

Fine-tuning large language models (LLMs) isn’t just about using massive datasets. It’s about finding the right balance between dataset size , data quality , and computational resources. Here’s the key takeaway: high-quality, well-matched datasets often outperform larger, poorly curated ones. For example, studies show that scaling from 2,000 to 207,000 examples can boost translation performance by 13 BLEU points, but only when the data aligns with the task.
Key Points:
-
Small datasets can work well for specialized tasks if paired with strong pre-trained models and techniques like LoRA or prompt tuning.
-
Large datasets improve generalization but require more compute and careful composition to avoid diminishing returns.
-
Data quality matters most : Clean, task-aligned data consistently outperforms large, noisy datasets.
-
Fine-tuning success depends on monitoring performance, addressing failure points, and iterating with feedback.
To optimize fine-tuning, focus on targeted dataset creation, efficient methods like PEFT, and continuous evaluation to refine results.
How Dataset Size Affects Fine-Tuning Performance
The size of your dataset plays a crucial role in fine-tuning performance, working in tandem with model size and the amount of pre-training data. This relationship follows a power-law scaling pattern: when these factors are well-balanced, performance improves steadily. However, if they’re misaligned, you may see diminishing returns or even performance drops.
Pre-training acts as a multiplier for your dataset size. A well-pre-trained model can achieve strong results with far less task-specific data compared to training a model from scratch. In fact, using a pre-trained model often provides more value than collecting significantly more examples.
“Pre-training effectively multiplies the fine-tuning dataset size.” - Danny Hernandez, Jared Kaplan, Tom Henighan, and Sam McCandlish
That said, adding more data doesn’t always yield the same level of improvement. As datasets grow larger, the performance gains tend to slow down. This diminishing returns pattern spans across model size, dataset size, and compute resources. It’s a key consideration when deciding whether to focus on a small, targeted dataset or a large, diverse one.
Another critical factor is how well the pre-training data aligns with the task-specific data. Even if adding more data reduces cross-entropy loss, task-specific metrics like BLEU scores for translation might not improve - or could even worsen - if the data distributions don’t match. This highlights why more data isn’t always the answer to better performance.
The dynamics of dataset size call for tailored strategies, as small and large datasets each come with unique challenges and advantages.
Small Datasets: When They Work Best
With the help of large-scale pre-training, small datasets can deliver impressive results, even with just hundreds or thousands of examples. This is especially true in specialized domains where collecting large amounts of data isn’t feasible. Larger models, in particular, are more efficient with limited data, achieving strong performance with relatively few examples.
Techniques like LoRA (Low-Rank Adaptation) or prompt tuning are especially effective in data-scarce scenarios. These methods update only a small portion of the model’s parameters, reducing computational costs and helping to prevent catastrophic forgetting - where a model loses its general capabilities while overfitting to a small dataset. However, when scaling these parameter-efficient methods, their impact is generally less pronounced than simply increasing the dataset size or using a larger model.
Despite these advantages, small datasets have their limits. When the model size far outweighs the available data, there’s a risk of overfitting - where the model memorizes the training examples instead of learning to generalize. This issue is particularly challenging in tasks requiring nuanced pattern recognition or in domains with high variability. In such cases, the best fine-tuning approach depends heavily on the task. For example, studies in bilingual machine translation and multilingual summarization reveal that the optimal method varies based on the task and data volume.
Large Datasets: Benefits and Challenges
Large datasets offer different strengths, particularly in improving generalization. By exposing the model to a wide variety of examples, large datasets help it recognize patterns more effectively. When fine-tuning larger models, having ample data becomes even more critical. Research shows that scaling the model size often yields greater performance gains than expanding the pre-training dataset.
The composition of a large dataset is just as important as its size. The dataset’s volume - a combination of the number of examples and their average token length - plays a key role in performance, especially when compute resources are limited. For instance, two datasets with the same total token count can produce different results depending on whether the tokens are distributed across many short examples or fewer, longer ones.
“Data composition significantly affects token efficiency… dataset volume plays a decisive role in model performance.” - Ryan Lagasse, Aidan Kierans, Avijit Ghosh, and Shiri Dori-Hacohen
However, large datasets come with their own set of challenges. The computational costs grow significantly, requiring more GPU hours, higher memory, and longer training times. Additionally, labeling such massive datasets can be expensive and time-consuming.
