

Multimodal audio-text systems combine speech and text to process and understand information more effectively. These systems use components like audio encoders, modality adapters, and large language models (LLMs) to align and integrate audio and text data. Key techniques for merging these inputs include concatenation and cross-attention mechanisms, enabling better performance in tasks like transcription, accessibility tools, and conversational AI.
Key Takeaways:
-
Components : Systems rely on audio encoders (e.g., Whisper, HuBERT), adapters to align data, and LLMs for processing.
-
Fusion Strategies : Early fusion (concatenation), late fusion (cross-attention), and hybrid methods improve integration.
-
Applications : Used in meeting assistants, customer service, audiobooks, and accessibility tools.
-
Challenges : Latency, noise management, and computational demands are common hurdles.
-
Optimization Tips : Use high-quality audio preprocessing, efficient ASR integration, and well-structured prompts for LLMs.
For example, models like VITA-Audio and SpeakStream have achieved faster processing times and lower latency, showcasing advancements in this field. Continuous monitoring, clear prompts, and effective error handling are essential for maintaining performance and reliability.
Architecture Principles for Multimodal Systems
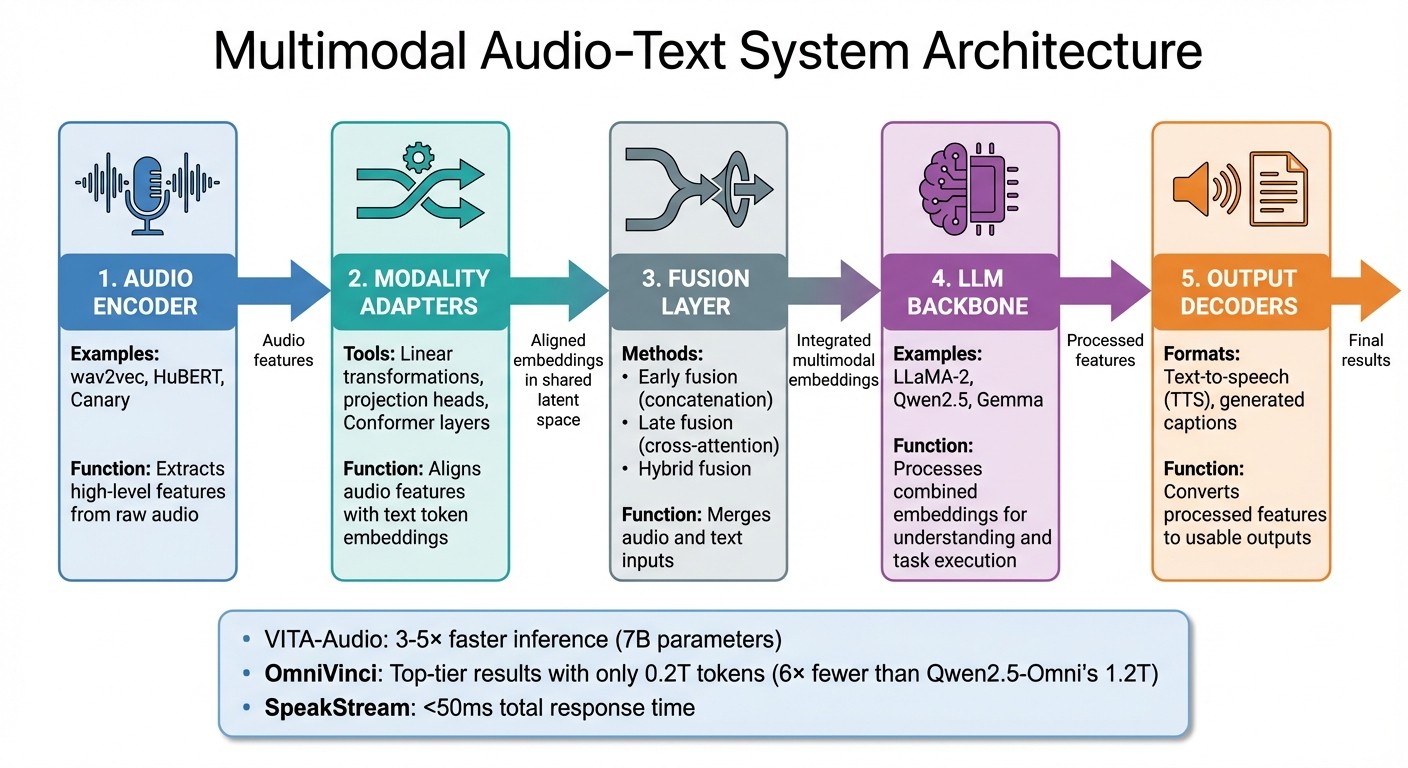
Multimodal Audio-Text System Architecture: 5 Core Components and Data Flow
Building reliable multimodal systems means integrating audio and text pipelines with precision, ensuring minimal delays and high accuracy.
