

When choosing between open-source and proprietary large language models (LLMs), the decision goes beyond technical specs. It’s about balancing transparency, accountability, safety, privacy, and access. Here’s what you need to know:
-
Open-source LLMs prioritize transparency and accessibility. They allow public audits, customization, and local data control. However, they lack centralized accountability, are harder to secure, and pose misuse risks.
-
Proprietary LLMs offer centralized safety measures, compliance, and support. But they limit transparency, can be expensive, and may restrict user control over data and customization.
Each approach has trade-offs. Open-source models empower users but require technical expertise. This includes mastering prompt engineering for developers to optimize model outputs. Proprietary models provide convenience but create dependency on corporations. Your choice should align with your goals, resources, and ethical priorities.
Quick Comparison:
| Ethical Dimension | Open-Source LLMs | Proprietary LLMs |
|---|---|---|
| Transparency | Public weights, limited data/code | Limited, no public access |
| Accountability | Decentralized, harder to enforce | Centralized, clear contact |
| Safety | Risk of misuse, community fixes | Strong controls, limited user input |
| Privacy | Local data control | External server risks |
| Access | Lower cost, wider availability | Expensive, restricted access |
Both systems have pros and cons. Many organizations now combine both to balance control, cost, and security. The key is to evaluate your needs and resources carefully.
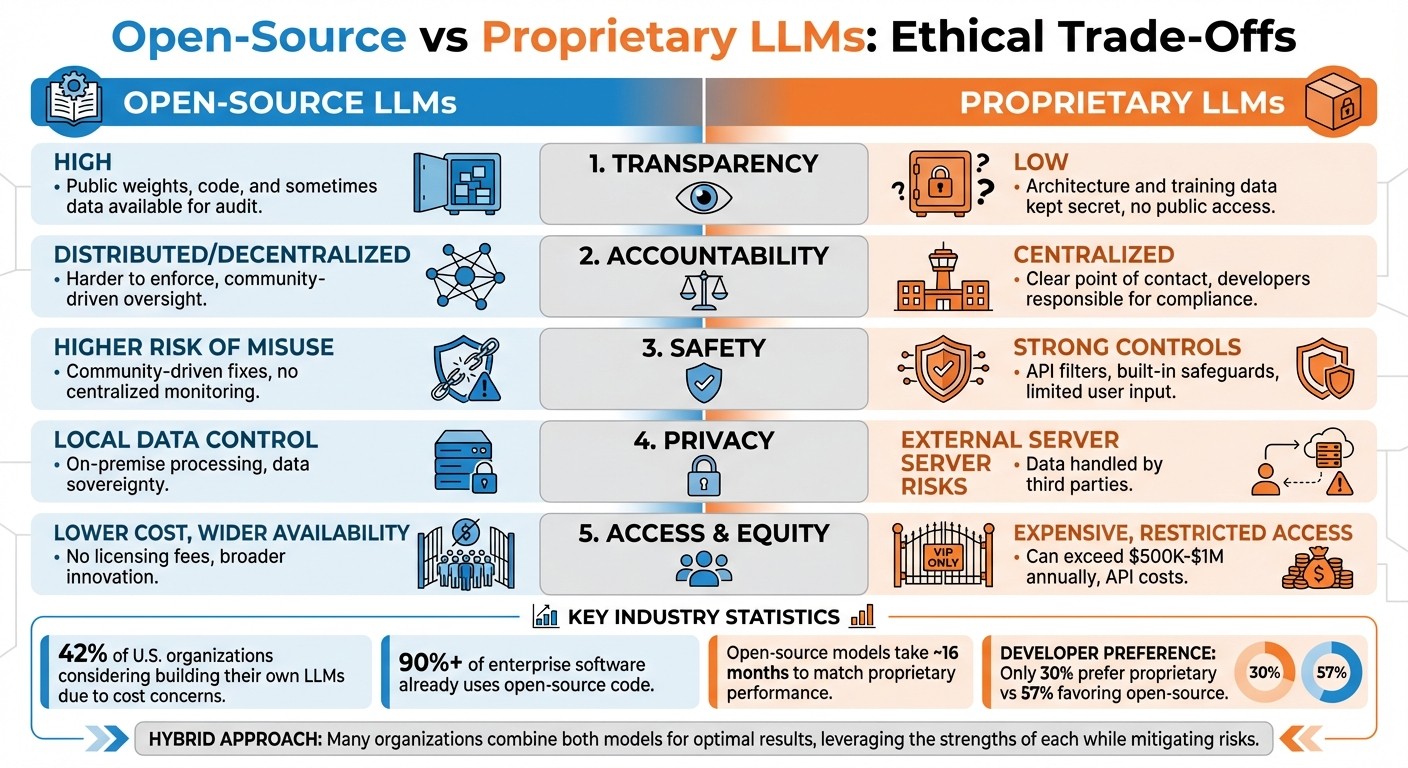
Open-Source vs Proprietary LLMs: Ethical Trade-Offs Comparison
Core Ethical Concepts in LLM Development
When it comes to large language models (LLMs), five key ethical principles - transparency , accountability , access , privacy , and safety - shape how these technologies are evaluated and deployed. These principles play a crucial role in determining whether AI remains concentrated in the hands of a few corporations or becomes a widely available tool for diverse users.
