Automate routine monitoring at scale and use human review for nuance, edge cases, and high‑stakes decisions.

César Miguelañez

Choosing between human feedback and automated metrics depends on the task. Automated metrics are fast, scalable, and cost-effective for objective evaluations like numerical accuracy and regression tracking. Human feedback, while slower and more expensive, is essential for subjective tasks requiring nuance, such as tone, ethics, or complex decision-making.
Key Points:
Automated Metrics: Best for structured, objective tasks (e.g., spam detection, data extraction). They are consistent, scalable, and inexpensive but lack contextual understanding.
Human Feedback: Ideal for subjective, high-stakes decisions (e.g., legal, medical). It captures subtleties that machines miss but is costly and time-intensive.
Hybrid Approach: Combining both methods balances speed, cost, and quality. Use automation for large-scale monitoring and human reviews for edge cases and calibration.
Quick Comparison:
Dimension | Automated Metrics | Human Feedback |
|---|---|---|
Speed | Fast/Instant | Slower (days/weeks) |
Cost | Low (pennies per API call) | High ($20–$200/hour for experts) |
Scalability | High (thousands of outputs) | Limited by reviewer availability |
Consistency | High (repeatable/deterministic) | Variable (subjective bias) |
Best For | Objective tasks, monitoring | Subjective tasks, edge cases |
For optimal results, automate routine evaluations and reserve human reviews for critical or nuanced scenarios.
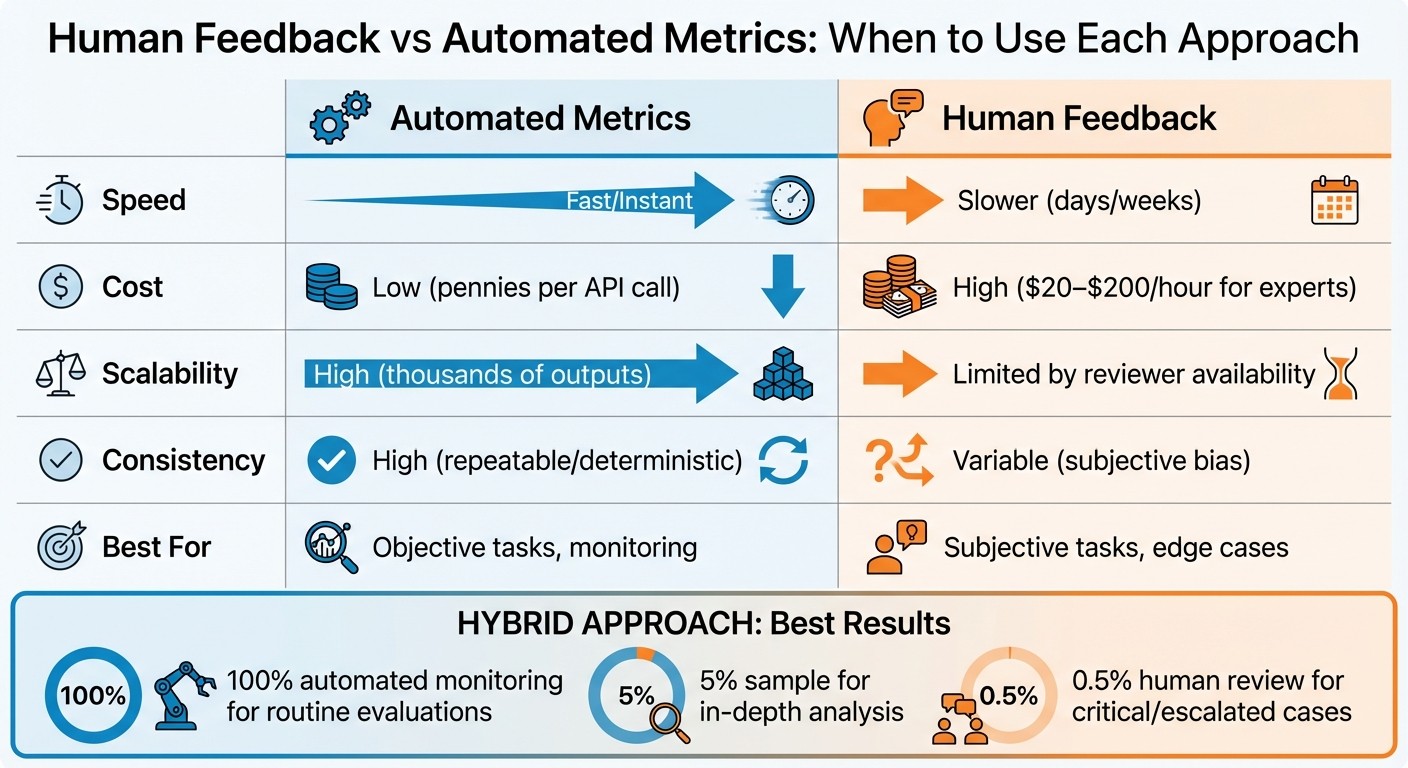
Human Feedback vs Automated Metrics: Speed, Cost, and Scalability Comparison
1. Human Feedback
Effectiveness for Objective vs Subjective Tasks
Human evaluators bring something unique to the table: the ability to assess brand voice, emotional depth, and originality - things that automated metrics like BLEU or ROUGE often overlook. For example, a haiku that technically fits a pattern might score well with automated systems but completely miss the emotional resonance it's supposed to convey. Similarly, AI-generated medical advice might be factually correct but fail to align with cultural subtleties that only human judgment can fully grasp.
In critical fields like law, medicine, or engineering, human expertise becomes non-negotiable. Automated systems struggle to interpret complex jargon, legal precedents, or intricate clinical guidelines. They also fall short when it comes to making nuanced ethical decisions about fairness or equity. While machines excel at numerical precision, they can unintentionally reinforce systemic biases - issues that often require human oversight to identify and address.
Scalability and Cost
