by freezing most parameters and training only small matrices.
-
Self-Training with Pseudo-Labeling: Uses unlabeled data to scale training efficiently but requires careful management of noisy labels.
-
Mixed-Domain Reinforcement Learning: Improves domain-specific tasks by using AI-generated feedback loops.
-
Tools likeLatitude: Provide real-time monitoring and feedback for better model performance tracking.
Each method has its strengths, depending on the task, budget, and domain requirements. Combining these approaches can significantly improve cross-domain transfer while reducing costs and preserving model quality.
Challenges in Cross-Domain Model Transfer
Domain Shift and Distribution Mismatch
When transferring a large language model (LLM) to a new domain, the model often encounters data that it wasn’t originally built to handle. This mismatch leads to gradient interference , where the model’s existing knowledge clashes with the new information it needs to learn. Studies reveal that 67% of parameters in attention query and key projection matrices can experience this conflict during the adaptation process. Essentially, the model struggles to balance what it already knows with the demands of the new domain.
Another issue is representational drift , where the model’s internal representations shift significantly. For instance, dominant subspaces in intermediate layers can rotate by 35 to 52 degrees during adaptation. Imagine trying to navigate with a compass that suddenly points in the wrong direction - this is how the model’s internal “sense of direction” gets disrupted. Compounding the problem, the loss landscape becomes flatter during cross-domain adaptation. Maximum Hessian eigenvalues, a measure of curvature, can drop dramatically from 147.3 to 34.2, making it harder for the model to retain its original domain knowledge.
Semantic Gap in Embeddings
LLMs depend on pre-trained vocabularies that often fall short when dealing with specialized fields like medicine or law. This results in fragmented tokenization , where domain-specific terms are broken into subunits that lose their meaning, reducing the model’s ability to understand these terms effectively. As Jian Gu and colleagues explain:
“Semantic alignment in latent space is the fundamental prerequisite for LLM cross-scale knowledge transfer”.
Without proper alignment, the model ends up working with a mismatched “dictionary.” Lower layers of the model, which handle grammar and syntax, and upper layers, which focus on task-specific behaviors, fail to adapt to the new vocabulary. This mismatch widens the semantic gap, leaving specialized domains isolated from the benefits of broader, high-resource tasks because their structures don’t align.
Catastrophic Forgetting During Adaptation
Unlike human brains, which use modular structures to organize knowledge, neural networks store everything in a single set of shared weights. When fine-tuned for a new domain, the model risks overwriting parameters that govern its previous capabilities. For example, researchers from Legion Intelligence and Caltech trained a BERT model on Yelp reviews in March 2024, achieving 68.2% accuracy. However, when fine-tuned for IMDB sentiment classification, the model’s performance on Yelp reviews plummeted to just 21.4%. Even using LoRA, a parameter-efficient tuning method, only partially restored performance to 32.1%.
Standard optimization techniques focus exclusively on new data, often erasing as much as 23% of lower-layer attention structures. This leads to a significant loss of the model’s prior knowledge.
Parameter Inefficiency and Scalability Issues
Traditional fine-tuning methods require massive computational resources, involving updates to millions or even billions of parameters. This process can take hours or days and often reduces the diversity of the model’s output by 3–8%. For teams with limited budgets or tight deadlines, this makes domain adaptation a daunting task.
The challenge grows exponentially when models need to operate across multiple domains, such as legal, medical, and financial tasks. Fully fine-tuning the model for each domain becomes financially and logistically unfeasible. As a result, parameter-efficient techniques like LoRA have gained traction, reducing trainable parameters to less than 1% of the original model size. However, even these methods struggle with sequential learning, as they don’t completely solve the forgetting issue. These limitations underscore the need for more effective strategies, which will be explored in the next section.
Solutions for Cross-Domain Adaptation
Adapter and LoRA-Based Merging
Low-Rank Adaptation (LoRA) is a smart way to adapt large language models (LLMs) without the heavy computational demands of full fine-tuning. Instead of modifying all model parameters, LoRA freezes the pre-trained weights and introduces trainable matrices into transformer layers, particularly in attention projections. The efficiency here is impressive - LoRA slashes trainable parameters by 99% and reduces memory needs by over 90%. For example, while full fine-tuning a 7-billion-parameter model might require 60GB of VRAM, QLoRA (Quantized LoRA) with 4-bit quantization can achieve the same with only 6GB.
LoRA simplifies deployment by merging weights into the base model after training, meaning there’s no additional computational cost during deployment. As Ashish Chadha from Neural-Hacker explains:
“LoRA acts as a regularizer, preserving the base model’s capabilities on tasks outside the target domain better than techniques like weight decay and attention dropout.”