Another challenge is identifying the point of diminishing returns. Power-law scaling shows that each 10× increase in dataset size delivers progressively smaller performance improvements. Being aware of these thresholds can help you allocate your resources more effectively.
Choosing the Right Dataset Size
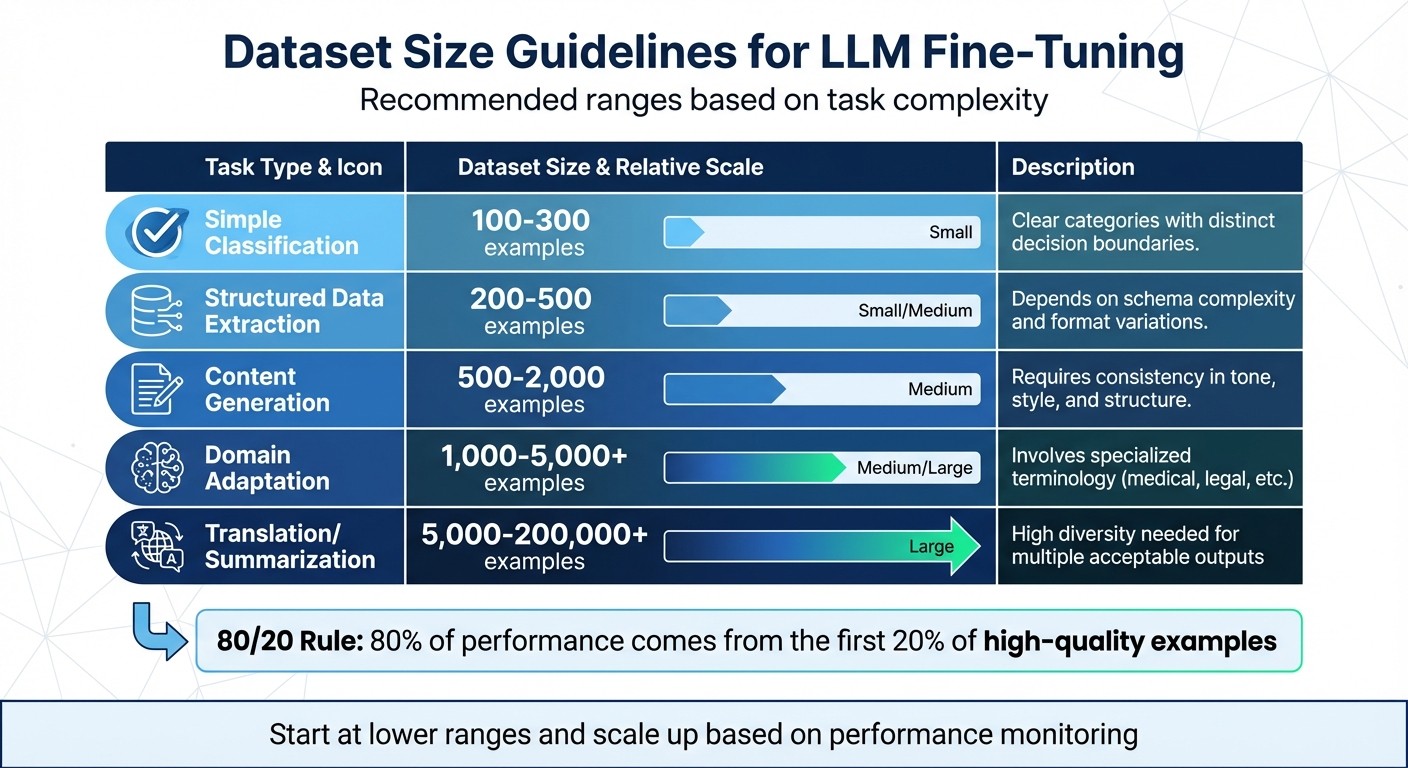
Dataset Size Guidelines for LLM Fine-Tuning by Task Complexity
Picking the right dataset size depends on your task and the resources you have, not on hitting some arbitrary number. The complexity of your goal should guide your decision, as there’s no universal rule that fits every situation.
