

Fine-tuning large language models for specific industries can be challenging, especially with limited datasets and high computational demands. Here’s the key takeaway: Focus on high-quality data, efficient fine-tuning methods likeQLoRA, and feedback from experts to create effective domain-specific models.
Key Insights:
-
Challenges with Small Datasets : Overfitting and catastrophic forgetting are common issues when fine-tuning with limited examples.
-
Efficient Approaches :
-
Parameter-Efficient Fine-Tuning (e.g., LoRA, QLoRA) reduces memory requirements while maintaining strong performance.
-
Regularization techniques like Mixout and Layer-wise Learning Rate Decay (LLRD) help prevent overfitting.
-
-
Data Preparation Tips :
-
Prioritize quality over quantity; 50-100 well-curated examples can outperform thousands of low-quality ones.
-
Collaborate with subject matter experts to ensure accurate and relevant training data.
-
Use data cleaning, augmentation, and proper dataset splitting to maximize training effectiveness.
-
-
Fine-Tuning Strategies :
-
LoRA updates only select parameters, reducing costs and GPU memory usage.
-
Continued pre-training on domain-specific text builds foundational knowledge for specialized tasks.
-
-
Evaluation and Deployment :
-
Combine automated metrics with human evaluations for thorough performance checks.
-
Monitor production metrics like latency and token usage, and continuously improve using feedback loops.
-
By leveraging these strategies, even organizations with limited resources can fine-tune models for specialized tasks efficiently and effectively.
Challenges of Fine-Tuning with Limited Data
Small datasets create unique hurdles when fine-tuning models. One of the biggest issues is overfitting - when a model memorizes the training examples instead of identifying broader patterns. This can disrupt optimization, particularly when a model with millions of parameters is trained on only a few hundred examples. Additionally, full fine-tuning can lead to catastrophic forgetting , where the model loses its pre-trained general knowledge.
“Fine-tuning the entire model can risk overfitting to the training data, and consequently, the model may forget knowledge or become worse on tasks not specifically included in the fine-tuning training data”.
These challenges are especially pronounced in domains where datasets are inherently small.
Why Domain-Specific Datasets Are Often Small
Specialized industries often face significant barriers to building large datasets. For instance, in healthcare, HIPAAregulations limit access to patient data, while in legal and financial sectors, documents are often locked behind paywalls or classified as proprietary. Even when data is available, creating high-quality training examples is expensive and time-consuming. Tasks like labeling medical reports may require board-certified cardiologists, while reviewing legal documents demands experienced attorneys.
Scaling these datasets is no small feat. Research indicates that model performance improves with each doubling of high-quality training examples. However, when every example requires intensive expert review, increasing dataset size can quickly become a costly and time-intensive process.
Avoiding Overfitting While Maintaining Performance
To address these challenges, methods like PEFT (Parameter-Efficient Fine-Tuning) , including LoRA and QLoRA, allow updates to only select parameters. This approach helps preserve the model’s general knowledge while also reducing computational demands.
In addition, regularization techniques play a critical role in maintaining model stability. For example, Mixout randomly replaces weights with their pre-trained values during training, anchoring the model to its original knowledge. Similarly, Layer-wise Learning Rate Decay (LLRD) applies higher learning rates to the last layers and lower rates to earlier ones, ensuring that the model adapts to domain-specific details without losing its foundational language understanding. For datasets with fewer than 100 examples, including the original system instructions in every training example can help maintain instruction-following behavior.
Data Preparation for Small Datasets
When working with smaller datasets, every example carries significant weight. The difference between a model that excels and one that falters often hinges on how well the dataset is prepared. Research highlights this point: 1,000 carefully curated examples (like the LIMA dataset) can outperform 50,000 machine-generated ones (such as the Alpaca dataset). OpenAI also notes that even 50 to 100 thoughtfully crafted examples can lead to noticeable improvements. This underscores the importance of prioritizing quality over quantity when selecting and refining data.
How to Select High-Quality Domain Data
Involving subject matter experts (SMEs) from the start is non-negotiable. Take Casetext’s development of CoCounsel in 2023 as an example. Their team of lawyers and AI engineers spent six months - totaling 4,000 hours - curating 30,000 legal questions to ensure the AI adapted effectively to the legal domain. This level of expertise is essential for fine-tuning models to handle specialized tasks.