For general tasks, set LoRA’s rank (r) to 16, increasing to 32–64 for more complex domains. Use an alpha value twice the rank and a dropout rate between 0.05–0.1 to prevent overfitting. For the best results, apply LoRA to all linear layers, including feed-forward network projections, not just the attention layers.
Self-Training with Pseudo-Labeling
Self-training, particularly through pseudo-labeling, is another effective strategy for cross-domain adaptation. This method uses a model trained on labeled source domain data to assign “pseudo” labels to unlabeled target domain data, which the model then uses to retrain itself. It’s a semi-supervised approach that shines when there’s plenty of unlabeled data and manual labeling is expensive. For instance, pseudo-labeling improved MNIST model accuracy from 90% to 95%.
The trick is maintaining strict confidence thresholds - typically 95% or higher - to avoid the “Echo Chamber Effect”, where the model reinforces its own mistakes. More advanced techniques now include filters for “Conformity” (how well samples align with the target distribution) and “Consistency” (whether labels stay stable across training epochs). As Niklas von Moers points out:
“The model’s out-of-sample accuracy is bounded by the share of correct training labels. If 10% of labels are wrong, the model’s accuracy won’t exceed 90% significantly.”
To get the most out of pseudo-labeling, always keep a “clean” validation set with human-labeled data that is never contaminated by pseudo-labels. Gradually add pseudo-labeled data to the training pool instead of dumping it all at once. Focus manual labeling on low-confidence or edge-case data where the model struggles - this “human-in-the-loop” approach maximizes the impact of limited labeling resources.
Mixed-Domain Reinforcement Learning
Reinforcement learning adds another layer of refinement by introducing automated, domain-specific feedback mechanisms. Reinforcement Learning from AI Feedback (RLAIF) allows models to improve using signals generated by other LLMs, creating an “AI refining AI” loop. This method is particularly useful for cross-domain adaptation, as it scales domain-specific feedback without constant human involvement. LLM judges, like GPT-4, align with human evaluations over 80% of the time, making these feedback loops both scalable and reliable.
A practical example: In 2025, Nextdoor fine-tuned its reward function based on user feedback for AI-generated subject lines. This led to a 1% boost in click-through rates and a 0.4% rise in weekly active users. Similarly, Salus AI worked with domain experts in 2024 to optimize LLMs for marketing compliance tasks, improving performance from 80% to 95–100%.
This technique combines tools like prompt engineering, retrieval-augmented generation (RAG), and fine-tuning to meet specific domain needs, proving its versatility for cross-domain challenges.
Using Latitude for Observability and Feedback
Real-time monitoring is essential for ensuring that adaptation techniques hold up when models encounter new data. Latitude is an observability platform that provides detailed tracing, breaking down LLM workflows into “traces” (overall operations) and “spans” (specific steps like tool calls or model completions). This helps teams quickly identify where domain transfers might fail.
Latitude’s AI Gateway acts as a bridge between applications and AI providers, automatically capturing inputs, outputs, metadata, and performance metrics for every interaction. It also supports collaboration by offering shared workspaces where engineers and domain experts can experiment with prompts, review performance metrics, and provide structured feedback. As Alfredo Artiles, CTO of Audiense, puts it:
“Latitude is amazing! It’s like a CMS for prompts and agents with versioning, publishing, rollback… the observability and evals are spot-on, plus you get logs, custom checks, even human-in-the-loop.”
Latitude also enables live evaluations of production logs, tracking metrics like safety, helpfulness, and hallucination rates in real-time. Using smaller, specialized language models (SLMs) for quality checks can cut evaluation costs by up to 97% compared to premium APIs like GPT-4. Version control ensures that every prompt variation and its performance data are tracked, making it easy to roll back changes if domain-specific updates cause regressions. Pablo Tonutti, Founder of JobWinner, shares:
“Tuning prompts used to be slow and full of trial-and-error… until we found Latitude. We test, compare, and improve variations in minutes with clear metrics and recommendations.”