For simple tasks like classification or entity extraction , you might only need 50 to 100 examples. OpenAI’s documentation highlights that even this small amount can noticeably influence model performance. On the other hand, complex tasks like translation or summarization often demand much larger datasets - ranging from 5,000 to over 200,000 examples - to capture the necessary subtleties and variations.
Take this example: in September 2024, researchers Inacio Vieira, Will Allred, and their team worked with Llama 3 8B Instruct for translation across five language pairs. Using just 1,000 to 2,000 segments for fine-tuning actually reduced performance compared to the baseline. However, when they scaled up to 207,000 segments, they achieved a 13-point jump in BLEU scores and a 25-point boost in COMET scores.
If your pre-training data already matches your target domain, you’ll need fewer task-specific examples. But if the alignment isn’t strong, adding more examples could actually hurt performance. These recommendations tie back to balancing dataset size, quality, and computational costs.
Dataset Size Guidelines for Different Use Cases
Here’s a table summarizing practical dataset size ranges based on task complexity. These aren’t fixed rules but can serve as a solid starting point for your fine-tuning efforts.
| Task Type | Recommended Dataset Size | Characteristics |
|---|---|---|
| Simple Classification | 100–300 examples | Clear categories with distinct decision boundaries |
| Structured Data Extraction | 200–500 examples | Depends on schema complexity and format variations |
| Content Generation | 500–2,000 examples | Requires consistency in tone, style, and structure |
| Domain Adaptation | 1,000–5,000+ examples | Involves specialized terminology (e.g., medical, legal) |
| Translation/Summarization | 5,000–200,000+ examples | High diversity is needed for multiple acceptable outputs |
Starting at the lower end of these ranges and scaling up as needed is often a smart approach. For instance, a production classification system can exceed 90% accuracy with just 150 examples across five categories. This follows the 80/20 rule : about 80% of performance improvements can come from the first 20% of well-chosen, high-quality examples.
Before diving into large-scale data collection, test your base model with a few-shot approach using your target examples. If the results are promising, you might not need a massive fine-tuning dataset. Also, perform a coverage analysis - map your training examples to expected production scenarios. Aim for at least 20 to 30 examples for each major category or input type.
While dataset size matters, data quality plays an even bigger role in effective fine-tuning.
Why Data Quality Matters More Than Size
When it comes to fine-tuning, the quality of your dataset consistently outweighs its size. Research from Meta AI shows that a smaller, well-curated dataset can outperform a larger, mediocre one. The difference boils down to three critical factors: task alignment, data cleanliness, and domain representation.
-
Task alignment : Your training examples should closely match what the model will encounter in production. If the data format doesn’t mirror real-world use, the model won’t learn the right task.
-
Data cleanliness : This involves removing duplicates, fixing inconsistencies, and ensuring accurate labels. For example, if human annotators only agree on 70% of labels in a text extraction task, the model’s accuracy will likely hit a similar ceiling.
-
Domain representation : Your dataset should reflect the real-world scenarios your model will face. Instead of adding examples indiscriminately, focus on where your model struggles and add targeted examples to address those issues.
OpenAI sums it up well:
“If you have to make a tradeoff, a smaller amount of high-quality data is generally more effective than a larger amount of low-quality data”.
In other words, 1,000 carefully chosen examples will serve you far better than 10,000 mediocre ones. Focus on aligning your data with the task, keeping it clean, and ensuring it represents the domain accurately. That’s how you set your model up for success.
Fine-Tuning Strategies for Small Datasets
Small datasets can still deliver impressive results with the right strategies. Two key approaches are parameter-efficient fine-tuning methods, which minimize the number of trainable parameters, and data augmentation , which maximizes the utility of available data.
Parameter-Efficient Fine-Tuning Methods
Parameter-efficient fine-tuning (PEFT) allows you to adapt large language models by updating fewer than 1% of their parameters. This drastically reduces memory usage and training time while maintaining the base model’s general capabilities more effectively than full-model fine-tuning.
