A systematic, layered approach to LLM evaluation prevents regressions by combining deterministic checks, LLM judges, and human review.

César Miguelañez

When deploying large language models (LLMs), creating a strong evaluation pipeline is critical for maintaining quality and catching issues before they affect users. Here's what you need to know:
Why It Matters: LLMs often produce outputs that seem correct but are flawed. Without proper evaluation, quality can degrade over time, especially after updates or changes in user behavior.
Key Metrics: Measure performance across areas like accuracy, safety, user experience, and efficiency. Use binary pass/fail labels for clarity.
Evaluation Process: Build layered systems:
Start with quick deterministic checks (e.g., JSON validation).
Add heuristic scoring for deeper analysis.
Use LLMs as judges for subjective qualities like tone.
Reserve human reviews for high-stakes cases.
Automation: Embed evaluations into CI/CD workflows to catch regressions early. Separate offline tests from live traffic monitoring.
Tools: Platforms like Latitude, LangSmith, and Braintrust help automate and monitor evaluations. Choose based on your needs, such as CI/CD integration or self-hosting.
Defining Evaluation Goals and Success Metrics
Before diving into coding your evaluation pipeline, it’s crucial to define what "good" means in clear, measurable terms. Vague goals like "be accurate" or "sound helpful" just won’t cut it. Instead, you need to establish specific criteria that outline exactly what constitutes correct, safe, and useful outputs. This level of clarity not only improves the evaluation process but also lays the groundwork for selecting the right metrics.
Key Metrics to Measure LLM Performance
While different systems may require tailored metrics, there are several categories that most LLM applications should track:
Metric Category | Key Metrics | Why It Matters |
|---|---|---|
Accuracy | Factuality, Groundedness, Code Correctness | Builds user trust and reduces risk |
User Experience | Tone, Helpfulness, Latency | Enhances user satisfaction and retention |
Safety | Toxicity, Bias, PII Detection | Protects brand reputation and ensures compliance |
Efficiency | Cost per 1,000 tokens, Throughput | Keeps operations cost-effective at scale |
RAG Quality | Context Precision, Context Recall | Evaluates how well retrieval supports accurate answers |
For clearer and more consistent results, use binary pass/fail labels instead of rating scales like 1–5. Binary labels eliminate ambiguity about what qualifies as "good" and encourage rigorous testing. A pass rate of around 70% indicates meaningful challenges in the tests, while a 100% pass rate may suggest the tests aren’t stringent enough.
"Binary pass/fail judgments outperform rating scales (1–5) for almost every evaluation use case." - Tian Pan, Engineer-Founder
Tying Metrics to Business Outcomes
Once you have clear evaluation goals, the next step is linking these metrics to real-world business outcomes. Metrics like latency and groundedness are more than just technical benchmarks - they directly impact user experience and business success. For example, a response that takes 8 seconds to load might technically be accurate, but it risks frustrating users and driving them away. Similarly, ensuring groundedness in a RAG system reduces the legal and reputational risks associated with false claims.
Evaluation rubrics should evolve alongside your business needs. Regularly revisit and update them to ensure they reflect what your users and business truly require.