Another critical step is ensuring your dataset reflects a representative distribution of real-world use cases. For instance, if your model will process customer support tickets, your training data should include the full spectrum of user questions, not just the straightforward ones. Pay attention to class balance too - if 60% of your examples include refusals like “I cannot answer”, the model may overuse such responses during inference. Additionally, focus on failure modes where the current model underperforms. Training on these challenging examples can yield the most significant improvements.
“Quality is paramount: A general trend we’ve seen is that quality is more important than quantity - i.e., it’s better to have a small set of high-quality data, rather than a large set of low-quality data.” - Meta AI
When multiple annotators are involved, tracking inter-annotator agreement is crucial. If annotators agree on only 70% of examples, that inconsistency will limit your model’s accuracy. A human-in-the-loop (HITL) approach can help here. Using large language models (LLMs) to generate base responses, which humans then refine, reduces costs and time while maintaining high-quality labels. These strategies ensure not only consistency but also improved reliability in domain-specific tasks.
Data Cleaning, Augmentation, and Splitting
Once high-quality data is selected, refining it is the next step. Deduplication is essential - duplicate entries can degrade model performance during both pre-training and fine-tuning. Outliers should be removed, formatting standardized (e.g., eliminating unnecessary white spaces), and training examples aligned with the format expected during inference. The SQLCoder2 team demonstrated this by removing all white spaces from generated SQL, forcing the model to focus on learning logic instead of formatting quirks.
To expand your dataset without collecting new data, consider techniques like paraphrasing, back-translation, or Instruction Backtranslation. The latter involves asking an LLM, “What questions could this be an answer to?” to generate diverse training examples. If domain data is scarce, larger models like GPT-4o can create synthetic examples to fill in the gaps.
Lastly, split your data into training, validation, and test sets early in the process. The validation set helps monitor overfitting and fine-tune hyperparameters, while the test set provides an unbiased evaluation of the model’s final performance. This three-way split is especially critical when working with small datasets, where the risk of overfitting is much higher.
Fine-Tuning Techniques for Domain Adaptation
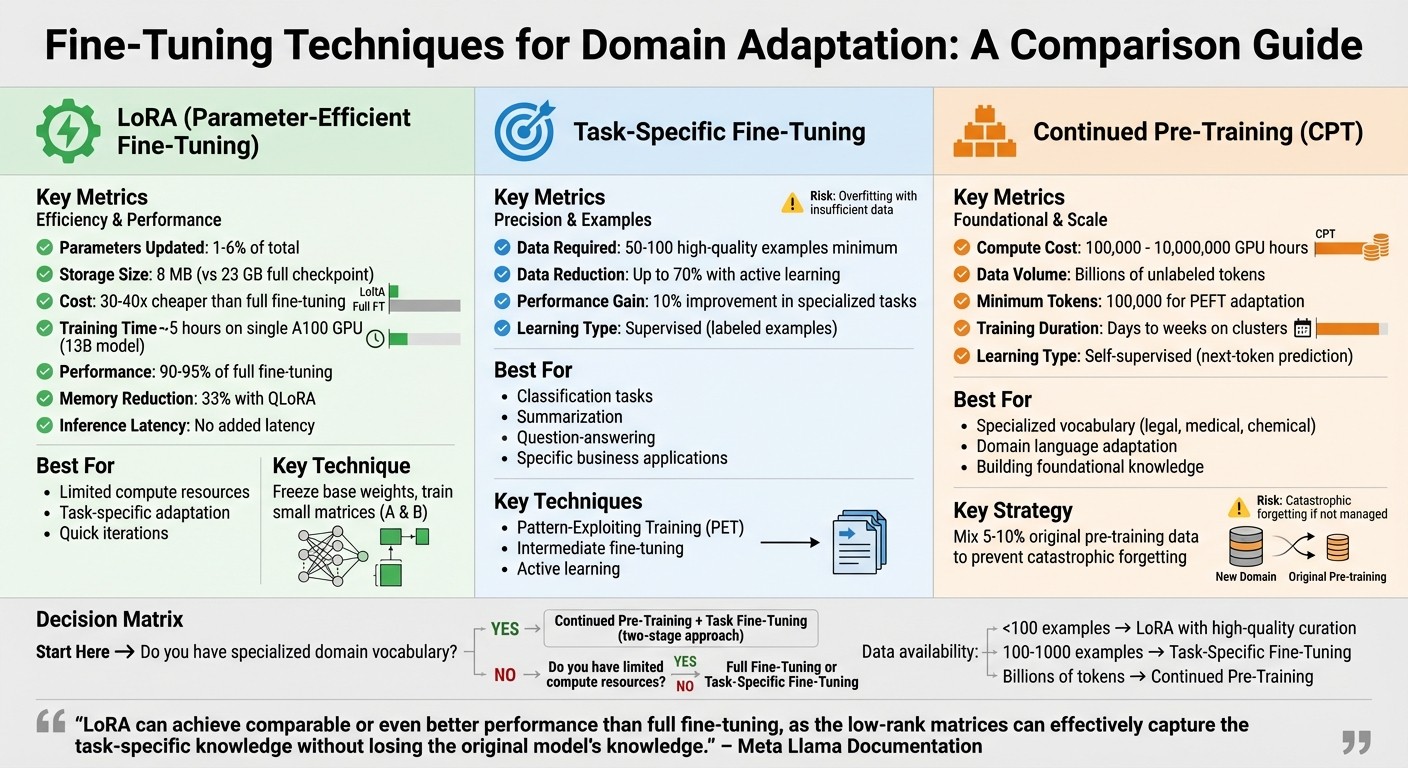
Comparison of Fine-Tuning Techniques: LoRA vs Full Fine-Tuning vs Continued Pre-Training
When adapting a model to a specific domain, there are three main approaches to consider: parameter-efficient methods like LoRA , task-specific fine-tuning, and continued pre-training on domain-specific text. Each has its strengths and trade-offs.