Transparency and Auditability
Transparency refers to how much insight is available into a model’s inner workings - its training data, development processes, and underlying architecture. A 2025 study of 112 advanced LLMs revealed that many so-called “open” models only share their weights while keeping training data and code hidden. Without transparency, biases or unethical practices can easily go unnoticed.
Auditability, on the other hand, ensures that independent researchers can verify and reproduce results. For example, open-source models like BLOOM make their training datasets, such as “The Pile”, accessible for scrutiny. This allows experts to identify and address potential biases. In contrast, proprietary models like GPT-4 do not disclose their training datasets, which limits external verification. This lack of auditability becomes especially concerning in critical fields like healthcare, where understanding how a model makes decisions is essential. Moreover, without transparency, it’s harder to determine who should be held accountable when errors occur.
Accountability and Responsibility
Accountability focuses on who takes responsibility when an LLM fails or causes harm. Proprietary models often provide centralized accountability, meaning the company behind the model handles support, updates, and legal issues. However, these models typically lack external oversight, making it difficult to independently verify their fairness or safety.
Open-source models, in contrast, rely on community-driven oversight to identify errors or biases. While this approach promotes collaboration, it doesn’t always offer clear legal accountability or guaranteed performance standards. Both proprietary and open-source models face challenges in ensuring ethical use, especially without thorough documentation throughout their lifecycle.
Access and Equity
Access determines who can utilize LLMs. Proprietary models often come with licensing fees or usage-based API costs, which can exclude smaller organizations, independent researchers, and developers in lower-income regions. A survey of U.S. CIOs found that 42% of organizations are considering building their own LLMs due to concerns about cost and access.
Open-source models aim to make AI more accessible by eliminating licensing fees. For instance, BLOOM supports 46 languages, making it one of the most globally inclusive LLMs. However, even “free” models require significant infrastructure and technical expertise to operate effectively. This raises an important question: will AI remain a centralized resource, or will it evolve into a decentralized tool that’s accessible to all? Equitable access is just as important as transparency and accountability in shaping the future of AI.
Privacy and Security
Privacy and security concerns strongly influence how organizations adopt LLMs. For example, in May 2023, Samsung banned the use of certain proprietary models after internal source code was leaked. Similarly, Italy’s Data Protection Authority temporarily banned ChatGPT in March 2023, citing concerns about the mass collection of personal data without clear legal justification.
Two main approaches to security dominate the conversation. Proprietary models often rely on “security through obscurity”, limiting access and providing centralized updates to protect users. In contrast, open-source advocates prefer “security through transparency”, allowing the community to identify and fix vulnerabilities. Interestingly, while 52% of organizations express concerns about the security risks of generative AI, over 90% of enterprise software already relies on open-source code - a statistic that suggests fears about open-source LLMs may be overblown.
Safety and Misuse Risks
Safety addresses the possibility of dual use - when a tool designed for good is repurposed for harmful activities. Proprietary models often include built-in safety filters and usage monitoring to prevent misuse, such as generating phishing emails or spam. While these safeguards are effective in the short term, they are not open to external evaluation.
