

Creating effective AI systems requires collaboration between product managers, engineers, and domain experts. Without proper tools, teams risk disorganized workflows, duplicated efforts, and unreliable AI behavior. This article explores tools designed to address these challenges, focusing on features like:
-
Version control : Track prompt changes, experiment safely, and revert when needed.
-
Role-based access : Simplify updates for non-technical team members while engineers handle infrastructure.
-
Evaluation systems : Combine automated, programmatic, and human feedback to ensure prompt quality.
Key platforms include Latitude, enabling safe experimentation and structured workflows, and LangChain, designed for multi-step reasoning and collaborative testing. Other options like Agenta, Flowise, and Braintrust offer tailored solutions for specific team needs.
The right tools transform scattered workflows into efficient systems, helping teams refine prompts and deliver reliable AI products.
Core Capabilities of Prompt Management Tools
Prompt management platforms are designed to streamline collaboration and improve efficiency, especially in teams with diverse expertise. Their core features tackle common collaboration challenges like tracking changes, enabling safe contributions from all team members, and objectively measuring prompt effectiveness. These tools align with Latitude’s focus on safe and efficient AI prompt development.
Version Control and Change Tracking
Version control is a game-changer for managing prompts. By separating draft environments from production-ready prompts , teams can experiment without risk. For example, ParentLab handled 700 revisions in just six months, saving over 400 engineering hours by enabling non-technical experts to iterate independently.
Tools that offer side-by-side comparisons (diffs) make it easy to track changes and their impact on performance. If a new version doesn’t work as expected, teams can immediately roll back by reassigning the previous version as the active prompt. Adding detailed version notes - like “Enhanced error handling for user queries” - creates a clear audit trail, ensuring everyone stays on the same page.
Role-Based Access and Team Collaboration
Once experimentation is safe, structured access makes teamwork more efficient. Permission systems empower product managers and domain experts to make updates directly through a user interface, while engineers focus on managing the infrastructure. This setup eliminates the need for lengthy code reviews or deployment cycles for simple text changes. As Langfuse explains:
When prompts live in Langfuse, non-technical team members update them directly in the UI while your application automatically fetches the latest version. This separation of concerns means prompt updates deploy instantly.
Organizations that adopt structured permission levels have reported a 40-60% reduction in the time it takes to release new AI features. At Midpage, for instance, the Head of Product oversees 80 production prompts, making updates independently so engineers can focus on infrastructure.
Evaluation and Feedback Systems
To ensure quality, robust evaluation systems combine multiple methods: LLM-based assessments, programmatic rules, and manual human reviews. These approaches deliver objective metrics that help teams agree on performance standards. Luis Voloch, CEO of Jimini Health, highlighted the benefits of centralized evaluation:
Using the Prompt Registry, our team of mental health experts create tests, evaluate responses, and directly make edits to prompts without any engineering support.
Built-in commenting tools allow team members to discuss prompt changes directly in the editor, while experimentation frameworks test different versions across datasets to identify the most effective configuration. Observability features track every interaction - inputs, outputs, and performance metrics - offering full visibility into how prompts behave in real-world scenarios. This feedback loop ensures reliability and aligns with Latitude’s commitment to consistent and transparent prompt iteration.
Tools for Managing Multi-Expert Prompt Design
Collaboration across product managers, engineers, and domain experts can be challenging, but certain platforms make it much easier. Here’s a look at tools designed to streamline teamwork in multi-expert prompt design.
Latitude: Open-Source AI Engineering Platform
Latitude stands out as an open-source platform tailored for teams building reliable AI solutions. It features PromptL , a specialized language that incorporates variables, conditionals, and loops, enabling domain experts to craft advanced prompt logic without relying on engineers.
The platform’s Prompt Manager supports safe experimentation, allowing team members to leave feedback directly in the editor using /* comments */ syntax. This ensures that feedback is both immediate and contextually relevant. Additionally, Latitude’s AI Gateway makes it easy to expose prompts as API endpoints.
A key feature of Latitude is its Reliability Loop , a structured workflow that captures real-world inputs and outputs, integrates human annotations, identifies failure patterns, converts those patterns into regression tests, and optimizes prompts using GEPA (Agrawal et al., 2025). Teams using this method have reported 80% fewer critical errors in production and an 8x faster prompt iteration process. This approach highlights essential aspects like version control, feedback integration, and seamless updates.