Building an Evaluation Pipeline
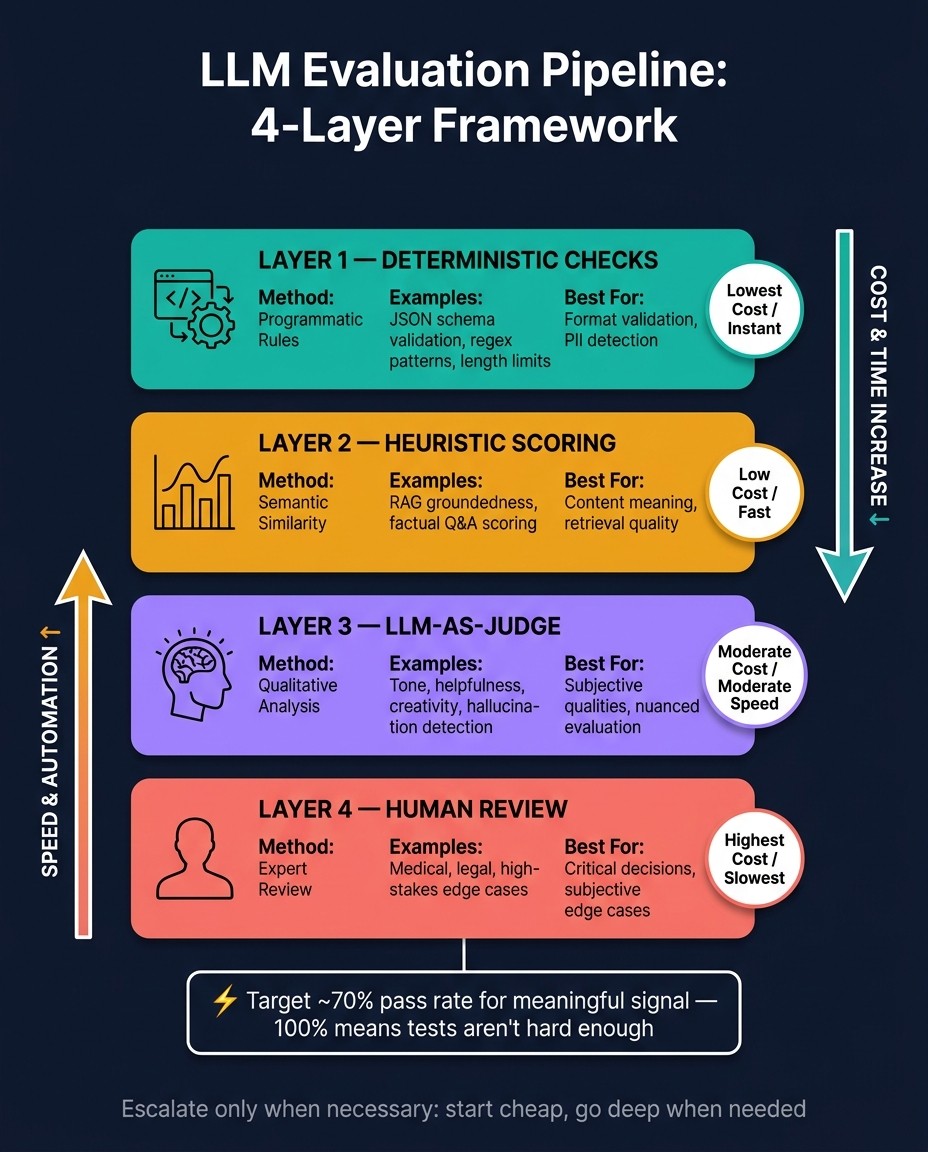
LLM Evaluation Pipeline: 4-Layer Framework for Production Quality
Once you've established clear metrics and business goals, the next step is building the evaluation pipeline. This involves deciding on the data you'll evaluate and selecting methods to score outputs effectively.
Dataset Design and Coverage
With evaluation metrics in hand, it's time to design datasets that thoroughly test your objectives.
A common misstep is creating one massive dataset that spans your entire product. Instead, break datasets into specific tasks or prompt engineering concepts. If you have multiple prompts, you’ll need separate datasets for each one. This approach keeps evaluations focused and makes it easier to identify where problems occur.
For dataset size, aim for a minimum of 30 examples to ensure meaningful regression testing. Start with 50 examples and work toward 200 per single-task prompt. Prioritize quality over sheer volume.
When sourcing examples, production logs are a great starting point. But don’t just pull the most frequent inputs. Include a mix of atypical or ambiguous queries that users sometimes throw at your system. Be sure to include edge cases, adversarial inputs, and off-topic queries to expose where your model might falter.
Dataset Coverage Category | Description |
|---|---|
Happy-path | Typical functionality and common user inputs |
Edge Cases | Unusual, ambiguous, or complex scenarios |
Adversarial | Malicious inputs to test safety and resilience |
Off-topic | Queries outside the intended scope that should be declined |
Keep your golden dataset entirely separate from any training or fine-tuning data. Mixing the two will only measure memorization, not the model's true capability.
