
A domain-specific evaluation framework is a system designed to test AI performance using industry-specific data, rules, and goals. Unlike generic benchmarks, it focuses on tasks that matter to your business, ensuring reliability and reducing errors. Here’s how to build one:
-
Set Clear Goals : Define measurable metrics, like accuracy or response time, tailored to your domain.
-
Create a Rubric : Break down quality into specific criteria, such as tone, accuracy, or compliance.
-
Choose Datasets : Use real-world data, curated examples, and synthetic samples to test your AI.
-
Combine Tools and Experts : Automate basic checks, use AI for nuanced evaluations, and involve human reviewers for critical tasks.
-
Integrate into Development : Run evaluations with every update to catch issues early and track performance over time.
This approach ensures your AI meets the standards your users expect while aligning with your business needs.
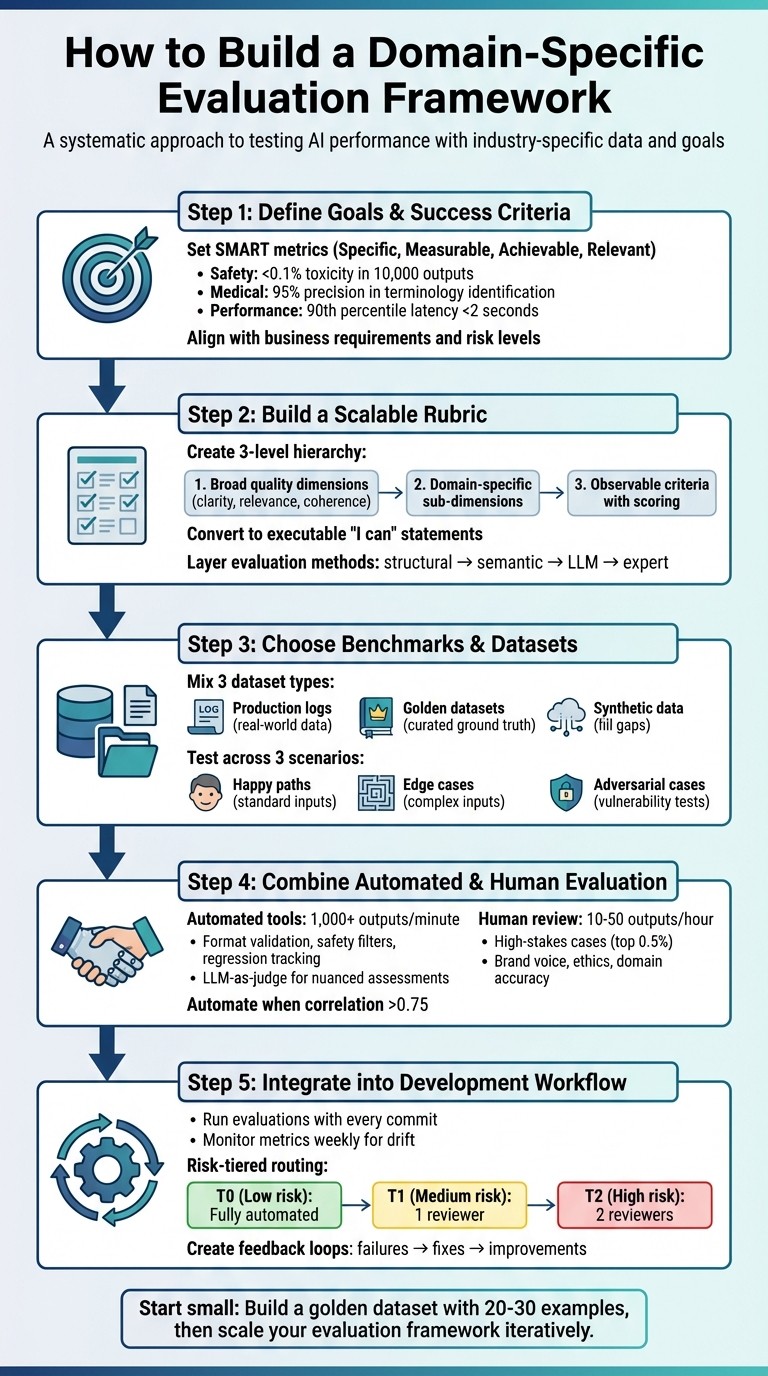
5-Step Framework for Building Domain-Specific AI Evaluation Systems
Step 1: Define Your Evaluation Goals and Success Criteria
Set Measurable Success Metrics
Start by defining clear, quantifiable metrics that align with your specific domain. Vague goals like “good performance” or “safe outputs” won’t cut it. Success criteria need to be Specific, Measurable, Achievable, and Relevant (SMART).