LangChain for Complex Prompt Workflows
LangChain takes structured collaboration to the next level by enabling multi-step reasoning. Teams can create workflows where the output of one prompt becomes the input for the next. Its LangSmith tool provides execution traces, annotation queues, and production data tracking.
In late 2025, companies like Notion, Stripe, and Airtable reported over 30% improvements in accuracy within weeks of adopting LangChain’s systematic evaluation and collaborative experimentation. LangSmith is available with a free Developer tier, while the Plus tier costs $39 per user per month.
Additional Tools for Multi-Expert Teams
-
Agenta : An open-source experimentation platform that allows teams to host experiments on their own infrastructure. It’s especially useful for organizations requiring full data control, offering features for collaborative testing and prompt refinement.
-
Flowise : A low-code visual builder with a drag-and-drop interface, perfect for creating LLM chains and multi-agent systems without writing code. This tool is ideal for environments where product managers and domain experts need to iterate independently. Flowise is open-source and available as both a self-hosted and managed cloud solution.
-
Braintrust : Designed to unify evaluation efforts, Braintrust enables product managers and engineers to work simultaneously on prompt iterations. Its Loop feature is an AI agent that generates improved prompt versions and custom scorers automatically. The platform is free for up to five users, with a Pro tier priced at $249 per month for five users.
Tool Comparison: Features and Capabilities
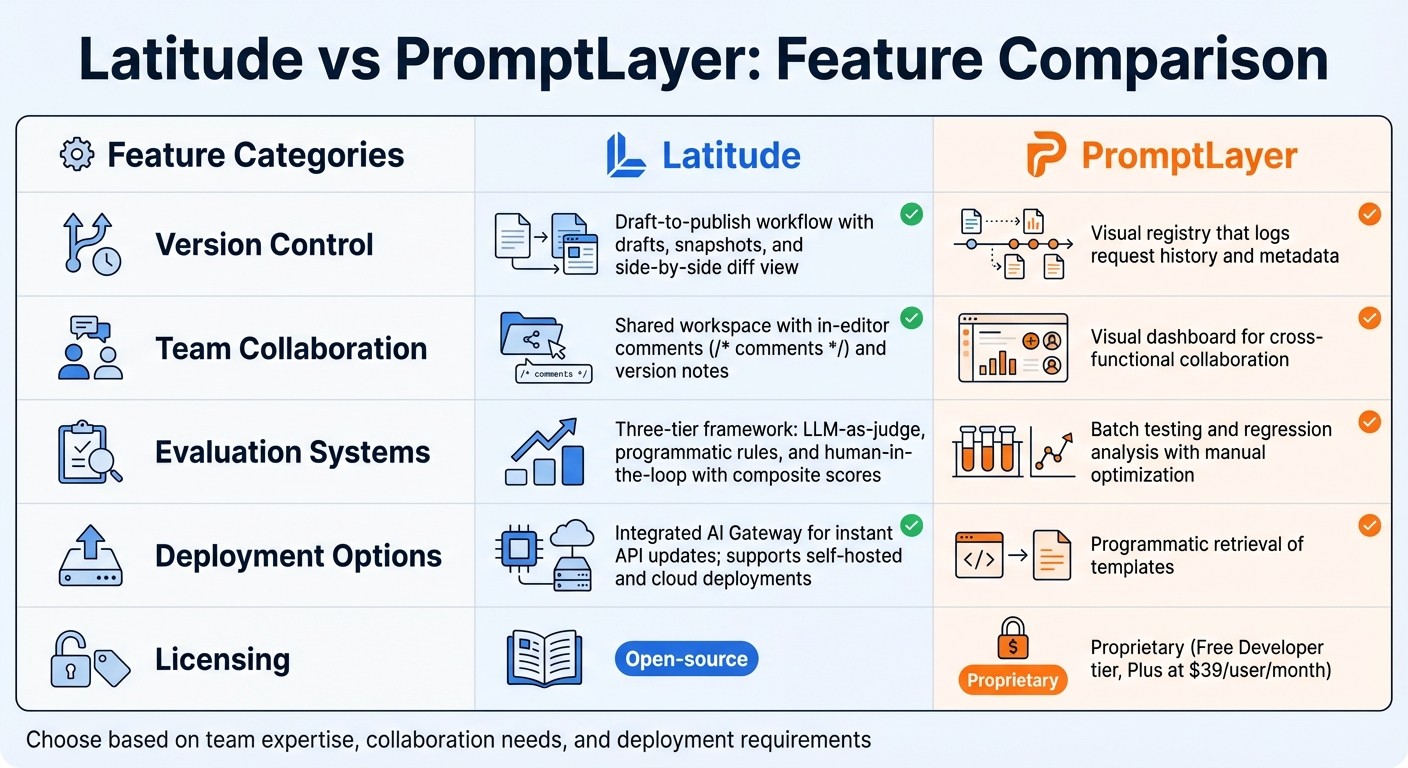
Prompt Management Tools Comparison: Latitude vs PromptLayer Features
Choosing the right tool depends on your team’s workflow and specific needs. Here’s a breakdown of the key features for managing multi-expert prompt design between Latitude and PromptLayer :
| Feature | Latitude | PromptLayer |
|---|---|---|
| Version Control | Offers a draft-to-publish workflow with drafts, snapshots, and a side-by-side diff view | Provides a visual registry that logs request history and metadata |
| Team Collaboration | Features a shared workspace with in-editor comments (/* comments */) and version notes |
Includes a visual dashboard for cross-functional collaboration |
| Evaluation Systems | Utilizes a three-tier framework: LLM-as-judge, programmatic rules, and human-in-the-loop with composite scores | Supports batch testing and regression analysis with manual optimization |
| Deployment Options | Includes an integrated AI Gateway for instant API updates; supports both self-hosted and cloud deployments | Allows programmatic retrieval of templates |
| Licensing | Open-source | Proprietary (Free Developer tier, Plus at $39/user/month) |
The table highlights the core differences, which we’ll explore further. Each tool takes a distinct approach to production-ready prompt management, catering to different team needs.
Latitude stands out for teams that prioritize quick feedback loops and production reliability. Its three-tier evaluation system - combining LLM-as-judge, programmatic rules, and human-in-the-loop methods - ensures thorough quality control. On the other hand, PromptLayer focuses on batch testing and manual optimization, offering a more hands-on approach.
When deciding, consider your team’s technical expertise, collaboration preferences, and deployment requirements to identify the best fit.