Evaluation Layers and Techniques
With your dataset ready, the next step is implementing a layered evaluation process to catch issues quickly and efficiently.
No single method works for every scenario. A practical approach is to layer evaluation methods from the cheapest to the most resource-intensive, starting with fast checks and escalating only when necessary.
Here are the four primary layers:
Deterministic checks: These include regex patterns, JSON schema validation, and length limits. They're quick and inexpensive, ideal for catching obvious formatting errors.
Heuristic scoring: Slightly more resource-intensive, this method uses semantic similarity scoring to evaluate areas like RAG groundedness and factual Q&A.
LLM-as-judge: This involves using a cutting-edge model to assess subjective qualities like tone, helpfulness, and hallucinations. It's moderately costly and slower than the previous layers.
Human review: Reserved for high-stakes fields like medicine or law, this layer relies on expert judgment to handle nuanced or critical cases.
Evaluation Layer | Method Type | Best Use Case | Cost/Speed |
|---|---|---|---|
Deterministic | Programmatic Rules | JSON/format validation, regex, length limits | Lowest / Instant |
Heuristic | Semantic Similarity | RAG groundedness, factual Q&A | Low / Fast |
LLM-as-Judge | Qualitative Analysis | Tone, helpfulness, creativity, hallucinations | Moderate / Moderate |
Human-in-the-Loop | Expert Review | High-stakes (medical/legal), subjective edge cases | Highest / Slow |
For better results, build separate evaluators for each criterion - tone, factuality, and safety. To align these evaluators with expert standards, use critique shadowing. This involves having domain experts write detailed critiques for 50–100 examples. These critiques serve as few-shot examples for the model, which you refine until it agrees with the expert over 90% of the time.
Also, distinguish between guardrails and evaluators. Guardrails operate in real time, blocking harmful or malformed responses before users see them. Evaluators, on the other hand, work asynchronously in the background to support dashboards and long-term quality monitoring. Mixing these roles can lead to slower response times or gaps in monitoring.
Automation, Monitoring, and Regression Detection
Automating Evaluations in CI/CD Workflows
Once you've set up your evaluation layers, the next step is to ensure they run automatically rather than sporadically. This is where the concept of shift-left evaluation comes in - catching regressions in pull requests before they ever make it to staging or production. To keep costs in check, trigger evaluations only for changes that could impact output quality. This automated process is key to distinguishing offline development tests from live production monitoring.
It's also important to separate two types of evaluations:
Offline evaluations: These are run on curated datasets to catch known failure patterns early in development.
Online evaluations: These involve sampling live traffic to identify model drift and handle novel user queries.
For online evaluations, sampling just 10–20% of live traffic is usually enough to detect aggregate quality shifts without driving up costs. With automation in place, the next focus should be setting clear performance baselines.
Setting Thresholds and Baselines
Automation works best when it's tied to well-defined quality baselines. Start by running your evaluation suite 10–20 times against the current production system. Use the mean minus two standard deviations as your pass threshold. From there, establish hard minimums - like a quality score no lower than 3.5 out of 5 - and set alerts for significant drops, such as a 0.5-point decrease from the baseline.
Keep in mind that not all metrics should have the same level of urgency. For example:
Safety and faithfulness issues: These should block deployment immediately.
Tone or style regressions: These can be flagged for review but don’t necessarily need to halt deployment.
Here’s a quick breakdown of how to handle different metric categories:
Metric Category | Example Threshold | Action on Failure |
|---|---|---|
Safety | 0 violations | Block deployment immediately |
Faithfulness | ≥ 0.90 | Block deployment or require urgent SME review |
Answer Relevancy | ≥ 0.70 | Advisory; flag for product team review |
Style / Tone | ≥ 0.80 | Advisory; monitor for long-term drift |
If your test suite passes 100% of the time, it’s a sign that the tests aren’t challenging enough.
