

Deploying large language models (LLMs) comes down to two main options: serverless computing andKubernetes. Here’s the difference:
-
Serverless : Ideal for unpredictable, low-volume traffic. It automatically scales and charges based on usage, with no idle costs. However, it struggles with cold start delays and becomes expensive at high usage levels.
-
Kubernetes : Better for high-volume, steady workloads. It offers more control over resources like GPUs, ensuring consistent performance. But it requires significant setup and ongoing management.
Key Takeaways:
-
Serverless : Easy to set up, pay-per-use pricing, but limited for high throughput.
-
Kubernetes : Suited for large-scale, always-on deployments but demands DevOps expertise.
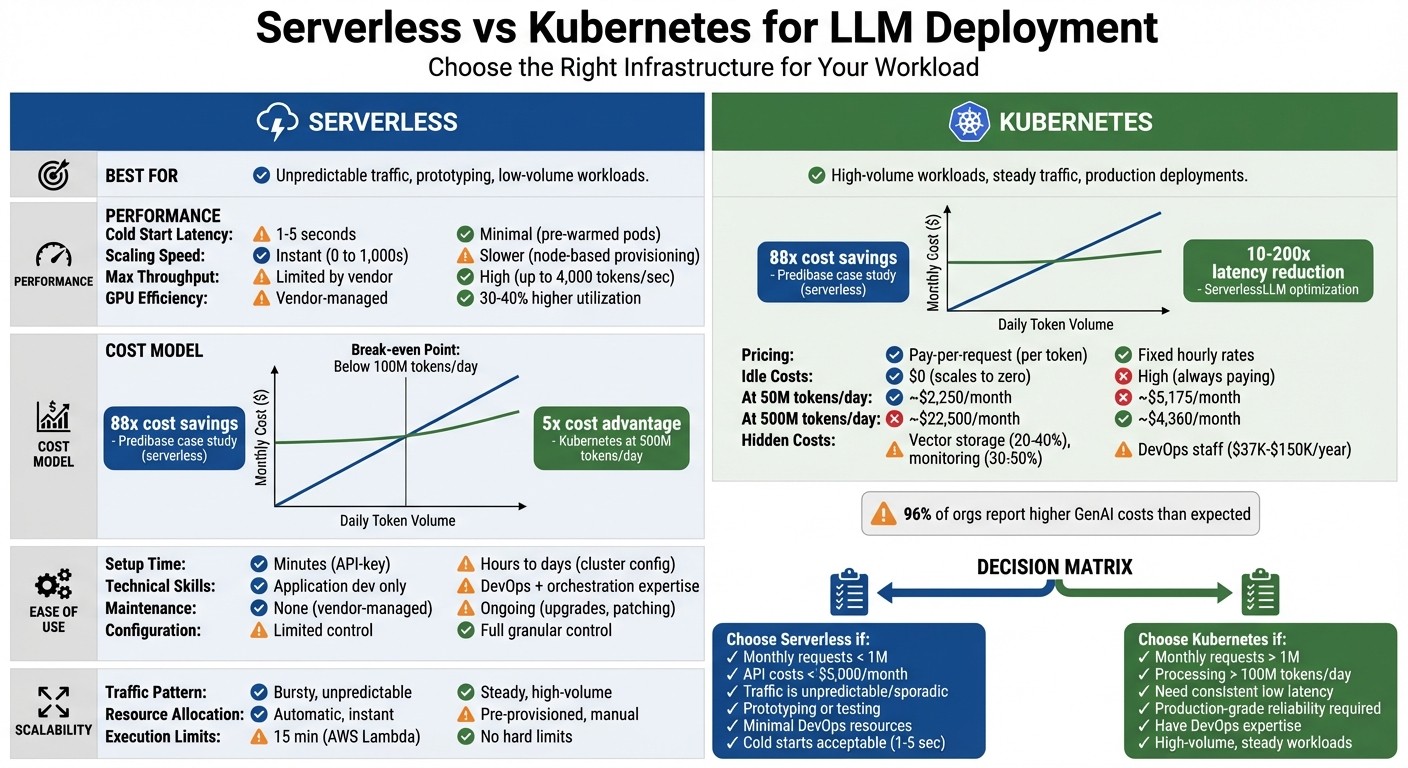
Quick Comparison :
| Feature | Serverless | Kubernetes |
|---|---|---|
| Best For | Unpredictable traffic | High-volume workloads |
| Cold Start Latency | 1–5 seconds | Minimal (pre-warmed) |
| Scaling Speed | Instant | Slower (node-based) |
| Cost Model | Pay-per-use | Fixed hourly rates |
| Setup Complexity | Minimal | High |
Serverless simplifies prototyping and sporadic tasks, while Kubernetes excels in large-scale, cost-efficient deployments. Your choice depends on workload patterns, budget, and technical expertise.