Conclusion
Handling multi-expert prompt design effectively requires more than scattered notes and unorganized feedback. The right tools can streamline the process by combining version control, team collaboration, and structured evaluations into a cohesive workflow - transforming experimental prompts into dependable, production-ready AI features.
Platforms like Latitude offer teams a structured approach to reliability, covering the entire lifecycle from initial observation to optimization. As of 2026, the industry is increasingly leaning on centralized platforms that prioritize observability, cross-functional teamwork, and deployment-ready solutions. Whether you’re juggling input from multiple experts or scaling AI features, tools like Latitude help bridge the gap between experimentation and consistent performance.
To keep pace with the evolving demands of AI engineering, invest in platforms that cover every stage—from prompt engineering concepts to deployment. Adopt structured workflows, incorporate peer reviews to vet changes, and rely on automated evaluations to catch issues before they impact users.
The future of AI development belongs to teams that can iterate swiftly without sacrificing quality - and with the right tools, achieving that balance is entirely possible.
FAQs
How does version control help improve prompt design in AI development?
Version control streamlines prompt design in AI development by systematically tracking and managing changes. This approach helps teams document updates, maintain consistency, and easily revert to previous versions when necessary, minimizing errors and ensuring a stable workflow.
With tools like semantic versioning and detailed logs, version control fosters seamless collaboration and clear communication among team members. It also allows for experimenting with variations, comparing results, and refining prompts to achieve better performance - all while keeping the process organized and flexible to meet changing project needs.
What are the advantages of using role-based access for managing AI prompts?
Role-based access brings several advantages when it comes to managing AI prompts. By assigning permissions tailored to each team member’s role, it ensures that individuals interact only with the tools and resources necessary for their responsibilities. This setup minimizes the chances of unauthorized modifications or mistakes, while also boosting security and keeping operations organized.
It also enhances teamwork by simplifying tasks such as prompt reviews and approvals. On top of that, it enables thorough tracking and documentation of changes, making audits and performance assessments smoother. This structured method not only helps maintain the quality of prompts but also creates a secure and dependable workflow.
How do evaluation systems maintain the quality of AI prompts?
Evaluation systems are designed to maintain the quality of AI prompts by using structured methods to test and improve their performance. Automated testing takes place in controlled settings, where prompts are exposed to a variety of inputs to evaluate how accurate, consistent, and relevant their responses are.
On top of that, human feedback is essential for spotting areas that need improvement. By blending automated testing with ongoing input from people, these systems ensure that prompts not only work well but also consistently meet high standards over time.