Let’s break this down with examples. For safety, you might set a threshold like “less than 0.1% of 10,000 outputs flagged for toxicity.” In medical applications, instead of saying “high accuracy,” specify something like “95% precision in identifying medical terminology in patient notes.” Similarly, for performance, avoid generic terms like “fast response” and aim for something concrete, such as “90th percentile latency under 2 seconds for 50 concurrent users”.
Metrics will vary depending on your application:
-
Customer service : Focus on empathy, tone, accuracy, and helpfulness, often assessed through human evaluators or AI judgment and prompt engineering.
-
Code generation tools : Evaluate syntax correctness, efficiency, and formatting using tools like compilers and linters.
-
Retrieval-Augmented Generation(RAG) systems : Measure faithfulness to source material and monitor hallucination rates.
-
Healthcare and legal tools : Prioritize factual accuracy and regulatory compliance, verified by human experts.
-
Structured outputs : Ensure adherence to JSON schemas or regex patterns using programmatic validation.
If you’re just starting, focus on volume over perfection. Running a large number of automated tests will provide a broader understanding of your system’s performance than a small, manually graded sample. You can fine-tune and refine as you go.
Align Goals with Business and Domain Requirements
Once your metrics are in place, align them with your business and domain objectives. Evaluation frameworks should address real-world needs rather than just impressive numbers. Begin by identifying what your users depend on most, and work backward to define criteria that safeguard those outcomes.
The level of risk in your application dictates the depth of evaluation:
-
Low-risk tasks (e.g., summarization, basic Q&A): Automated checks are usually sufficient.
-
Medium-risk scenarios (e.g., general customer support): Require at least one reviewer to verify outputs.
-
High-risk use cases (e.g., legal advice, financial recommendations, medical guidance): Mandate two reviewers to catch errors before they reach end users.
The goal is to translate business needs into actionable tests. For example, if your company relies on citation accuracy, set a target like “95% of citations must match the provided source documents exactly”. If regulatory compliance is critical, identify the specific rules your outputs must follow and design tests to enforce them. Ultimately, your evaluation criteria should reflect the stakes and consequences of failure in your domain.
Step 2: Build a Scalable Evaluation Rubric
Create a Hierarchical Rubric Structure
Once you’ve defined measurable success metrics in Step 1, the next step is creating a scalable rubric that connects broad quality concepts to specific, actionable criteria. This structured approach helps your evaluation framework remain flexible and adaptable as your needs evolve.
A good rubric has three levels:
-
Broad quality dimensions : These include general principles like clarity (how understandable is the output?), relevance (does it meet the user’s intent?), and coherence (is the output logically consistent?). These dimensions form the foundation of your rubric.
-
Sub-dimensions : Tailor these to fit the unique requirements of your domain. For example, in a legal context, sub-dimensions might include “accuracy in legal terminology” or “adherence to jurisdictional guidelines.”
-
Detailed, observable criteria : These are specific behaviors or outcomes that demonstrate success. For instance, a high score might indicate “fully completed task with no factual errors and an appropriate tone”, while a mid-tier score could reflect “partially completed task with minor inaccuracies or tone mismatches.”
If your evaluation involves complex or domain-specific tasks, analytic rubrics are a better choice. They break down performance into multiple criteria, offering detailed feedback for improvement. On the other hand, holistic rubrics provide a single overall score and are suitable for simpler, low-stakes tasks where speed is more important than detailed analysis.
Once your rubric structure is in place, the next step is to translate these qualitative elements into measurable, testable specifications.