Serverless vs Kubernetes for LLM Deployment: Complete Comparison Guide
Serverless Computing for LLM Deployment
Serverless computing takes the hassle out of managing infrastructure. Instead of worrying about provisioning servers or allocating GPUs, you simply deploy your LLM inference code as functions. These functions are triggered by specific events, like an HTTP request through an API Gateway or a message in a queue. Meanwhile, the cloud provider handles all the heavy lifting - managing resources, spinning up servers, and allocating GPUs.
One standout feature of serverless computing is its scale-to-zero capability. When there’s no activity, the functions shut down entirely, meaning you don’t pay a dime during idle times. This makes it a smart choice for applications with unpredictable or intermittent traffic, like chatbots that only see occasional use or document processing systems active during business hours.
Modern tools have also made serverless deployments faster and more efficient. For example, ServerlessLLM speeds up model loading by 6–10x , while DeepServe can scale up to 64 instances in seconds thanks to pre-warmed pods and hardware tweaks.
The billing model is refreshingly simple: you’re charged based on execution and compute time, often measured in milliseconds. A case study from Predibase illustrates this cost efficiency. By switching from a dedicated A10G GPU (costing $19.36/day for 16 hours) to serverless endpoints, they cut costs to just $0.22/day for 10,000 requests - an 88x savings.
Let’s dive deeper into the features and challenges of using serverless computing for LLM deployments.
Key Features of Serverless for LLMs
Several features make serverless computing appealing for LLMs:
-
Pay-per-use pricing ensures you only pay for the compute time you actually use. This is ideal for workloads that fluctuate, like a customer service bot that’s busy during the day but idle overnight. Instead of paying for GPUs sitting idle, you’re billed for the execution time or token usage.
-
Automatic scaling matches resources to demand in real time. When traffic spikes, the system instantly provisions additional resources. When demand drops, it scales back down to zero. This flexibility works well for event-driven tasks like batch processing, periodic inference jobs, or handling sporadic API requests.
Recent advancements have also tackled performance issues. For instance, ServerlessLLM reduces latency by 10–200x across various LLM workloads compared to older serverless systems. Similarly, HydraServe minimizes cold start latency by 1.7x to 4.7x through smarter model distribution and overlapping initialization stages. These improvements make serverless solutions increasingly practical for applications where low latency is critical.
Challenges of Serverless for LLMs
Despite its benefits, serverless computing isn’t without challenges:
-
Cold start latency is a major hurdle. If a function hasn’t been used recently, the system needs to provision resources, initialize GPUs, and load large model checkpoints - sometimes several gigabytes. This can take over 40 seconds for the first token to appear, compared to just 30 milliseconds for warm instances. Even optimized networks can take more than 20 seconds to download checkpoints from remote storage.
-
Execution time limits can be restrictive. For example, AWS Lambda caps execution at 15 minutes. While this works for quick inference tasks, it can become an issue for complex workflows, extended conversations, or large batch jobs. Frameworks like LangGraph offer a workaround by checkpointing state to external databases, allowing long-running processes to resume across multiple function calls.
-
Resource constraints add complexity. Serverless platforms often limit memory and deployment package sizes. Libraries like PyTorch and Transformers can exceed these limits, requiring containerized deployments or Lambda Layers to manage dependencies. Additionally, the stateless nature of serverless functions means external systems (like Redis or Postgres) are needed to maintain conversational memory across sessions.