System Architecture Components
A well-designed multimodal audio-text system revolves around five key components working seamlessly:
-
Audio encoder : This extracts high-level features from raw audio using models like wav2vec, HuBERT, or Canary. These models process audio signals to identify patterns and features necessary for downstream tasks.
-
Modality adapters : These adapters align audio features with text token embeddings, often through tools like linear transformations, projection heads, or Conformer layers. Their role is to map both modalities into a shared latent space for smooth integration.
-
LLM backbone : At the system’s heart, the large language model (e.g., LLaMA-2, Qwen2.5, Gemma) processes these combined embeddings, enabling understanding and task execution.
-
Fusion layer : This merges audio and text inputs, either by concatenating embeddings or using cross-attention mechanisms to ensure effective integration.
-
Output decoders : These convert processed features back into usable formats, such as text-to-speech (TTS) outputs or generated captions.
These design choices can significantly enhance efficiency. For instance, in May 2025, researchers Zuwei Long and Yunhang Shen introduced VITA-Audio , a groundbreaking multimodal model capable of generating audio output during its first forward pass. By incorporating a Multiple Cross-modal Token Prediction (MCTP) module, VITA-Audio achieved 3–5× faster inference at the 7B parameter scale compared to conventional models. Similarly, OmniVinci set a new standard for performance, achieving top-tier results while using only 0.2T tokens - six times fewer than Qwen2.5-Omni’s 1.2T tokens.
Audio and Text Fusion Strategies
Once the core components are in place, the challenge lies in fusing audio and text efficiently. Several strategies address this:
-
Advanced early fusion : This approach concatenates audio and text embeddings along the time dimension before feeding them into the language model. While this provides direct access to speech details, it also increases computational demands.
-
Late fusion : Here, cross-attention mechanisms allow text embeddings to attend to speech embeddings, extracting task-specific details. For example, the BESTOWmodel uses this method to filter information before the language model processes it, reducing system overhead.
-
Hybrid fusion : This combines elements of early and late fusion, employing tools like relation graphs or hierarchical stages to encode structured links across modalities.
Temporal alignment also plays a critical role. Techniques such as Temporal Embedding Grouping (TEG) and Constrained Rotary Time Embedding (CRTE) maintain both local and global context by using timestamps and multi-scale frequencies. For example, applying a constrained time horizon (Tmax) in rotary time embeddings prevents the model from overreacting to minor timestamp variations.
These fusion strategies not only improve integration but also influence system responsiveness, a crucial factor in real-world applications.
Latency and Reliability Requirements
The architecture and fusion strategies directly affect latency and reliability - key factors for conversational systems. Low latency is especially important for real-time interactions. In October 2025, Apple researchers, including Richard He Bai and Zijin Gu, unveiled the SpeakStream system , which ran on a Mac Mini with an M4 Pro chip and 64 GB of RAM. This system achieved a total response time of under 50 milliseconds, thanks to a decoder-only architecture and a streaming vocoder called VocStream. As Richard He Bai explained:
“The latency bottleneck of traditional text-to-speech (TTS) systems fundamentally hinders the potential of streaming large language models (LLMs) in conversational AI.”