One popular PEFT method is Low-Rank Adaptation (LoRA). Instead of modifying all weights, LoRA introduces small, trainable matrices into the transformer layers. While LoRA may not match the performance of full-model fine-tuning on specific tasks, it excels at preserving the base model’s broader abilities.
Another approach involves Prefix Tuning and P-Tuning v2. These techniques add trainable prefix vectors to the model’s input or hidden layers without altering the original weights. For augmented datasets, combining prefix tuning with a contrastive loss function can help the model better distinguish sentence embeddings, leading to improved outcomes.
If performance on a small dataset remains insufficient, consider switching to a larger base model while still employing PEFT. Larger models often yield better results, though PEFT methods may take longer to converge in low-data scenarios compared to full-model tuning.
Beyond fine-tuning methods, data augmentation plays a critical role in enhancing small datasets.
Data Augmentation and Synthetic Data Generation
Data augmentation complements PEFT by increasing dataset size through transformations and synthetic data creation. Leveraging high-quality public datasets for augmentation often outperforms generating synthetic data from scratch.
In April 2024, researchers Saumya Gandhi and Graham Neubig from Carnegie Mellon University introduced DataTune, a technique for transforming existing public datasets into task-specific formats. Their work, tested on the BIG-Bench benchmark, showed that DataTune-enhanced datasets improved performance by 49% compared to few-shot prompting and by 34% over traditional synthetic data generation methods.
“Dataset transformation significantly increases the diversity and difficulty of generated data on many tasks”.
Other proven augmentation methods include EDA, Back Translation , and Mixup. EDA creates variations by replacing synonyms or inserting random words, while Back Translation diversifies data by translating text into another language and back. Mixup blends examples to create new, intermediate data points. These techniques are especially effective when paired with methods like LoRA and P-Tuning v2.
For those with access to large unlabeled datasets, principled data selection can identify samples that closely match the target task’s distribution. This aligns pre-training with the specific task before fine-tuning. Modern selection methods can process millions of samples in just one GPU hour.
While data augmentation generally improves performance, its impact varies by task. In some cases, it may even hinder results, particularly for very challenging tasks or when applied to extremely large models.
Monitoring and Improving Fine-Tuning Results
Fine-tuning doesn’t stop once training wraps up. Ongoing monitoring is key to figuring out what’s working and where the model might need adjustments.
Tracking Fine-Tuning Performance
Start by splitting your dataset into training and test sets. The test set serves as your benchmark to evaluate how well the model performs after training is complete. Relying solely on training loss won’t give you the full picture - use automated metrics to assess performance. For example:
-
Perplexity : Measures language fluency.
-
BLEU andROUGE: Evaluate summarization and translation quality.
-
F1-Score and Accuracy : Useful for classification tasks.
For production models, dig deeper by tracking user satisfaction metrics like thumbs up/down ratings, task completion rates, and how often human intervention is needed to fix errors.
Still, automated metrics can only go so far. Human evaluation remains the most reliable way to assess things like factual accuracy, relevance, coherence, fluency, and safety. For instance, in a 2026 fine-tuning project using Wikipedia data on the 2020 Summer Olympics, OpenAI showed that 74.3% of relevant paragraphs could be retrieved within a 2,000-token limit - a critical metric for workflows involving search or retrieval-augmented generation (RAG) systems.
To spot overfitting, compare training loss with validation loss. If the model isn’t learning as expected, try increasing the number of epochs slightly, perhaps by one or two. However, if the outputs become repetitive or lack diversity, scale back the epochs instead.
Using Feedback to Improve Datasets and Models
Once you’ve monitored performance, use that data to fine-tune both your model and dataset. Human feedback plays a big role in turning an average model into a dependable one. A great way to do this is through Human-in-the-Loop (HITL) labeling. Here, language models generate initial responses, and humans step in to edit or rank them. This approach speeds up data collection compared to creating everything from scratch.
Focus feedback on specific failure points. Rather than adding more data blindly, target areas where the model struggles - like logic errors, style mismatches, or excessive refusals. Then, include human-curated corrections to address those gaps. For example, if the model frequently declines to answer, check if your training data is overloaded with negative examples.