Turn Rubric Criteria into Executable Specifications
To make your rubric actionable, convert its criteria into measurable tests. Use clear “I can” statements to define success. For example, rather than stating “fails to identify PII”, reframe it as “the model can accurately identify personally identifiable information in 95% of test cases”. This approach emphasizes what success looks like instead of focusing on failure.
Build your evaluation in layers, using different methods for different types of criteria:
-
Structural checks : Use programmatic rules to validate outputs. For instance, ensure proper formatting or adherence to specific guidelines.
-
Semantic scoring : Apply heuristic methods to compare outputs against a reference set.
-
Nuanced assessments : Use LLM-as-Judge for subjective qualities like tone, helpfulness, or safety.
-
Expert review : For high-stakes areas like legal or medical contexts, rely on human expertise to ensure accuracy and appropriateness.
Before deploying your rubric widely, test it on sample outputs. Look for inconsistencies where reviewers might interpret the same output differently. Use inter-rater reliability reports to identify and resolve ambiguities. Regularly involve subject matter experts and end-users to refine the rubric. These stakeholders can catch subtleties that automated tools might miss and ensure the rubric aligns with evolving business needs.
Step 3: Choose Domain-Specific Benchmarks and Datasets
Select Relevant Benchmarks and Datasets
Once you’ve defined your rubric criteria, the next step is to identify and validate datasets tailored to your domain. These benchmarks should directly address the unique challenges of your field. For example, in healthcare applications, you might focus on ensuring contraindication safety, while retrieval-augmented generation (RAG) systems demand a strong alignment with source material for accuracy.
When selecting datasets, aim for variety. Incorporate both “known truths” for established scenarios and “novel queries” to test how well the system generalizes. Include a mix of formats and complexities to cover a broad spectrum of use cases. Studies have shown that performance can vary significantly across domains - by as much as 68.94% in code-generation tasks alone. This highlights the risk of relying solely on generic benchmarks, which may fail to reveal domain-specific weaknesses.
To build a well-rounded dataset, consider blending three types:
-
Production Logs : These reflect real-world user interactions and edge cases, offering practical insights. However, they require existing traffic and come with potential privacy concerns.
-
Golden Datasets : These are high-quality, manually curated datasets with verified ground truth, ideal for regression testing. The downside is the time and effort needed for curation.
-
Synthetic Data : Useful for filling gaps where real-world examples are lacking. While synthetic data can help, it may not fully capture the nuances of actual user interactions.
For specialized fields, explore industry-specific benchmarks. For instance, Biglaw Bench (BLB) evaluates legal AI systems across various legal tasks. This kind of targeted evaluation offers a more precise assessment than general-purpose benchmarks. Additionally, organize your datasets by purpose. Use stable “known truths” to monitor regressions in existing features, and set aside “challenge” datasets to measure performance on more demanding queries.
After selecting your datasets, the next step is to validate their quality and reliability.
Verify Dataset Quality and Reliability
The effectiveness of your benchmarks depends on the quality of your datasets. Start by ensuring they provide valid and reliable measurements. For example, use grounding tests or needle-in-the-haystack probes to confirm that outputs remain faithful to the source material. Separability is another key metric - this measures how well your benchmark can differentiate between models, ensuring confidence intervals don’t overlap excessively.
To assess dataset quality, test across three scenarios:
-
Happy Paths : Standard, straightforward inputs that the system should handle easily.
-
Edge Cases : Complex or unusual inputs that push the system’s limits.
-
Adversarial Cases : Inputs designed to expose vulnerabilities or weaknesses.
This multi-faceted approach ensures your dataset evaluates more than just the system’s strengths. Over time, metrics can lose their effectiveness if overly targeted, so refreshing datasets periodically is essential to avoid over-optimization.
Step 4: Combine Automated and Human Evaluation Methods
Use LLM-Based and Automated Evaluation Tools
Once you’ve established your rubric and domain-specific tests, automated tools become essential for efficiently validating measurable outputs. These tools excel at handling tasks like format validation, JSON schema checks, safety filters, and regression tracking. With a well-structured system, it’s possible to evaluate over 1,000 outputs per minute by layering different approaches.