To reduce latency, techniques like causal convolutions in vocoders and key-value caches in transformers can be employed to reuse prior context. For improved reliability, especially in noisy environments, synchronized modalities like lip movements can enhance performance under high noise levels. Meanwhile, unsynchronized context, such as images, proves helpful in moderate noise conditions.
Audio Ingestion and Processing
Getting audio ingestion right is crucial for ensuring accurate transcription and smooth integration with large language models (LLMs). It sets the stage for reliable performance in multimodal systems.
Audio Capture and Preprocessing
When capturing audio, aim for a sampling rate of 16,000 Hz or higher. For telephony sources that use 8,000 Hz , stick to the native rate to avoid introducing artifacts from resampling.
Whenever possible, use lossless codecs like FLAC or LINEAR16 (PCM). If bandwidth is a concern, codecs like AMR_WB or OGG_OPUS are better alternatives to MP3. Position microphones close to speakers to improve the signal-to-noise ratio.
Avoid applying noise reduction or echo cancellation before sending audio to automatic speech recognition (ASR) services. According to Google Cloud:
“Applying noise-reduction signal processing to the audio before sending it to the service typically reduces recognition accuracy. The service is designed to handle noisy audio”.
Similarly, turn off Automatic Gain Control (AGC) to maintain audio quality.
Set input levels so that peak speech remains between ‑20 and ‑10 dBFS , which prevents clipping while ensuring a strong signal. For high-quality recordings, keep total harmonic distortion below 1% in the range of 100 Hz to 8,000 Hz at 90 dB SPL.
In multi-speaker environments, record each speaker on a separate channel whenever possible. If you need to combine channels for single-channel models, downmix by averaging the channels instead of dropping one. For streaming workflows, process audio in 100-millisecond frames to balance latency and efficiency.
By following these steps, you can ensure the audio is well-prepared for accurate transcription and real-time processing.
ASR Integration Methods
The choice between streaming and batch ASR depends on the use case. Batch ASR processes complete audio files, making it unsuitable for live interactions. Streaming ASR, on the other hand, processes audio in chunks, enabling real-time responses.
For instance, AssemblyAI’s Universal-Streaming model provides transcripts in about 300 milliseconds. The service costs USD $0.15 per hour of session duration, with an optional “Keyterms Prompting” feature for USD $0.04 per hour that can improve accuracy for specialized terminology by up to 21%.
Turn detection settings also play a critical role. Aggressive settings deliver a time-to-first-token (TTFT) of around 200ms , with an end-to-end latency of approximately 500ms - ideal for quick interactions like IVR confirmations. Conservative settings, with a latency of about 1,200ms , work better for complex scenarios like medical dictation.
| Configuration | TTFT | End-to-End Latency | Best Use Case |
|---|---|---|---|
| Aggressive | ~200ms | ~500ms | Quick confirmations, IVR |
| Balanced | ~300ms | ~800ms | General customer support |
| Conservative | ~400ms | ~1,200ms | Complex instructions, Medical |
When feeding ASR output directly to LLMs, disable text formatting like punctuation and capitalization. AssemblyAI notes:
“LLMs don’t need formatting - raw text works perfectly. Formatting adds ~200ms latency with zero benefit for voice agents”.
To save additional time, use the “utterance” field in streaming transcripts to begin LLM processing before a turn officially ends, shaving off 200–500ms.
Text Normalization for LLMs
Once transcription is complete, normalize the text to ensure compatibility with LLMs, especially for U.S.-specific contexts. Dates should follow the MM/DD/YYYY format, currency should appear as USD $ , and measurements should use imperial units like feet, miles, and pounds.
While modern LLMs handle raw text well, you can use an LLM as a “punctuation assistant” to refine transcripts. This includes adding proper punctuation, converting spoken numbers into standard formats (e.g., “four zero one k” to “401(k)”), and correcting industry-specific acronyms.