"If you're acing all your evals, they're not hard enough. Target around 70% pass rate to have meaningful signal." - Tian Pan, Engineer-Founder
As your system improves, raise your thresholds over time to match the enhanced performance and avoid slipping back in quality.
Tools like Latitude are designed for continuous monitoring. They can automatically generate evaluations from real production failures and track regressions as they happen, ensuring you catch issues before users are affected.
Selecting Tools and Platforms for LLM Evaluation
Comparison of Evaluation Platforms
Once your baselines and automation are in place, the next step is selecting tools that integrate smoothly with your workflow. The market for LLM evaluation platforms has grown rapidly, offering features like automated scoring, CI/CD integration, and seamless pipelines from production to evaluation. Picking the wrong platform can create unnecessary bottlenecks, so it's crucial to make a thoughtful choice.
The right evaluation platform ensures reliability and helps avoid regressions. However, no single tool is perfect across all dimensions. Each platform makes trade-offs in areas like usability, framework compatibility, self-hosting options, and evaluation methodologies.
"Choosing between platforms isn't straightforward. Each tool makes trade-offs between ease of use, framework compatibility, self-hosting options, and evaluation methodology." - Agent Harness
Here’s a breakdown of how some of the leading platforms compare on the features that matter most for production evaluation:
Platform | Primary Strength | Self-Hosting | CI/CD Blocking | Free Tier | Paid Starts At |
|---|---|---|---|---|---|
Latitude | Production failure detection & auto evals | Yes (Enterprise) | Yes | 5K traces/mo | $299/mo (Team) |
LangSmith | Enterprise only | Manual | 5K traces/mo | $39/seat/mo | |
Open-source, data residency | Yes (MIT licensed) | Manual | 1M spans/mo | $29/mo | |
Braintrust | Experiment diffing & deployment gates | Enterprise only | Native | 1M spans/mo | $249/mo |
Proxy-based setup, cost optimization | Yes (Apache 2.0) | No | 10K req/mo | $79/mo |
The table highlights key features, but let’s dive deeper into what makes each platform stand out.
If your stack relies heavily on LangChain or LangGraph, LangSmith is the easiest option to integrate, offering zero-configuration tracing. For industries like healthcare or finance, where data residency is non-negotiable, Langfuse is a solid choice due to its open-source MIT license and robust self-hosting capabilities. For teams focused on enforcing quality gates during deployment, Braintrust is ideal. Notion’s AI team, for example, saw their issue-fixing rate jump from 3 to 30 per day after adopting Braintrust’s CI/CD evaluation workflow.
Latitude takes a more production-focused approach. It identifies failure modes directly from live traffic and auto-generates evaluations based on real-world issues, bridging the gap between development tests and actual production failures. Its Team plan ($299/month) is well-suited for teams running LLMs in production, offering unlimited annotation queues and continuous regression detection.
"The best eval tool is one your stack can actually reach." - Inference Research
Of course, no single platform can meet every requirement. Many teams find success by combining tools - using production monitoring platforms like Langfuse alongside CI/CD testing frameworks such as DeepEval. This hybrid approach provides comprehensive coverage without committing entirely to a single vendor.
Common Failure Modes and How to Guard Against Them
This section dives into typical failure modes in large language models (LLMs) and the strategies needed to catch and address them before users encounter issues.
Types of Failures to Monitor
Failures in LLMs are inevitable, especially in production. The real challenge is identifying and addressing these failures before they affect users. Monitoring for common failure modes is not just helpful - it’s essential. Here are the key failure types to watch for, along with their impacts and recommended interventions:
Failure Mode | Impact | Recommended Intervention |
|---|---|---|
Hallucination | Loss of user trust; legal/compliance risks | Faithfulness checks (using an LLM as an evaluator); grounding in Retrieval-Augmented Generation (RAG) |
Format Drift | Broken UI/API integrations; system crashes | JSON schema or regex validation |
Prompt Injection | Brand damage; unauthorized data access | Synchronous input/output filtering; adversarial testing |
PII Leakage | PII detection scanners; synchronous blocking | |
Retrieval Failure | Irrelevant or incomplete answers; user frustration | Contextual relevancy/recall metrics; chunking optimization |
Unsafe Output | Policy violations; toxic user experiences | Toxicity classifiers; human-in-the-loop review |
For example, hallucinations can be tackled by implementing faithfulness checks, while retrieval failures require robust contextual metrics like Recall@K or Mean Reciprocal Rank (MRR) to identify and address gaps early.