Consistency among human annotators is another factor to watch. If labelers only agree on 70% of cases, your model’s performance will likely hit a similar ceiling. To improve consistency, ensure all human-labeled examples follow a standardized format and tone.
For more advanced improvements, consider Reinforcement Learning from Human Feedback (RLHF). This method combines supervised fine-tuning with human rankings of model outputs to train a reward model. That reward model then guides further learning. Using RLHF, OpenAI’s 1.3 billion-parameter InstructGPT outperformed the much larger 175 billion-parameter GPT-3 in human evaluations, despite being 100 times smaller.
Even a small number of high-quality, human-curated examples can make a big difference. OpenAI found that adding just 50 to 100 such examples significantly boosted model performance.
How Latitude Supports Fine-Tuning Improvement
Latitude takes the guesswork out of fine-tuning by offering a structured workflow that integrates feedback loops. This workflow ensures that model behavior is monitored, feedback is gathered, and iterations happen efficiently. Latitude, an open-source AI engineering platform, is designed specifically for building reliable AI products ready for production.
Here’s how it works: Latitude captures real-world interactions directly from production logs. These interactions are then curated into high-quality datasets that can be exported as CSV files or converted to JSONL format. It also enables side-by-side comparisons of fine-tuned models with their original base versions, making it easier to evaluate performance. To make collaboration smoother, Latitude includes a Git-like version control system, which helps teams manage drafts of prompts and datasets without wasting time on incomplete or messy data.
This seamless workflow connects production logs, data curation, fine-tuning, and evaluation into a single loop. Whether you’re working with 100 examples or scaling up to datasets with thousands of entries, Latitude makes it easier to identify and address areas where your model can improve.
Conclusion
The strategies discussed make one thing clear: fine-tuning large language models isn’t about collecting the biggest dataset - it’s about striking the right balance between quality, size, and compute resources. Research shows that 50 to 100 well-crafted examples often outperform massive datasets filled with poorly curated data. When it comes to fine-tuning, quality consistently beats quantity.
The practical approach starts with addressing specific failure points. Focus on adding examples that directly target these weaknesses. If you’re working with limited GPU hours or memory, consider using Parameter-Efficient Fine-Tuning methods like LoRA. These methods not only save resources but also help prevent issues like catastrophic forgetting.
Data composition plays a pivotal role, too. Deduplicate your training set, standardize outputs, and introduce variety through paraphrasing. Interestingly, repeating a well-filtered dataset for up to ten epochs can deliver better results than training a dataset ten times larger for just one epoch.
The best fine-tuning efforts treat data curation as an ongoing process. Continuously monitor real-world performance, gather targeted feedback, and refine both your dataset and model. This iterative approach ensures you achieve better outcomes with fewer resources. Tools like Latitude can support this process, making it easier to maintain and improve model performance over time.
FAQs
How do I know when adding more fine-tuning data stops helping?
When you keep adding more data for fine-tuning, there comes a point where the performance gains level off. Studies indicate that while larger datasets can be helpful, they often lead to diminishing returns, particularly if the data is already of high quality. The best way to know when you’ve hit this point is to closely monitor validation performance during fine-tuning. If adding more data doesn’t lead to noticeable improvements, it’s likely time to stop. Striking the right balance between dataset quality, the complexity of the task, and the actual improvements you observe is crucial for figuring out the ideal dataset size.
Should I use LoRA/PEFT or full fine-tuning for my dataset size?
For smaller or moderately sized datasets, methods like LoRA under the PEFT (Parameter-Efficient Fine-Tuning) category tend to work efficiently while delivering strong results. On the other hand, if you’re working with large datasets and need to push for the highest possible performance, full fine-tuning is often the better option. The choice ultimately depends on the size of your dataset and the level of performance you’re aiming for.
How can I improve data quality fast without collecting more examples?
Improving data quality doesn’t always mean collecting more data. Instead, focus on curating and refining what you already have. Start by prioritizing relevance and accuracy - eliminate noisy or low-value entries that could skew results. Using structured selection techniques can help you maximize the dataset’s effectiveness. By aligning your data with the specific task and ensuring it accurately represents the problem at hand, you can boost model performance significantly - without needing to gather more samples. This approach saves both time and resources while delivering better fine-tuning results.