For English-only workflows, filter out non-ASCII characters to avoid issues like Unicode character injection. Also, remove any leading silence from audio files before processing. Models like Whisper may misinterpret or hallucinate during the initial moments of a recording if silence remains.
For multimodal systems such as Gemma 3n, audio preparation involves converting stereo files to mono-channel, 16 kHz float32 waveforms within the range [-1, 1]. These models process approximately 6.25 tokens per second of audio.
Improving LLM Performance with Multimodal Inputs
Once transcription and normalization are complete, the next step is refining LLM outputs. This involves crafting precise prompts, managing context efficiently, and implementing solid error-handling techniques. These optimizations are key to ensuring smooth multimodal interactions.
Prompt Design for Audio-Derived Text
To create effective prompts, structure them into distinct sections like Role , Objective , Tone , Context , Reference Pronunciations , Tools , and Safety. This organization helps avoid “instruction bleed”, where rules from one section unintentionally influence another.
For named entities, use phonetic contextualization to improve accuracy. A three-step method - identifying entity spans, finding similar names using Normalized Phonetic Distance, and applying context-aware decoding - has been shown to reduce error rates from 37.58% to 9.90%. Keep the list of phonetically similar candidates manageable, ideally around 10 names , as exceeding 20 can introduce unnecessary noise. For alphanumeric inputs, instruct the model to separate digits (e.g., “4-1-5”) to minimize misinterpretation.
Even small adjustments in wording can make a difference:
“We replaced ‘inaudible’ with ‘unintelligible’ for unclear audio instructions, which improved handling of noisy inputs”.
Additionally, emphasize key rules with capitalization and use bullet points for clarity when providing instructions.
| Strategy | Implementation | Expected Benefit |
|---|---|---|
| Phonetic Retrieval | Limit to ~10 phonetically similar names | Reduces Named Entity Error Rate (NER) |
| Reference Pronunciations | Map terms like “SQL” to “sequel” or “Kyiv” to “KEE-iv” | Improves clarity in voice synthesis |
| Alphanumeric Rules | Speak digits individually (e.g., 5-5-5) | Prevents misinterpretation of codes |
| Unclear Audio Logic | Clarify if confidence < 0.2 | Reduces hallucinations from noise |
With prompts well-structured, the next focus should be on managing context effectively.
Managing Context and Dialog State
For complex tasks, use an orchestrator agent to delegate responsibilities among specialized agents. Clear handoffs between agents improve reliability.
When transitioning between agents, provide a concise summary of the context, including the user’s name, main issue, and any collected identifiers. This reduces redundancy and user frustration. Use distinct roles in messages - developer for system rules, user for inputs, and assistant for responses - to maintain clear boundaries.
Place recurring instructions and context at the start of your prompt to leverage caching, which cuts down on both costs and latency. Additionally, configure agents to generate a summary of each interaction to identify patterns and maintain memory for long-term sessions.
“A reasoning model is like a senior co-worker - you can give them a goal and trust them to figure it out. A GPT model, on the other hand, is like a junior coworker - they need clear, detailed instructions to perform well”.
Strong context management lays the groundwork for precise error handling, especially when dealing with ambiguous inputs.
Error Handling and Recovery
When Automatic Speech Recognition (ASR) confidence is low, instruct the agent to acknowledge the issue (e.g., “I’m having trouble accessing that information”) to avoid generating hallucinated outputs.
For ambiguous terms, leverage acoustic features to resolve uncertainties. Techniques like Uncertainty-Aware Dynamic Fusion (UADF), which incorporates acoustic cues during decoding, can significantly improve word error rates.
Adopt a reasoning-first approach by generating interim thoughts before finalizing outputs. If entity detection fails, default to a context-free ASR hypothesis as a fallback.
“Adding a ‘reasoning’ field before the ‘score’ ensures consistent and accurate results. The idea is that the LLM can generate its reasoning first, then use it to produce a proper score”.
Lastly, use lower temperature settings (closer to 0) for audio-derived tasks. This encourages more focused and concise responses.