Comparison of Domain Adaptation Strategies
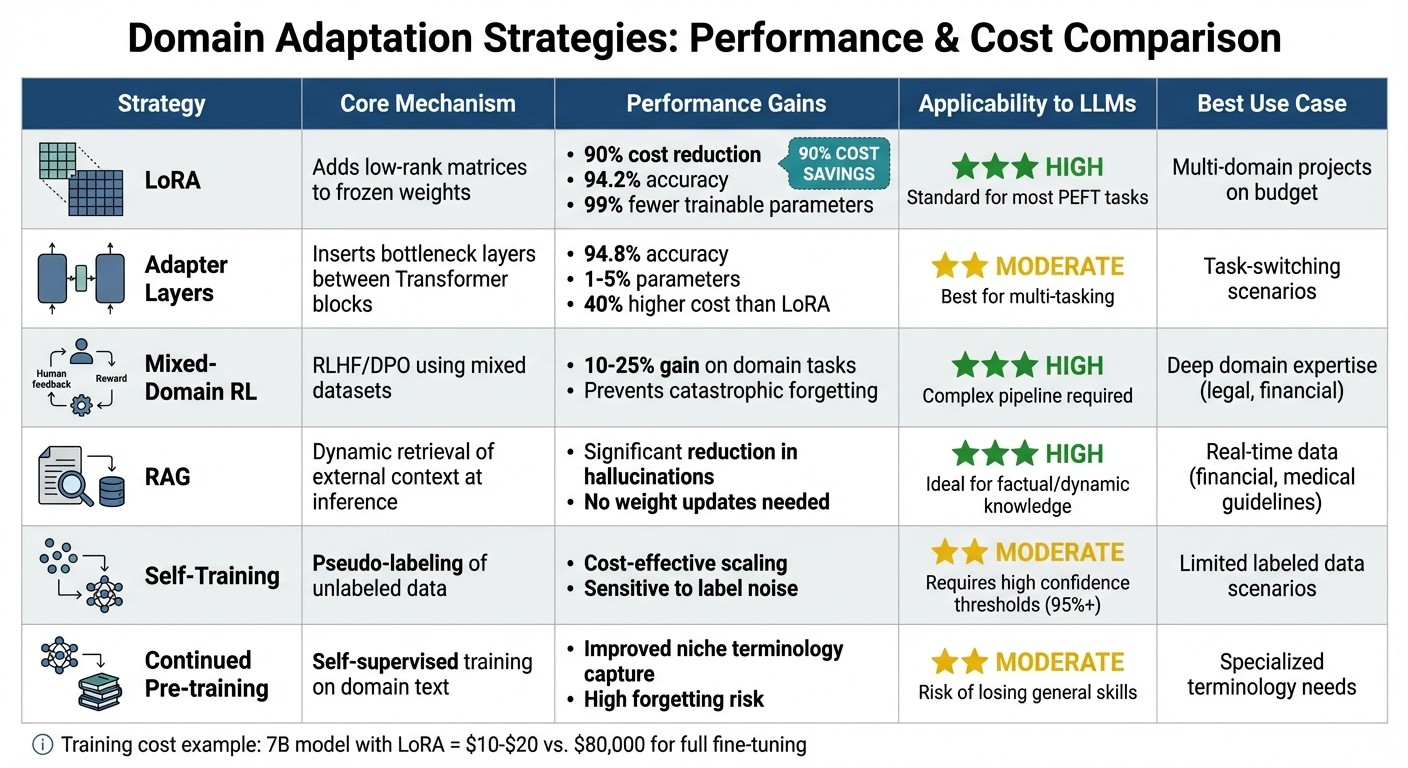
Comparison of 6 Domain Adaptation Strategies for Large Language Models
Comparison Table of Domain Adaptation Methods
When choosing a domain adaptation strategy, it’s essential to weigh the strengths and limitations of each approach. This section lays out a comparison to help guide the decision-making process, focusing on performance, cost, and specific use cases.
LoRA stands out by achieving 94.2% accuracy while slashing costs by 90% compared to full fine-tuning. It’s an excellent option for teams juggling multiple domains on a budget. On the other hand, Adapter Layers offer slightly better accuracy at 94.8% and are well-suited for task-switching scenarios, though they come with about 40% higher costs than LoRA.
For applications that demand deep domain expertise - like financial modeling or legal reasoning - Mixed-Domain Reinforcement Learning (e.g., using frameworks like FINDAP) can boost performance by 10–25% over base models. However, this approach is compute-heavy and requires a more complex pipeline. Meanwhile, RAG skips weight updates entirely, making it ideal for scenarios involving dynamic or rapidly changing knowledge, such as real-time financial data or medical guidelines.
If labeled data is scarce, Self-Training with Pseudo-Labeling provides a cost-efficient solution for scaling, though it can be sensitive to noise in the pseudo-labels. Lastly, Continued Pre-training excels at capturing specialized terminology but carries the risk of catastrophic forgetting, where the model loses its general knowledge.