Parameter-Efficient Fine-Tuning with LoRA and Adapters
Traditional fine-tuning involves updating every parameter in a model, which can be both costly and risky. Low-Rank Adaptation (LoRA) offers a more efficient alternative by freezing the model’s original weights and introducing two trainable matrices ($A$ and $B$) to handle domain-specific updates. This method updates only 1% to 6% of the parameters, significantly reducing memory and compute needs. For example, while a full 7B LLaMA checkpoint requires 23 GB of storage, LoRA weights at rank 8 are as small as 8 MB.
Using LoRA is also far more economical. Fine-tuning a 7B model with LoRA is 30 to 40 times cheaper than full fine-tuning. For instance, a 13-billion-parameter model can be fine-tuned in about 5 hours on a single A100 GPU, compared to days or weeks for traditional methods. LoRA typically achieves 90% to 95% of the performance of full fine-tuning and allows its weights to merge seamlessly back into the base model, with no added inference latency.
“LoRA can achieve comparable or even better performance than full fine-tuning, as the low-rank matrices can effectively capture the task-specific knowledge without losing the original model’s knowledge.” - Meta Llama Documentation
For optimal results, apply LoRA to all linear layers - including Query, Key, Value, projections, and MLP layers - not just attention matrices. Set the scaling hyperparameter alpha to 2 × rank for better performance. For those seeking even greater memory efficiency, QLoRA (Quantized LoRA) reduces memory usage by about 33% , though it does increase training time by 39% due to quantization overhead.
This approach makes fine-tuning more accessible while maintaining strong performance.
Task-Specific Fine-Tuning
Task-specific fine-tuning hones a model’s capabilities for specific tasks like classification, summarization, or question-answering. This method requires less data than pre-training and focuses on teaching the model to excel at a particular job.
For low-resource classification tasks, Pattern-Exploiting Training (PET) reformulates problems into cloze-style tasks, making it especially effective in few-shot scenarios. Another useful technique is intermediate fine-tuning , where the model is first trained on a related, label-rich task before adapting to the target task. This method has been shown to improve sentiment analysis accuracy by 10% in specialized business applications.
When labeled data is limited, active learning can help. By selecting only the most informative examples, active learning reduces the required data size by up to 70%. In fact, just 50 to 100 high-quality examples can often outperform thousands of lower-quality ones.
If labeled data is scarce, another option is to enhance the model’s understanding of the domain through continued pre-training.