Maintaining Quality and Continuous Improvement
Deployment is just the beginning. Once systems are in use, real-world challenges emerge, requiring constant evaluation and adjustments. Production environments often reveal edge cases that weren’t apparent during development. This is why continuous monitoring and detailed observability are so important - they help bridge the gap between initial deployment and ongoing refinement.
Quality Metrics and Evaluation
Assessing quality involves looking at both signal and semantic performance. For audio generation, Fréchet Audio Distance (FAD) measures how closely synthetic audio aligns with real-world audio distributions. When it comes to evaluating text outputs derived from audio inputs, metrics like ROUGE-L are effective for summarization tasks, while BLEU is better suited for precision-heavy applications like translation.
Large Language Models (LLMs) are increasingly being used as scalable alternatives to manual reviews. For instance, models like GPT-4 demonstrate 80% agreement with expert human reviewers, which is comparable to the level of agreement found between different human annotators. In speech quality evaluations, tools like SpeechQualityLLM achieve impressive results, including a Mean Absolute Error (MAE) of 0.41 and a Pearson correlation of 0.86 when predicting human Mean Opinion Scores (MOS).
To ensure quality from the start, adopt an evaluation-driven development approach. This means designing task-specific evaluation methods early in the development cycle. Automating these evaluations, such as through pairwise comparisons, helps detect performance shifts over time.
| Metric Category | Key Metrics | Best Use Case |
|---|---|---|
| Audio Quality | MOS, FAD, MCD, SNR | Evaluating naturalness and clarity in TTS/TTA |
| Transcription | WER (Word Error Rate) | Measuring ASR accuracy and intelligibility |
| Text Similarity | ROUGE-L, BLEU, METEOR | Summarization, translation, and captioning |
| Cross-Modal | Recall@K, mAP, Modality Gap | Assessing retrieval and alignment across modes |
Observability and Logging
Distributed tracing is key to understanding how workflows operate. For example, tracking steps like audio encoding, modality adaptation, and LLM generation helps pinpoint where failures occur - whether in the audio processing layer or the language model.
“Observability aims to enable an understanding of a system’s behavior without altering or directly accessing it.” – Neptune.ai
Monitor metrics at the component level, such as latency in the audio encoder, embedding quality in the modality adapter, and token usage by the LLM. Set up multi-layered alerts for AI-specific issues like sudden accuracy drops or increases in hallucination rates. Organizations leveraging robust observability tools have reported development cycles up to five times faster.
Privacy compliance is another critical aspect. Automated data masking or anonymization of sensitive audio transcripts ensures privacy while still allowing debugging. Log key elements such as raw audio-derived text, prompt templates, and parsed JSON objects to identify where information may be lost during processing.
Continuous Improvement with Latitude
Metrics and logging are only part of the equation - continuous improvement is essential for long-term success. Observability not only helps resolve immediate issues but also guides future enhancements. Platforms like Latitude streamline this process by offering tools to monitor model behavior, gather feedback, and conduct production evaluations.
Latitude allows teams to link user feedback (like thumbs up or down) directly to specific execution traces, making it easier to identify patterns in problematic responses. The platform also fosters collaboration between domain experts and engineers, enabling structured feedback that reflects business needs. This feedback feeds into ongoing evaluation workflows, helping teams refine prompts and improve AI features over time.
Conclusion
Building reliable multimodal audio-text systems goes far beyond simply combining components. It requires modular architecture , precise data alignment, and constant monitoring to ensure optimal performance. Modular design simplifies debugging and allows for easier updates down the road, making it a key consideration for developers. The choice between early fusion, late fusion, or cross-attention techniques has a direct impact on both efficiency and accuracy, so developers must carefully weigh these trade-offs based on specific use cases.
The success of these systems in practical settings depends heavily on robustness and evaluation. For example, multimodal inputs significantly improve speech recognition in noisy environments by using synchronized audio and text cues to boost accuracy. A notable advancement came in March 2025, when researchers introduced SpeechVerse. This system combined frozen speech and text foundation models with only a few learnable parameters, outperforming traditional baselines in 81% of tested tasks (9 out of 11). Such results highlight a growing shift in how these systems are designed.