The table below summarizes these trade-offs, offering a quick guide to choosing the right strategy:
| Strategy | Core Mechanism | Performance Gains | Applicability to LLMs | Key Citation |
|---|---|---|---|---|
| LoRA | Adds low-rank matrices to frozen weights | 90% cost reduction; 94.2% accuracy | High; standard for most PEFT tasks | arXiv:2407.11046 |
| Adapters | Inserts bottleneck layers between Transformer blocks | 94.8% accuracy; 1–5% parameters | Moderate; best for multi-tasking | Stratagem Systems |
| Mixed-Domain RL | RLHF/DPO using mixed in-domain and general datasets | 10–25% gain on domain tasks | High; helps prevent catastrophic forgetting | arXiv:2501.04961 |
| RAG | Dynamic retrieval of external context at inference | Significant reduction in hallucinations | High; ideal for factual/dynamic knowledge | Meta AI |
| Self-Training | Pseudo-labeling of unlabeled data for augmentation | Cost-effective scaling of small labeled sets | Moderate; sensitive to noise in labels | Szep et al. |
| Continued Pre-training | Self-supervised training on domain-specific text | Improved capture of niche terminology | Moderate; high risk of forgetting general skills | Gururangan et al. |
To put the costs in perspective, training a 7B model with LoRA using QLoRA on a mid-range GPU costs only $10–$20. This makes it an attractive option for budget-conscious projects.
Dr. James Patterson from MedTech Innovations shared a compelling real-world example:
“We were about to spend $80,000 on full fine-tuning… Stratagem recommended LoRA instead - same quality.”
Conclusion
Key Takeaways for Teams
When tackling challenges like domain shift and catastrophic forgetting, it’s clear that cross-domain transfers don’t have to drain resources or compromise results. Prioritizing high-quality data and leveraging techniques like LoRA can significantly cut costs while maintaining strong performance. The most effective teams bring together AI engineers and domain specialists - whether they’re legal professionals or healthcare experts - to ensure rigorous validation and smooth implementation.
It’s essential to look beyond simple accuracy metrics. Instead, rely on integrated real-world benchmarks, regular checkpoints, and shadow deployments to validate models safely and iteratively. Clearly defining roles is another critical step: let domain experts focus on setting requirements while engineers handle implementation and ongoing monitoring.
These strategies pave the way for the rapid advancements shaping the future of cross-domain adaptation.
The Future of Cross-Domain Adaptation
The landscape of cross-domain transfer is advancing quickly. Models are starting to transfer knowledge across different formats - text, images, and audio - while benchmarks are beginning to reflect real-world complexities, like resolving GitHub issues or navigating mobile interfaces. Techniques like in-context learning and Chain-of-Thought prompting are also reducing the need for frequent, full-scale updates.
Platforms such as Latitude are stepping in to support this evolution. By separating model configurations from application code, they allow for agile updates, quick detection of model drift, and efficient feedback loops. As cross-domain transfer grows more sophisticated, having robust infrastructure to monitor, evaluate, and refine models will be the key difference between a theoretical success and a solution that thrives in real-world production.
FAQs
How do I choose between LoRA, RAG, and RL for my domain?
Choosing between LoRA , RAG , and RL comes down to your specific goals, available resources, and the nature of the task at hand:
-
LoRA : Perfect for situations where you need efficient fine-tuning with minimal adjustments, especially when adapting models to specific domains or unique behaviors.
-
RAG : A go-to choice for tasks that require pulling in real-time or external knowledge, making it great for dynamic information retrieval.
-
RL : Best suited for interactive scenarios or systems that rely on feedback-driven learning, like decision-making applications.
The right choice depends on your specific use case, the type of data you’re working with, and any limitations you might face.
How can I reduce catastrophic forgetting during adaptation?
To tackle the challenge of catastrophic forgetting in large language models (LLMs), it’s crucial to use strategies that protect existing knowledge while integrating new information. Some effective approaches include:
-
Regularization : Techniques like Elastic Weight Consolidation help by restricting how much model parameters can change during training, ensuring prior knowledge isn’t overwritten.
-
Rehearsal : Mixing old and new data during training allows the model to retain previously learned information alongside new task-specific knowledge.
-
Model Merging : This involves combining models fine-tuned on different datasets, enabling the preservation of general knowledge while adapting to new tasks.
These methods work together to strike a balance between learning new skills and retaining what the model already knows.
What metrics should I monitor after deploying a domain-adapted LLM?
After setting up a domain-specific LLM, it’s important to keep an eye on a few critical metrics to ensure it performs well and remains reliable. These metrics include:
-
Response latency : This measures how quickly the model responds, including average response times and latency percentiles.
-
Accuracy : Metrics like precision, recall, and the F1 score help gauge how well the model is handling tasks.
-
System health : Factors such as uptime, error rates, and resource usage indicate the overall stability of the system.
By monitoring these in real time, you can quickly spot problems, maintain consistent availability, and ensure the model continues to produce high-quality, domain-specific results.