Start with straightforward, low-cost programmatic rules to handle basic checks. For more complex assessments - like evaluating tone, relevance, or coherence - turn to LLM-as-judge methods. When using LLMs for evaluation, set the temperature to zero for consistency, and always select a model from a different family than the one being tested (e.g., use GPT-4 to evaluate Claude-generated outputs).
In practice, automate evaluations for every output but reserve detailed analysis for 5–10% of cases. Focus this sampling on outputs with low-confidence predictions or those in high-risk categories. Negative metrics, such as toxicity or hallucinations, should be flagged explicitly so optimization algorithms aim to reduce these scores rather than increase them.
While automation ensures speed and consistency, some aspects - especially subjective or complex ones - demand human judgment.
Add Human Expert Review
To complement automated tools, human reviewers step in to address areas where machine evaluations may fall short. Experts are vital for assessing nuanced qualities like brand voice, emotional impact, ethical considerations, and domain-specific accuracy. In high-stakes fields such as law, medicine, or finance, human oversight is not just helpful - it’s required.
Using the earlier risk categorization, human review should prioritize high-stakes outputs. A risk-tiered routing approach works well here: fully automate low-risk tasks (e.g., basic Q&A), but involve human reviewers for the top 0.5% of critical cases. These experts should focus on creating “golden datasets” to establish ground truth and fine-tune automated evaluation systems. Transition to full automation only when human and automated scores show a consistent correlation above 0.75. For collecting human feedback, use even-numbered scales (like 1–4 or 1–6) to discourage neutral responses and ensure clear evaluations of negative traits, such as toxicity.
| Dimension | Automated Metrics | Human Feedback |
|---|---|---|
| Speed | Fast/Instant (1,000+ per minute) | Slower (10–50 per hour) |
| Cost | Very Low (minimal costs) | High ($20–$200/hour) |
| Consistency | 100% (Deterministic) | Variable (Subjective bias) |
| Best For | Format, Safety, Regression | Nuance, Ethics, High-stakes |
| Scalability | High (Thousands of outputs) | Limited by availability |
Step 5: Add the Framework to Your Development Workflow
Build Evaluation into Your Development Process
Make evaluations an integral part of your development workflow by automating them to run with every commit and at regular intervals. Think of evaluations as similar to unit tests - they should run automatically whenever code is updated to catch potential issues before they reach production.
Set up triggers that activate your evaluation suite whenever there are changes to prompt templates, model configurations, or retrieval logic. This ensures regressions are caught early, just like traditional software testing. Additionally, schedule evaluations on live traffic - hourly or daily - to monitor ongoing performance. Combining pre-production checks with live monitoring provides a more comprehensive quality control system.
Adopt a tiered evaluation strategy to balance cost and speed. Start with quick and inexpensive checks like regex patterns or JSON schema validation. For moderately complex cases, use semantic similarity tools, and reserve more resource-intensive LLM-as-judge evaluations for nuanced issues. This approach allows you to efficiently handle a large volume of outputs without sacrificing thoroughness.
Track and Fix Performance Drift
With evaluations embedded in your workflow, keep an eye out for performance drift. Monitor key metrics weekly using the same test sets to establish baselines and quickly detect any signs of degradation. Performance drift can be caused by changes in model behavior, shifts in user patterns, or updates to data distributions.
If any critical metric drops by more than 5%, investigate immediately. Compare the current outputs with your golden dataset to identify patterns in failures. Common issues include provider-side model updates altering behavior, new user patterns causing unexpected inputs, or problems in your data retrieval pipeline. Document these incidents thoroughly - include dates, affected metrics, root causes, and resolutions. This documentation will help guide future fixes.
For applications with higher stakes, implement a risk-based review system. Automate low-risk tasks (T0), assign medium-risk outputs to a single reviewer (T1), and require two independent reviewers for high-stakes cases like legal or medical advice (T2). This ensures critical issues are addressed promptly without overloading your team.
Create Feedback Loops for Continuous Improvement
Continuous monitoring should feed directly into your development process. When evaluations fail, send detailed reports to your team, including the failed criteria, expected results, and how often the issue occurs. Focus on fixing the most frequent and impactful failures rather than trying to solve every edge case.