Open-source models, by their nature, are more vulnerable to immediate misuse since they can be freely downloaded and modified. However, their openness also allows for long-term corrections. For example, in January 2025, researchers found that the DeepSeek-R1 model included government-imposed censorship on sensitive historical events. Because the model was open-weight, Perplexity was able to fine-tune a version that removed these censorship filters. Jay Stanley from the ACLU explains:
“With a closed model, nobody has even a chance of fixing censorship, bias, or other perceived flaws. Given the potential power of a dominant LLM, that may be a crucial ability”.
This example underscores a fundamental trade-off: while proprietary models offer immediate safety controls, open-source models empower communities to address ethical concerns over time. Both approaches have their strengths, but their effectiveness depends on how they balance safety with transparency and accountability.
Open-Source LLMs: Ethical Considerations
Open-source large language models (LLMs) bring a new set of ethical challenges compared to proprietary models. While they make AI technology more accessible, they also shift responsibilities from centralized companies to decentralized communities. These dynamics influence how ethical practices are applied to open-source LLMs. Let’s dive into how transparency, access, and security play out in this context.
Transparency and Community Oversight
Open-source models allow researchers to examine the inner workings of AI systems - something proprietary models don’t typically offer. As Nature puts it:
“With open-source LLMs, researchers can look at the guts of the model to see how it works, customize its code and flag errors”.
This level of access helps experts verify results, identify biases, and ensure reproducibility.
However, not all open-source models are equally transparent. A 2025 study of 112 advanced LLMs found that many so-called “open-source” models only share their weights, keeping critical elements like training data and source code hidden. This practice, often called “superficial openness”, limits the community’s ability to fully audit and understand the model. True transparency requires the release of the entire “recipe” - training data, source code, and documentation - not just the final output.
The BLOOM model is an example of genuine openness. Created by more than 1,000 volunteer researchers, BLOOM shared its full training pipeline, including “The Pile” dataset. This allowed experts worldwide to examine the data quality and adapt the model for 46 languages. Jay Stanley from the ACLU highlights the broader implications of this approach:
“Insofar as research is an open scientific process rather than a closed, Manhattan Project-like endeavor, that will lower the chances that any one company or nation will dominate the technology”.
However, distributed oversight comes with its own challenges. While communities can flag issues like biases or errors, accountability becomes murky. No single entity is responsible for updates, legal compliance, or maintaining performance standards. This decentralized model is effective for identifying problems but less so for enforcing solutions.
Transparency is just one part of the equation. Open-source models also have a significant impact on access and innovation. Many of these models have powered viral LLM tools that demonstrate the rapid pace of community-driven development.
Access, Equity, and Innovation
Open-source models remove barriers like licensing fees and API costs, making AI tools available to startups, academic researchers, and public institutions that might not afford proprietary options. This is especially valuable for researchers in lower-income regions and independent developers who often face financial and technical constraints.
Take DeepSeek-V3, for example. Released in October 2025, this model uses a Mixture-of-Experts (MoE) architecture, activating only 37 billion of its 671 billion parameters per forward pass. Despite this efficiency, it achieved an 88.5% exact match on the MMLU benchmark and a 91.6% F1 score on the DROP benchmark. This design allows organizations with limited infrastructure to deploy high-performing models locally.
That said, open-source models often lag behind proprietary ones in cutting-edge capabilities. On average, it takes about 16 months for an open-source model to catch up to the performance of top-tier closed systems.
Privacy, Security, and Operational Requirements
One key advantage of open-source LLMs is data sovereignty. Organizations can run these models locally, ensuring that sensitive data stays within their own infrastructure. This is especially critical in fields like healthcare, finance, and government, where strict privacy regulations are in place.
Proponents of open-source argue for “security through transparency”, where community involvement accelerates the identification and resolution of vulnerabilities. Given that over 90% of enterprise software already relies on open-source code, concerns about its security may be overstated.
However, the burden of managing open-source models falls entirely on the deploying organization. Unlike proprietary models that offer centralized updates and technical support, open-source solutions require organizations to handle compliance, security patches, and performance optimization independently. While the models themselves are free, deploying and fine-tuning them demands advanced skills and robust hardware. This can be a hurdle for smaller teams without dedicated infrastructure.
Misuse and Dual-Use Risks
The transparency of open-source LLMs, while beneficial, also opens the door to misuse. Once model weights are publicly available, developers lose the ability to monitor or restrict their use. For instance, malicious actors can use fine-tuning techniques like LoRA to bypass safety measures embedded in the base model.