Agent-specific issues also need attention. These include:
Tool hallucinations: When the model calls a non-existent function.
Cascading errors: Early mistakes that snowball through subsequent steps.
Multi-agent oscillation: Infinite loops between agents.
Designing Effective Guardrails
A solid guardrail system is critical to preventing these failures from reaching end-users. It’s important to distinguish between synchronous guardrails and asynchronous evaluators, as engineer Tian Pan explains:
"Guardrails run synchronously and block responses; evaluators run asynchronously and inform dashboards."
Synchronous guardrails are real-time checks that operate in milliseconds. They block problematic responses, trigger retries, or route outputs to fallback mechanisms before users see them. On the other hand, asynchronous evaluators work after the fact, feeding insights into monitoring dashboards. Confusing these two can lead to slow response times (if heavy evaluations are run synchronously) or missed issues (if guardrails are treated as optional).
Here’s how to implement effective guardrails:
Deterministic checks: Use tools like regex patterns to catch sensitive information, such as Social Security numbers or credit card details. JSON schema validators (or tools like Zod) can ensure consistent output structures and prevent malformed responses from causing system disruptions.
Tiered human review: For high-risk scenarios, scale oversight based on task complexity. Automated reviews might suffice for simple tasks, but high-stakes outputs should involve expert review.
Platforms like Latitude can enhance this process by analyzing live production traffic to identify failure modes and auto-generate evaluations based on real-world issues. This ensures guardrails are built around actual problems, not just theoretical ones anticipated during development.
Maintaining and Improving Evaluation Pipelines Over Time
An evaluation pipeline isn’t something you set up once and forget about. Models, prompts, and user needs evolve constantly, which means your pipeline has to keep up. Quality regressions are a common challenge in large language model (LLM) deployments, so ongoing maintenance is key to ensuring your evaluations reflect real-world performance. Successful teams treat their evaluation systems as dynamic and adaptable, not static and unchanging.
Refreshing Datasets and Labels
The best way to keep your datasets relevant? Use your production traffic. By analyzing real user interactions, you can uncover valuable insights. Strip out any personally identifiable information (PII) and focus on the tricky, edge-case inputs that typical metrics might miss. A good rule of thumb is to add 10–20 new examples each month, drawn from production failures and new product features.
"The dataset evolves. You add rows when users report bugs. You remove rows when your product pivots. The dataset must evolve with product changes." - EmberLM
One practice that sets high-performing teams apart is the 48-hour rule: any production failure that makes it through triage should be turned into a golden dataset entry within 48 hours. This approach has helped teams close the gap between production issues and regression testing, improving system reliability.
It’s also critical to pair dataset versions with prompt versions (e.g., Dataset v4 with Prompt v8). Without this, any drop in scores becomes a mystery - did the model regress, or did the test become harder? Additionally, review any dataset entries older than a year to ensure they still align with current user needs.
Refining Scoring and Metrics
Once your datasets are updated, it’s time to refine how you evaluate outputs. If your evaluation suite consistently shows a 100% pass rate, that’s a red flag - it likely means your metrics aren’t challenging enough to catch real issues. Aiming for a 70% pass rate gives you enough room to detect meaningful regressions.
One major improvement you can make is switching from 1–5 Likert scales to binary pass/fail labels. Why? Human agreement on 5-point scales is notoriously low (Cohen’s Kappa of 0.2–0.3), while binary labels achieve much higher agreement (0.6–0.8). It’s simple: one person’s "3" might be another’s "4", but most people can agree on whether something passes or fails.