Use these insights to refine prompts, tweak model parameters, or enhance your retrieval systems. If automated scores frequently differ from human reviewers, update your evaluation criteria or expand your test dataset to include new cases. This iterative process ensures your framework stays aligned with real-world requirements.
Platforms like Latitude can simplify this workflow by combining observability, human feedback, and evaluation tracking in one place. Teams can review flagged outputs, adjust prompts, and rerun evaluations to confirm improvements - all within hours instead of weeks. This streamlined process turns evaluation data into actionable updates, keeping your system agile and effective.
Conclusion
Key Takeaways
Creating a domain-specific evaluation framework for your AI product is a journey that evolves alongside your system. Start by identifying success metrics that align tightly with your business goals and the specific needs of your domain. Develop a structured rubric to turn subjective quality standards into measurable criteria, and choose benchmarks and datasets that mirror the scenarios your AI will face in practice.
A solid framework blends multiple layers of evaluation: quick, rule-based checks for efficiency; semantic similarity tools for deeper analysis; LLM-based assessments for nuanced judgments; and human expertise for critical, high-stakes decisions. This multi-tiered approach ensures a balance between cost, speed, and accuracy while addressing potential issues at every level.
Make evaluations a core part of your development process. Track key performance metrics regularly to detect any performance drift, and act quickly when significant drops occur. Use these insights to refine your models, adjust datasets, and improve the framework itself. This creates a feedback loop that turns evaluation outcomes into actionable improvements for your team.
Next Steps for Your Team
With these principles in mind, it’s time to take action. Start by building a golden dataset with 20–30 key examples and refine it over time. Set up your system to log complete traces and session IDs, then analyze production logs to uncover domain-specific failure patterns. Introduce your first evaluations into the CI/CD pipeline to catch potential regressions before they impact users.
Collaboration is key here. Product teams bring deep knowledge of domain requirements and can define what “good” looks like, while engineering teams provide the technical foundation to measure and maintain quality. Schedule weekly reviews of edge cases as a team, turning manual annotations into automated tests to broaden your evaluation coverage. This collaboration helps keep your framework aligned with both technical capabilities and practical needs, ensuring your AI performs reliably in the real world.
For seamless integration of these strategies, consider using the Latitude platform (https://latitude.so). It offers tools to embed thorough evaluation and continuous monitoring directly into your AI workflows.
FAQs
How do I pick the right metrics for my domain?
When evaluating performance, it’s crucial to pick metrics that align with your specific goals and priorities. While commonly used metrics like BLEU or ROUGE might work in some contexts, they may not fully capture what’s important for your domain. Instead, take the time to define clear success criteria that reflect your unique needs.
Developing structured rubrics can help you assess multiple dimensions, such as tone, accuracy, or other qualities relevant to your project. And don’t stop at numbers - pair quantitative metrics with qualitative feedback to create a well-rounded evaluation framework. This approach ensures your assessment is tailored to your use case and delivers insights that actually matter.
What’s the fastest way to build a rubric that reviewers agree on?
To get everyone on the same page fast, you’ll need a framework that suits your industry or specific use case. Here’s how to make it happen:
-
Define clear, measurable criteria : Focus on the key aspects of performance that matter most, like accuracy or safety. The criteria should leave no room for ambiguity.
-
Calibrate with experienced reviewers : Work with seasoned professionals to test the rubric. This helps ensure everyone interprets it the same way.
-
Refine with feedback : Gather input from reviewers and tweak the rubric until you reach a shared understanding.
The secret lies in clarity and calibration - these steps will help speed up the process of reaching agreement.
How much should I rely on automated scoring vs human experts?
The right balance hinges on the specific task at hand. Automated metrics shine when dealing with objective, large-scale evaluations, such as measuring accuracy or consistency, thanks to their speed and ability to scale. On the other hand, human feedback excels in more subjective or complex areas, like assessing tone or addressing ethical considerations. Combining both - automation for routine tasks and human input for nuanced situations - can help achieve both efficiency and high-quality results.