This creates risks ranging from cyberattacks to the creation of biological weapons and mass disinformation campaigns. Elizabeth Seger and colleagues caution:
“For some highly capable foundation models likely to be developed in the near future, open-sourcing may pose sufficiently extreme risks to outweigh the benefits”.
However, some experts argue that risks should be assessed based on “marginal risk” - whether the model significantly increases threats compared to existing technologies like search engines or specialized databases. The debate focuses on whether open models provide critical “bottleneck” information that isn’t already accessible elsewhere.
To address these concerns, some developers are adopting “responsible open-sourcing” practices. For example, staged releases make models initially available via API, allowing developers to monitor for misuse before releasing the full weights. While this approach aims to balance transparency with security, it has sparked debate within the open-source community.
Proprietary LLMs: Ethical Considerations
Proprietary large language models operate under a different set of ethical principles compared to open-source models. Instead of shared oversight, these systems centralize control within corporations that manage everything from the training data to deployment policies.
Limited Transparency and Auditability
Proprietary systems often shield their training data, source code, and architectures from public scrutiny, leaving external verification limited to interactions through APIs. This lack of openness raises trust concerns. As noted by Nature :
“Proprietors of closed LLMs can alter their product or its training data - which can change its outputs - at any time”.
A 2023 review of 10 major foundation model developers revealed that none disclosed meaningful information about the downstream effects of their flagship models , such as their impact on users or industries. The Foundation Model Transparency Index also highlighted a general decline in transparency across the ecosystem.
The secrecy extends to the training data itself, which may include non-consensual sources like private social media posts or content from minors. Nature raises concerns:
“The use of proprietary LLMs in scientific studies also has troubling implications for research ethics. The texts used to train these models are unknown”.
Rishi Bommasani from Stanford’s Center for Research on Foundation Models underscores the importance of openness:
“Transparency is a vital precondition for public accountability, scientific innovation, and effective governance”.
This veil of secrecy not only undermines the ability to audit these systems but also concentrates control in the hands of a few.
Centralized Control and Governance
Proprietary models entrust a single company with decisions about safety policies, content moderation, and access controls. This creates a gatekeeping role where one entity decides what the model can and cannot do, often without public oversight or input.
Currently, no major developer provides clear pathways for users to seek redress for harms caused by their flagship models. Without accountability mechanisms, users are left with limited options to report issues or contest decisions.
For example, in early 2025, Perplexity used the open-weight DeepSeek R1 model to fine-tune a version that removed Chinese government censorship on topics like the Tiananmen Square massacre. Such modifications are impossible with proprietary models like GPT-4 orGemini, where providers maintain strict control over output filters.
This centralized control also allows companies to modify or discontinue models at will, forcing users to adapt to new terms or migrate to other systems. This instability poses challenges for long-term research projects and production systems that rely on consistent model behavior. The lack of governance flexibility directly affects operational stability and cost management.
Built-in Safety and Compliance
One advantage of proprietary models is their centralized approach to safety. Providers implement “AI firewalls” to screen prompts, filter harmful content, and apply alignment training to ensure appropriate responses. Before release, these models undergo rigorous safety reviews to address risks like cybersecurity threats or misuse in areas like biotechnology.
Additional safeguards, such as agent sandboxing, configurable network access, and parental controls (introduced in September 2025), add layers of protection for specific applications. For organizations without dedicated security teams, these built-in measures can be helpful.
However, these safety features come at a cost. Users face reduced autonomy and limited flexibility. For instance, some vendors restrict full fine-tuning of advanced models like GPT-4 Turbo. As one analysis explains:
“Proprietary models function as black boxes, making AI governance specialists, compliance officers, and data privacy experts critical for monitoring AI outputs”.
Organizations must trust that the vendor’s safety policies align with their needs - a challenge for those operating across diverse regulatory environments. While these centralized safety measures provide strong protections, they also impose strict limitations on cost and access.
Access Barriers and Cost Structures
Proprietary models often come with steep financial barriers, using usage-based pricing and subscription fees. Many providers charge per token or API call, which can make high-volume usage expensive. Medium-sized businesses may spend over $50,000 annually on API fees, while custom enterprise plans can exceed $500,000 per year. For large-scale enterprise systems, costs can climb to $1 million or more annually when factoring in API fees, dedicated support, and compliance requirements.