Continued Pre-Training on Domain Corpora
In domains with specialized language - such as legal terms, medical codes, or chemical formulas - the base model may lack the necessary vocabulary and concepts. Continued pre-training (CPT) addresses this by exposing the model to large-scale, unlabeled domain-specific text before task-specific fine-tuning. This self-supervised learning method helps the model predict the next token in domain-specific corpora, building a foundation of knowledge.
CPT can be resource-intensive, requiring anywhere from 100,000 to 10,000,000 GPU hours. However, combining CPT with parameter-efficient methods makes it more feasible. Even as few as 100,000 tokens can effectively adapt PEFT weights to a domain.
| Feature | Continued Pre-training (CPT) | Task-Specific Fine-Tuning |
|---|---|---|
| Learning Type | Self-supervised (next-token prediction) | Supervised (labeled examples) |
| Primary Goal | Domain/language adaptation | Task mastery/instruction following |
| Data Volume | Billions of unlabeled tokens | Thousands of labeled examples |
| Compute Cost | High (days/weeks on clusters) | Low to moderate (hours on single GPU) |
| Risk | Catastrophic forgetting | Overfitting |
For highly specialized domains, a two-stage process often works best. Start with continued pre-training on raw domain text to build vocabulary and understanding, then follow with task-specific fine-tuning on labeled data. To prevent catastrophic forgetting - where the model loses its general-purpose knowledge - mix 5% to 10% of the original pre-training data into the domain text during CPT.
“Fine-tuning, specifically parameter-efficient fine-tuning (PEFT), requires only a fraction of the computational resources needed for pre-training/continued pre-training.” - Meta AI
Once your model is ready, you can access the API to integrate it into your workflow. Next, we’ll explore hyperparameter adjustments and optimization strategies.
Hyperparameter Selection and Training Optimization
Fine-tuning hyperparameters is a critical step in ensuring your model learns effectively. This process builds on earlier steps, like data preparation and fine-tuning, to make training both efficient and impactful. The best approach? Start with reasonable defaults and tweak them based on how the model performs.
Key Hyperparameters to Adjust
The learning rate controls how much the model adjusts its weights during training. If your model seems stuck and isn’t improving, try increasing the learning rate multiplier to allow for larger updates. Research suggests that the ideal learning rate depends on your dataset size and training duration - longer training runs typically require smaller learning rates.
Epochs define how many times the model processes your entire dataset. For tasks like classification or entity extraction that demand accuracy, you might need to add an extra epoch or two. On the other hand, creative tasks often benefit from fewer epochs to encourage variety in outputs. Batch size is another key factor - it balances memory usage and gradient stability. Larger batch sizes lead to smoother updates but require more memory and can slow down training.
When using LoRA-based fine-tuning, start with a rank (r) of 8 or 16 if your dataset contains fewer than 100,000 samples. Scaling beyond these values usually provides minimal improvement. For smaller datasets (under 15,000 examples), including prompt tokens in the loss calculation can act as a helpful regularizer.
“A smaller amount of high-quality data is generally more effective than a larger amount of low-quality data.” - OpenAI
As a rule of thumb, begin with platform-recommended defaults tailored to your dataset size, and refine based on performance. Tools like Weights & Biases are invaluable for visualizing metrics across runs, making it easier to identify the best configurations.
Once you’ve nailed down the right hyperparameters, the next step is to explore strategies that can cut down training time and lower resource usage.
Reducing Training Time and Compute Costs
Beyond tuning hyperparameters, there are several techniques to make training faster and more cost-effective. Mixed precision training is one such method - it uses FP16 or BF16 precision for forward and backward passes while keeping optimizer states in 32-bit for stability. This reduces memory usage and speeds up training without sacrificing accuracy.
Another useful trick is gradient accumulation , which simulates larger batch sizes by updating weights less frequently. This is particularly helpful for training on consumer-grade hardware, as it conserves GPU memory. For example, using 4 or 8 accumulation steps can make a noticeable difference.
For models handling long-context data (2,048 tokens or more), Flash Attention 2 is a game-changer. By optimizing attention calculations from quadratic to linear complexity, it significantly reduces memory usage and runtime. In June 2024, Microsoft researchers showcased how enabling Flash Attention 2 for a LLaMA-2-70B model with 4,096-token contexts on 8xA100 GPUs dramatically cut down both memory consumption and training time.