This shift is echoed by industry leaders:
“For the first time, we’re not designing interfaces that translate human intent into computer logic – we’re designing systems that understand it.” – Fuselab Creative
Operational success also depends on structured versioning and continuous monitoring. These processes are vital for maintaining real-time observability and creating effective feedback loops. However, challenges remain. A recent industry survey revealed that 91% of organizations with high-priority GenAI roadmaps feel unprepared to deploy the technology responsibly at scale. This highlights the value of platforms like Latitude , which demonstrate how integrated observability and structured feedback can drive ongoing improvement.
FAQs
What challenges arise when building multimodal systems that combine audio and text processing?
Building systems that can handle both audio and text processing comes with its fair share of hurdles.
First up, data quality. Audio files often bring along a host of issues - think background noise, distortion, or sudden interruptions. On the text side, you might encounter incomplete sentences or outright errors. These flaws can throw off a model’s performance unless they’re tackled head-on with proper cleaning and preprocessing.
Then there’s the challenge of aligning audio with text. Audio flows over time, while text is made up of sequential tokens. This difference makes syncing the two a tricky task. If they don’t align properly, the model might struggle to understand context or draw the right connections.
Finally, resource demands skyrocket when working with both modalities. These multimodal systems typically need more memory and computational power, which can push standard hardware beyond its limits. Overcoming this requires thoughtful planning, efficient preprocessing, and tools that encourage teamwork - platforms like Latitude can be a big help here.
What’s the difference between early fusion and late fusion for processing audio and text data?
Early fusion integrates audio and text data right from the start , feeding them together into a single model. This can involve combining raw waveforms, spectrograms, or acoustic embeddings with token embeddings. By doing so, the model processes both types of data simultaneously, which helps it pick up on nuanced cross-modal relationships - like how tone or prosody can alter the meaning of words. However, this approach often results in more complex models, which can be challenging to design and train.
Late fusion, on the other hand, keeps audio and text data separate for most of the processing pipeline. Audio is typically handled by a speech recognition system or an acoustic encoder, while text is processed by a language model. The outputs from these separate pipelines are merged later - usually by combining embeddings or adding acoustic features as contextual inputs. This method is easier to implement, as it allows each component to be optimized independently, but it might miss the finer interplay between audio and text.
To sum up, early fusion provides a way to deeply analyze the interaction between audio and text but comes with increased complexity. Late fusion, while simpler and more modular, may not capture subtle cross-modal relationships. The decision between the two often hinges on factors like latency requirements, how much data is available, and how deeply the system needs to understand the interaction between modalities.
How can I optimize latency and ensure reliability in multimodal audio-text systems?
To improve latency in multimodal audio-text pipelines, it’s crucial to streamline every step of the process. Start by using streaming endpoints to handle audio data as it’s captured, eliminating the need to wait for complete recordings. On the client side, compress or down-sample audio and transmit only essential features, like mel-spectrograms, to reduce data load. Caching frequently used prompts can cut down on repetitive processing. Additionally, simplify prompts by removing extra text and providing clear, concise instructions - this can significantly speed up large language model (LLM) computations. Opt for lightweight or highly optimized models to enhance performance, and consider batching requests or running tasks like transcription and inference simultaneously to save time. For even lower network delays, deploy critical services closer to users, such as on edge servers.
Reliability is equally important. Build redundancy into your system by using multiple transcription backends or fallback mechanisms to handle potential failures smoothly. Automated retries with exponential backoff can help prevent cascading problems. Keep a close eye on key metrics like latency, error rates, and system health, and set up alerts for unusual activity. Platforms like Latitude can simplify monitoring, maintain consistent versioning, and manage system orchestration efficiently. Lastly, prepare fallback options, like text-only responses, to ensure users still have a seamless experience, even if performance temporarily dips or partial outages occur.