These costs can be prohibitive for startups, small businesses, and underfunded institutions. A 2025 survey showed that only 30% of developers preferred proprietary technology , compared to 57% who favored open-source options. Nature warns:
“The downside in the long run is that this leaves science relying on corporations’ benevolence - an unstable situation”.
The publication further notes:
“If prices were to shoot up, or companies fail, researchers might regret having promoted technologies that leave colleagues trapped in expensive contracts”.
Proprietary models also create vendor lock-in , where deep integration into a provider’s ecosystem makes switching costly and technically challenging. As one analysis puts it:
“The convenience of renting comes with dependency, whereas ownership brings freedom at the cost of responsibility”.
Data sovereignty is another concern. For industries like healthcare or finance, proprietary models pose risks by processing user data on external servers, raising questions about data privacy and storage policies. While API-based models reduce initial hardware costs, they introduce long-term expenses through limited customization and potential data privacy issues.
Comparing Ethical Trade-Offs: Open-Source vs Proprietary
Ethical Dimensions Comparison Table
When it comes to ethical trade-offs between open-source and proprietary large language models (LLMs), there’s no one-size-fits-all solution. Each approach comes with its own set of priorities and risks, making it essential to weigh the pros and cons carefully.
| Ethical Dimension | Open-Source LLMs | Proprietary LLMs |
|---|---|---|
| Transparency | High: Weights, code, and sometimes data are open for public audit. | Low: Architecture and training data are often kept secret. |
| Accountability | Distributed: Responsibility for misuse is harder to pinpoint. | Centralized: Developers are the clear point of contact for compliance. |
| Safety | Higher risk of misuse due to lack of centralized monitoring. | Stronger safeguards through API filters and usage policies. |
| Privacy | Local data processing allows for greater control and sovereignty. | Data handled on external servers may lead to privacy concerns. |
| Equity | High: Broadens access and lowers innovation barriers. | Low: Costs and API restrictions can limit access. |
| Governance | Community or multi-stakeholder driven. | Controlled by corporations with a focus on profit. |
The Foundation Model Transparency Index, which uses 100 detailed indicators , highlights that transparency is not an all-or-nothing concept. It spans a spectrum - some models share weights but withhold training data, while others provide thorough documentation but impose restrictions on commercial use. These nuances directly impact how ethical considerations are prioritized for different use cases.
Use Case-Specific Ethical Priorities
The ethical priorities of LLMs vary depending on the industry and its unique needs. For sectors like healthcare and financial services, where strict regulations and audit trails are critical, proprietary models often take the lead. Their centralized accountability offers a clear path for compliance, which is essential in such high-stakes environments.
On the other hand, industries like academic research and public interest organizations value transparency and reproducibility. Open-source models are particularly useful here, as they allow for community-driven modifications to address issues like censorship and bias. Jay Stanley, a Senior Policy Analyst at the ACLU, underscores this point:
“With a closed model, nobody has even a chance of fixing censorship, bias, or other perceived flaws”.
For startups and small businesses, the decision often hinges on cost and flexibility. Proprietary models may provide quicker deployment and integrated support, but their recurring fees can be a significant burden. Interestingly, a February 2024 survey of AI experts found that open-source models typically take about 16 months to catch up with the performance of cutting-edge proprietary models. This narrowing gap makes open-source solutions an increasingly viable option for smaller players.
Engineering Practices to Address Ethical Risks
Whether you’re working with open-source or proprietary models, ethical risks require careful engineering practices to manage effectively. Monitoring and evaluation processes are crucial across the board. Open-source models face the challenge of building usage monitoring from scratch, while proprietary models can be difficult to audit due to restricted access to their inner workings.
Techniques such as Retrieval-Augmented Generation (RAG) and Reinforcement Learning from Human Feedback (RLHF) can enhance factual accuracy and align outputs with safety standards. However, proprietary systems often limit the ability to fine-tune these models further.
Platforms like Latitude offer tools to monitor model behavior, collect expert feedback, and conduct ongoing evaluations. These workflows provide much-needed oversight, filling the gaps in open-source monitoring and strengthening the accountability of proprietary systems. By incorporating such tools, both approaches can better address their ethical challenges.