"The single most consistently validated finding in eval engineering: binary pass/fail labels outperform Likert scales (1–5) for almost every evaluation use case." - Tian Pan, Engineer-Founder
For LLM-based scoring, avoid creating a single all-encompassing "God Evaluator." Instead, develop separate evaluators for each criterion - one for tone, another for accuracy, and so on. This way, you can pinpoint exactly where regressions occur. To fine-tune these evaluators, have domain experts annotate 50–100 pass/fail examples with detailed reasoning. These examples can then serve as few-shot prompts for your evaluation model, a method known as critique shadowing, which helps align automated judges with human expectations.
Here’s a quick guide to how often different evaluation layers should be updated:
Evaluation Layer | Best For | Update Frequency |
|---|---|---|
Deterministic (Regex/JSON) | Format, length, PII | After each code update |
Heuristic (Semantic Similarity) | Content meaning | Per prompt version |
LLM-as-Judge | Tone, helpfulness, nuance | Monthly recalibration |
Human Review | High-stakes/subjective outputs | Quarterly or per release |
Tools like Latitude make this process easier by monitoring production traffic, generating evaluations from real-world failures, and keeping track of evaluation quality over time. This ensures your scoring metrics stay in sync with what’s breaking in the field.
Conclusion: Building Reliable LLM Systems with Evaluation Pipelines
Creating effective LLM evaluation pipelines requires consistent improvement. Teams that prioritize evaluation as a key part of their development process - not just an afterthought - are far more likely to succeed. In fact, up to 40% of organizations deploying LLM-powered applications experience major quality regressions within the first 90 days of production. This makes a well-structured evaluation pipeline essential.
Take Notion, for example. Their transition from manual testing to a more systematic evaluation process greatly improved their ability to resolve issues. This highlights how continuous and disciplined evaluation can lead to better outcomes.
Top-performing teams share some key habits: versioning prompts and rubrics, using clear pass/fail labels, creating separate evaluators for specific criteria, and turning production failures into test cases within 48 hours. Combining automated evaluation with regular human review has also proven effective - teams following this approach report about 40% better system quality compared to those relying solely on automation.
Integrating tools like Latitude, Braintrust, Langfuse, and LangSmith into your CI/CD workflow can help you implement these practices seamlessly. By 2026, these platforms have become robust and user-friendly, making it easier than ever to embed evaluation into your development process.
FAQs
How do I choose the right pass/fail thresholds?
Determining pass/fail thresholds for evaluating large language models (LLMs) begins with a detailed error analysis. Start by examining real user interactions to pinpoint common and critical failure types, such as hallucinations or factual inaccuracies. These insights help you understand where the model struggles most.
From there, set thresholds that reflect the failure rates you’ve identified. This isn’t a one-and-done process - refinement is key. Adjust thresholds over time as you gather more data and observe how the model performs in various scenarios.
To make the thresholds more precise, use a combination of evaluation methods:
Deterministic rules: These are clear-cut rules that flag specific errors.
Semantic scoring: Measures how closely the model’s output aligns with the intended meaning.
Human review: Adds a layer of subjective judgment to catch nuanced issues.
Finally, keep your thresholds up-to-date. Regularly analyze new data to ensure your benchmarks remain effective and to catch any potential regressions before they become a problem.
What’s the minimum dataset size to start evals?
When it comes to gathering data, starting with at least 100 real user interactions or production traces is a good rule of thumb. This amount provides enough information to spot potential failure patterns and create evaluation datasets that are useful for analyzing errors and making improvements.
When should I use humans vs an LLM judge?
Humans bring a level of expertise and judgment that is crucial for nuanced, domain-specific evaluations, particularly in high-stakes fields like law or medicine. Their ability to identify potential pitfalls and refine evaluation criteria based on deep knowledge makes them indispensable in these areas.
On the other hand, large language models (LLMs) shine when it comes to scalable and consistent assessments. They are especially effective for tasks like routine evaluations, multi-turn assessments, monitoring, regression testing, and automating production workflows - provided they are properly calibrated and aligned with human feedback.
By combining the strengths of both humans and LLMs, you can create a balanced and reliable evaluation pipeline that leverages the best of both worlds.