Human reviews come at a price. Evaluating outputs manually costs between $1 and $2 per prediction. For a single evaluation round sampling 5–10% of outputs, expenses range from $20,000 to $50,000. When specialists like clinicians or lawyers are involved, the costs climb further, reaching anywhere from $30,000 to $100,000. For instance, a system processing 100,000 queries monthly with a 5% sampling strategy would face annual costs of $60,000–$120,000.
Although fully automated systems can reduce upfront costs by 30–50%, mistakes that slip through to production can become exponentially more expensive - 10 to 100 times more costly than catching them during evaluation. This creates a 3–5x cost multiplier when human oversight is excluded in high-stakes settings. A practical solution? Strategic sampling. By reviewing 5–10% of outputs - especially those flagged as low-confidence or high-risk - organizations can balance cost and quality effectively.
Ideal Use Cases
Automated metrics are great for measuring numerical accuracy, but they fall short when it comes to subjective evaluations. Human feedback is crucial for assessing tasks where quality is less about numbers and more about nuance, like creativity or cultural appropriateness. Humans excel at catching subtleties that automated systems, bound by predefined rules, tend to miss. Additionally, while machines provide overall accuracy rates, they don’t differentiate between minor mistakes and major blunders - another area where human judgment becomes indispensable.
2. Automated Metrics
Effectiveness for Objective vs Subjective Tasks
Automated metrics shine when it comes to tasks with clear, objective answers. They offer quick, unbiased assessments, which are essential for scaling AI evaluations. For example, tasks like classification, data extraction, or ranking are ideal for these metrics. Imagine checking if an AI correctly flagged an email as spam - automated metrics can deliver a simple yes-or-no result. Similarly, they work well when extracting specific details from documents or ranking search results by relevance.
However, these metrics fall short when it comes to interpreting subtle qualities like empathy or brand tone. While they’re invaluable for structured tasks, they can’t grasp subjective nuances. Still, they help answer a key question for teams: did this model update improve performance?. Automated metrics also have the advantage of evaluating thousands of examples without requiring new human reviews for every iteration.
Scalability and Cost
The cost-effectiveness of automated metrics is a major advantage. They can scale from analyzing hundreds to hundreds of thousands of outputs with minimal additional expense. Even tools like LLM-as-Judge or BERTScore, which are computationally intensive, remain far cheaper than relying on human reviewers. Automated checks for format, JSON structure, safety filters, or length can run almost instantly and at a fraction of the cost.