Gradient checkpointing is another technique to consider. Instead of storing all activations during the forward pass, it recomputes them during the backward pass. While this increases runtime by 20% to 30%, it allows you to train larger models when memory is limited.
“Gradient Checkpointing allows to fine-tune much larger LLMs than what is possible with an additional 20%-30% increase in fine-tuning time.” - Arjun Singh, et al., Microsoft
For setups with extremely limited resources, CPU offloading (ZeRO-Offload) is a lifesaver. By moving optimizer states and computations to the CPU, it can reduce GPU memory usage by up to four times. Combining ZeRO-2 and LoRA often strikes the best balance between memory efficiency and training speed for most specialized tasks. Microsoft researchers demonstrated this by fine-tuning a LLaMA-2-70B model on a single node with 8xV100 GPUs (32 GB each), achieving peak GPU memory usage of just 15.54 GB using ZeRO-3 and LoRA.
Model Evaluation and Feedback Workflows
Once your model is trained, the next step is to evaluate its performance within its specific domain. Standard metrics like BLEU and ROUGE focus on surface-level text similarity but often fail to capture deeper semantic understanding. To get a fuller picture, combine automated scoring methods with human expert evaluations. This phase acts as a bridge between training and deployment, ensuring the model is reliable and ready for practical use.
Metrics for Domain-Specific Performance
The right metrics depend on the task at hand. For instance, in code generation, you might measure the pass rate on test cases - does the generated code run correctly? In legal analysis, metrics like precision and recall take priority. For medical applications, benchmarks such as MedQA are critical. A notable example is Google’s Med-PaLM 2, which achieved 86.5% accuracy on MedQA after fine-tuning for medical contexts.
A growing trend is the use of LLM-as-a-judge , where advanced models like GPT-4.1 evaluate outputs. This approach has shown over 80% agreement with human experts. Pairwise comparisons are particularly effective for ranking responses, though it’s important to monitor for biases, such as favoring the first response or preferring longer outputs.
Beyond accuracy, operational metrics like latency and token usage are vital for ensuring that fine-tuned models meet production performance standards. Continuous evaluation also helps catch potential issues early, reducing the risk of problems reaching end users. These metrics guide ongoing updates, keeping the model aligned with domain needs.
“Dataset quality directly impacts the model performance.” – Gideon Mann, Head of Bloomberg’s ML Product and Research team
Collecting Feedback with Latitude
Systematic feedback collection is essential for refining models, and platforms like Latitude make this process more structured and collaborative. Latitude connects engineers and domain experts through workflows that streamline evaluation and improvement.
Latitude supports three primary evaluation methods:
-
LLM-as-a-judge : Useful for subjective criteria like tone or creativity.
-
Programmatic Rules : Ideal for objective checks, such as JSON validation or regex matching.
-
Human-in-the-Loop : Critical for nuanced judgment and building high-quality datasets.
You can export production logs as CSV files, convert them to JSONL for fine-tuning, and re-import the updated model to compare it against the baseline. Real-time evaluations flag issues like performance regressions or toxic content as they occur. For regression testing, maintain a golden dataset with diverse inputs and expert-validated outputs. Latitude’s version control, similar to Git, allows teams to collaborate on prompt drafts and review evaluation results before deployment, ensuring new changes don’t disrupt existing functionality.
The optimization process works as a continuous cycle: create evaluations, refine prompts, fine-tune when necessary, and re-test against data that reflects real-world use cases. Platforms like Latitude help turn model improvement into an ongoing effort, ensuring the model stays aligned with evolving needs.
Deployment and Continuous Improvement
Once a model is fine-tuned using domain-specific data, the next steps - deployment and ongoing refinement - are key to ensuring it performs effectively over time.
Deploying Models to Production
Moving a model into production requires automated pipelines to handle data processing, evaluate outputs, and monitor performance. These pipelines typically include three validation layers: schema , content , and statistical checks.
Choosing the right deployment strategy depends on your risk tolerance and available resources:
-
Blue-Green Deployment : Ensures zero downtime by running two environments simultaneously, though it requires double the infrastructure.
-
Canary Deployment : Gradually rolls out updates, starting with a small percentage of traffic (1–5%) before full implementation.
-
Rolling Deployment : Updates are introduced incrementally, which can extend rollback times if issues arise.