In addition, a multi-stakeholder governance model - bringing together engineers, compliance officers, domain experts, and affected communities - can help close the accountability gaps in open-source systems while addressing the transparency issues in proprietary ones. This collaborative approach ensures that ethical considerations remain at the forefront, regardless of the chosen model type.
Conclusion
Deciding between open-source and proprietary large language models (LLMs) boils down to aligning the choice with your organization’s ethical goals and operational needs, all while navigating the inevitable trade-offs.
For those prioritizing transparency , reproducibility , and community oversight , open-source models stand out. They promote accessibility and reduce centralized control, making them a strong fit for academic research, public-interest initiatives, and organizations with robust technical expertise.
On the other hand, if your focus is on data sensitivity and strict compliance , proprietary models come with clear advantages. These models offer centralized accountability, built-in safety features, and dedicated support. They’re particularly valuable when internal machine learning expertise is limited or when quick, reliable deployment is essential for business operations.
Interestingly, many organizations are finding value in a hybrid approach. This trend is evident, with over 90% of enterprise software code being open source and 42% of U.S. organizations developing proprietary LLMs alongside it. This suggests that the future likely involves blending both strategies to address specific use cases and ethical considerations.
Regardless of the approach, governance is key. Involve diverse stakeholders - engineers, compliance officers, domain experts, and impacted communities - as part of a multi-layered oversight process. Leverage platforms that support ongoing monitoring and evaluation, ensuring that ethical standards are met consistently. The stakes are far too high to rely solely on vendor assurances or community goodwill; proactive oversight and regular assessments are non-negotiable.
FAQs
What ethical considerations come with choosing between open-source and proprietary LLMs?
When deciding between open-source and proprietary large language models (LLMs), the choice often boils down to a trade-off between openness and accessibility versus control and polished performance.
Open-source models stand out for their transparency. They openly share their code, training data, and architecture, making it easier for researchers and developers to examine them for issues like bias or reproducibility. This openness also levels the playing field, giving smaller teams and independent communities the tools to experiment and create without the burden of costly licenses.
On the flip side, proprietary models typically offer a more refined user experience. They often come with access to larger datasets, better optimization, and built-in safeguards that enhance reliability. Yet, their closed nature raises some red flags - independent oversight is limited, ethical concerns can be harder to address, and control of these powerful tools remains concentrated in the hands of a few organizations.
In the end, the decision hinges on priorities: whether the focus is on fostering transparency and collaboration or on leveraging the refined capabilities and control of proprietary solutions. Both paths come with their own set of ethical considerations and challenges.
Why is transparency important for holding LLMs accountable?
Transparency plays a crucial role in maintaining accountability when it comes to large language models (LLMs). By providing access to details such as model architecture, training data sources, and weight files, developers make it easier for others to understand how outputs are created, spot potential biases, and evaluate whether the model aligns with ethical guidelines. This level of openness enables audits, impact evaluations, and ensures adherence to regulations.
Platforms like Latitude push this concept further by fostering collaboration among engineers and domain experts to examine and refine models together. This collective approach not only tackles biases more effectively but also offers organizations concrete proof of compliance with U.S. regulations and internal policies. Essentially, transparency turns LLMs into systems that are easier to monitor, assess, and enhance.
Why would an organization consider a hybrid approach to using LLMs?
A hybrid approach lets organizations tap into the best of both worlds - open-source and proprietary large language models (LLMs). By using commercial APIs for tasks like complex reasoning or code generation, they can access cutting-edge performance. At the same time, open-source models allow them to keep tighter control over sensitive or regulated data, ensuring compliance with privacy laws and industry-specific rules. This dual approach also helps avoid over-dependence on a single vendor.
Another advantage? It can save money. Proprietary models often come with steep usage fees, while open-source models can be scaled more affordably once the necessary infrastructure is in place. Plus, having a hybrid setup acts as a safety net. If a commercial service goes down or changes its policies, self-hosted open-source models can step in to keep things running smoothly.
Platforms like Latitude make it easier to build and manage these hybrid systems. They allow teams to collaborate seamlessly and deploy production-ready LLM features across both proprietary and open-source setups with flexibility and efficiency.