Consistency and Reliability
One of the standout benefits of automated metrics is their consistency. The same input will always yield the same result. This eliminates issues like rater drift or subjective interpretation. Such deterministic scoring is especially critical for regression detection, where the goal is to identify if a model update has caused a drop in quality - ideally before users even notice. This level of reliability makes automated metrics an essential part of continuous monitoring systems, seamlessly integrating into evaluation workflows.
Ideal Use Cases
The table below highlights the strengths and trade-offs of various evaluation approaches. Automated metrics are perfect for always-on monitoring of production traffic. They excel at tasks like detecting format errors, flagging safety issues, and tracking performance trends over time. Meanwhile, human review is better suited for periodic checks to ensure automated systems stay aligned with broader quality standards. Together, these methods create a balanced framework that combines speed, consistency, and cost-efficiency.
Metric Type | Best For | Consistency | Cost |
|---|---|---|---|
Programmatic Rules | Format, JSON, Safety, Length | 100% (Deterministic) | Very Low |
LLM-as-Judge | Tone, Relevance, Coherence | High (at deterministic settings) | Moderate |
BERTScore | Semantic similarity, Paraphrasing | High | Moderate |
Human Review | Nuance, Policy, Edge cases | Variable | High |
Strengths and Limitations
Each evaluation method brings its own advantages. Automated metrics excel in speed and reliability, delivering results in seconds with consistent output. For example, a single $0.02 API call to an LLM judge can replace the expense of a $200/hour domain expert, making it a cost-effective choice for routine assessments. This efficiency underscores the importance of incorporating automation into evaluation processes.
That said, automation has its drawbacks. Automated metrics often rely on proxies rather than measuring true quality. For instance, metrics like BLEU emphasize word overlap but may overlook how useful or accurate the content really is. Additionally, automated systems can miss up to 34% of evaluation errors due to their inability to fully grasp context. They also tend to favor longer responses, even when those responses are less accurate. When it comes to nuanced areas - like ethical considerations, cultural sensitivities, or maintaining a brand's voice - automated systems struggle. In fact, 47% of AI failures in production stem from issues these systems fail to detect.
Human feedback fills these gaps, despite being more expensive and time-consuming. Experts can identify subtle issues and handle complex edge cases that automated systems might miss. Fully automated systems often see error rates increase by over 40% compared to those supplemented with human oversight. Moreover, skipping human judgment can lead to production failures, potentially increasing costs by 3–5 times. However, human evaluation isn’t without its challenges. Subjectivity introduces variability - agreement between LLM judges on subjective quality averages only 0.52, highlighting inconsistencies in human feedback.
Here’s a quick comparison of these methods:
Dimension | Automated Metrics | Human Feedback |
|---|---|---|
Speed | Fast/Instant | Slower (days/weeks) |
Cost | Low (pennies per API call) | High ($20–$200/hour for experts) |
Scalability | Scales to thousands or more | Limited by reviewer availability |
Consistency | High (repeatable/deterministic) | Variable due to bias and drift |
Best For | Format checks, regression detection, monitoring | Complex quality issues, high-stakes reviews |
The best approach combines these strengths into a hybrid strategy. Automated metrics work well as a first layer for always-on monitoring, quickly catching regressions and performing structural checks. Human evaluation should focus on calibration, high-risk scenarios, and reviewing edge cases. Instead of assessing every output, you can strategically sample 5–10%, prioritizing low-confidence predictions and areas where automation struggles. This hybrid model strikes a balance between speed, cost, and quality, leveraging automation's efficiency while benefiting from the nuanced insights only human judgment can offer.
How Latitude Supports Both Evaluation Methods
Latitude brings together human feedback and automated evaluations in a single platform. Its AI Gateway automatically tracks every interaction during production - inputs, outputs, tool calls, and metadata - without the need for manual code adjustments. This setup emphasizes the importance of combining human insight with the efficiency of automation. By creating a complete record accessible to both automated systems and human reviewers, Latitude ensures seamless collaboration between these two approaches.