Effective monitoring is non-negotiable. Keep an eye on metrics like latency and throughput , as well as logs, traces, and events. Set up alerts for critical thresholds - for example, trigger a rollback if the 99th percentile (P99) latency exceeds 110–120% of the baseline or if GPU memory usage climbs above 95%.
Once deployed, continuous evaluation ensures the model stays aligned with changing requirements.
Continuous Improvement Cycles
After deployment, it’s essential to create a feedback loop that evaluates the model’s performance in real-world scenarios and refines it accordingly. Incorporate edge cases from production logs into future training cycles to improve accuracy.
A/B testing is a powerful tool for comparing new versions of the model against the current production version. Track both explicit metrics (like user ratings) and implicit metrics (such as resolution rates and escalation frequency) to pinpoint areas for improvement. Automate retraining - monthly, for instance - to combat performance drift. Use version control systems like MLflow or Git to manage updates and enable quick rollbacks if necessary. You can also explore other viral LLM tools to streamline your development workflow.
Interestingly, some organizations have reported 30–40% cost reductions in the first quarter by closely monitoring token usage and optimizing accordingly.
Stay mindful of provider-specific policies. For example, Azure OpenAI may delete fine-tuned models after 15 days of inactivity. To avoid losing your work, implement “ping” pipelines to keep models active. Additionally, segment new production data early into training and test sets. This ensures that test data remains representative of real-world inputs, providing reliable validation for every new iteration.
Conclusion
Fine-tuning isn’t just about piling on more data - it’s about taking a thoughtful, step-by-step approach. Building domain-specific models goes beyond simply adding examples; it’s a process that emphasizes quality, iteration, and teamwork. Techniques like LoRA can deliver solid results with as few as 50 to 200 well-crafted examples.
Once a model is deployed, production logs often uncover edge cases that synthetic data can’t anticipate. Addressing these with additional high-quality examples - sometimes doubling the dataset - can lead to noticeable improvements in performance.
“We think of fine-tuning as one of many potential tools or approaches to address a client’s specific problem or request. Our process involves evaluating various options and selecting the one that offers the best balance of quality, speed, effort, and cost”.
Collaboration between domain experts and engineers is key to turning experimental ideas into robust, production-ready systems. Tools like Latitude simplify this journey by offering shared workspaces, built-in prompt version control, and features for collecting datasets straight from production logs. Once your model is fine-tuned, you can reintegrate it into Latitude to test it against existing datasets, ensuring an ongoing feedback loop that stays in tune with real-world challenges.
FAQs
What are the best ways to avoid overfitting when fine-tuning a model with a small dataset?
When working with limited data, avoiding overfitting during fine-tuning can be tricky. Here are some effective strategies to keep your model on track:
-
Try parameter-efficient fine-tuning: Techniques like LoRA can drastically reduce the number of trainable parameters, making the process more efficient and less prone to overfitting.
-
Pre-train briefly on in-domain text: A short pre-training phase using text from your specific domain can help the model adapt better to your needs.
-
Adjust training settings: Use a low learning rate and limit the number of training epochs. Incorporate early stopping by monitoring performance on a validation set to prevent over-training.
-
Diversify your dataset: Enrich your training data by creating paraphrased versions of your text, boosting variety without needing additional raw data.
These approaches can help you strike the right balance between performance and generalization, even with smaller datasets.
Why is LoRA a better option than full fine-tuning for domain-specific models?
LoRA, or Low-Rank Adaptation , offers a smarter way to fine-tune large language models by tweaking only a limited set of parameters within a low-rank adapter. This method slashes the number of trainable parameters, which means lower GPU memory requirements and less compute time - without compromising performance.
Because it narrows its focus to a smaller set of updates, LoRA shines in situations where data or computational resources are scarce. This makes it an excellent option for fine-tuning models for specific domains or specialized tasks.
How can I keep my domain-specific model accurate and reliable after deployment?
To keep your model performing well after deployment, it’s important to continuously track its accuracy and reliability. Use domain-specific benchmarks and incorporate human-in-the-loop evaluations to measure how well it’s holding up. If you notice a drop in performance, it’s likely time to retrain the model with fresh, high-quality data to bring it back on track.
Platforms like Latitude’s open-source tools can make this process easier. They allow engineers and domain experts to work together, ensuring the model stays aligned with real-world requirements and expectations.