The platform functions in two key modes:
Live Mode: Monitors production traffic in real time, conducting automated checks for safety, formatting, and quality.
Batch Mode: Focuses on regression testing against golden datasets, enabling teams to validate changes before deployment.
Teams can implement programmatic rules, such as checks for JSON formatting, length, and safety, alongside LLM-as-judge evaluations for tone and relevance. Edge cases are routed to human reviewers through the built-in Human-in-the-Loop (HITL) framework.
Latitude also offers tools for deeper analysis and refinement. Experts use its annotation interface to review flagged outputs alongside production logs, correlating feedback with specific predictions to fine-tune automated metrics. Feedback can be provided as simple pass/fail judgments or as detailed numerical ratings. For instance, expert ratings can verify whether an LLM judge’s scores for relevance match actual quality standards.
The Interactive Playground allows engineers to retrieve production runs and test prompt variations, making debugging more efficient. For recurring issues, the GEPA system (Guided Exploratory Prompt Adjustment) tests prompt adjustments to address those failures. Additionally, Composite Scores combine results from programmatic rules, LLM evaluations, and human feedback into a single metric. This simplifies reporting while still allowing teams to dig into specific issues when needed.
For example, consider a customer support chatbot. Teams could log all interactions, run nightly relevance checks, and flag low-scoring responses for human review. Experts would then provide feedback using Latitude’s interface, refining evaluation thresholds and informing model retraining. This creates a closed-loop system where automation manages large-scale tasks, and humans address more nuanced challenges. This balanced approach ensures effective and ongoing model monitoring.
Conclusion
Combine human feedback with automated metrics to create a well-rounded evaluation strategy. Automated metrics act as a constant monitoring tool, capable of identifying regressions and scoring outputs on a large scale. Meanwhile, human evaluation ensures quality standards are met by providing the nuanced judgment needed for edge cases and calibration.
For systems handling high production volumes, a practical approach includes using 100% automated monitoring, conducting in-depth analysis on 5% of samples, and reserving human review for 0.5% of critical or escalated cases. This setup ensures thorough oversight without overwhelming your team, while allowing expert reviewers to focus on high-stakes decisions, policy evaluations, and major release approvals.
When transitioning from a human-heavy to an automation-heavy evaluation model, let the data guide you. Make the shift only when the correlation between human and automated scores consistently surpasses a threshold - commonly around 0.75.
Automated metrics excel in speed and consistency, processing over 1,000 examples per minute. However, they can be susceptible to manipulation. On the other hand, human reviewers, though slower (handling 10–50 examples per hour), provide assessments that are harder to manipulate and are better suited for complex evaluations.
FAQs
How do I choose the right mix of human review and automated metrics?
To find the right balance, start by defining your AI evaluation goals. Automated metrics, such as BLEU or ROUGE, are great for handling large volumes of data quickly, but they can overlook more subtle aspects like tone or potential bias. On the other hand, human feedback shines when it comes to catching these nuances, including cultural sensitivities or underlying biases. The most effective strategy often combines both: using automation for routine evaluations and relying on human insight for more complex, nuanced cases. This blend ensures both efficiency and precision in achieving dependable outcomes.
What should I sample for human review (and how much)?
When selecting data for human review, aim for a representative subset that captures a variety of scenarios, including edge cases and common outputs. Pay special attention to critical or ambiguous cases, as these are key for thorough evaluation. A good rule of thumb is to sample about 5-10% of the total outputs - enough to ensure broad coverage without overwhelming the process.
It's also important to focus on high-risk outputs, such as those more likely to contain errors or biases. This helps in assessing how the system performs in practical settings and identifying areas for improvement.
How can I tell if an automated metric matches human judgment?
To determine if an automated metric matches human judgment, compare its outcomes with human feedback using well-defined evaluation standards. Feedback should be clear, actionable, and measurable to ensure meaningful comparisons. Metrics such as accuracy, precision, and F1 scores can provide a numerical way to assess alignment. Incorporating semantic analysis or human review into automated workflows adds an extra layer of validation, ensuring the metrics genuinely reflect human evaluations and consistently deliver high-quality results.