For high-volume workloads , the cost benefits may diminish. While serverless shines for sporadic traffic, sustained high-throughput scenarios can bring hidden costs. Memory usage, logging, and failed requests can inflate your bill by 15–30% beyond the advertised pricing. In fact, 96% of organizations deploying GenAI report higher-than-expected costs, with 71% acknowledging they struggle to control them.
Understanding these trade-offs is crucial as we explore Kubernetes, which offers a different approach to managing control and scalability.
Kubernetes for LLM Deployment
Kubernetes is a container orchestration platform that gives you precise control over deploying large language models (LLMs). It allows you to manage clusters of nodes - whether physical or virtual - and deploy your LLM inference services as pods. These pods are essentially groups of containers that share resources and networking, making them ideal for running complex workloads.
One of Kubernetes’ standout features is its ability to handle always-on deployments. This means model weights can remain in memory, enabling continuous connections without the delays of repeated cold starts. For example, deploying a Llama-3-70B model with 8-way parallelism might require 390GB of storage for raw and converted files. By using Persistent Volumes (PV), Kubernetes ensures these weights stay loaded in memory, significantly speeding up response times by avoiding the need to repeatedly pull large files from remote storage.
Kubernetes also excels in hardware-aware scheduling , allowing you to target specific GPU types like H100, A100, or L4. Tools like Node Feature Discovery label nodes with GPU capabilities, while NCCL facilitates direct GPU communication. This level of control is crucial for production environments where predictable performance and efficient resource use are non-negotiable, even if it introduces some complexity.
These capabilities make Kubernetes a leading choice for deploying LLMs in production, offering both flexibility and performance.
Key Features of Kubernetes for LLMs
Kubernetes brings several features to the table that are particularly useful for LLM deployments:
- Pod orchestration : Kubernetes treats groups of containers as a single unit. For example, the LeaderWorkerSet API coordinates multi-node workloads by managing a leader pod alongside multiple worker pods. This ensures synchronized operations, preventing issues like partial resource locking when some pods fail to initialize. This is especially important for massive models. Take Meta’s Llama 3.1 405B model as an example - running it at FP16 precision requires over 750GB of GPU memory for inference. In November 2024, Google Cloud engineers successfully deployed this model on Google Kubernetes Engine (GKE) using the LeaderWorkerSet (LWS) API. They split the workload across two A3 virtual machines, each equipped with 8 H100 GPUs, utilizing 8-way tensor parallelism and 2-way pipeline parallelism to meet the memory demands.
“The LeaderWorkerSet (LWS) is a deployment API specifically developed to address the workload requirements of multi-host inference, facilitating the sharding and execution of the model across multiple devices on multiple nodes.” - Cindy Xing and Puvi Pandian, Software Engineering Managers, Google
-
Flexible runtime support : Kubernetes supports various inference frameworks - vLLM, Triton Inference Server, TensorRT-LLM - running inside containers. NVIDIA, for instance, provided a reference setup for Llama-3-70B using Triton and TensorRT-LLM on Kubernetes, complete with a Helm chart to automate model engine creation on shared Persistent Volumes. Additionally, custom frameworks like
mpirunor Ray can be used to manage distributed processes across the cluster. -
Horizontal Pod Autoscaling (HPA) : HPA dynamically adjusts the number of replicas based on real-time metrics such as CPU usage, memory consumption, or custom metrics like inference latency. Unlike serverless scaling, Kubernetes lets you define minimum and maximum replica counts, giving you control over cost and availability.
-
Resource isolation : Kubernetes ensures resource prioritization through namespaces and Priority Classes. For example, you can reserve GPU nodes for production workloads by applying taints (e.g.,
nvidia.com/gpu=present:NoSchedule) or use topology-aware scheduling to reduce latency for distributed operations. This is particularly valuable for high-throughput environments.
These features make Kubernetes a robust option for deploying LLMs, offering flexibility and control that serverless models often lack.
Challenges of Kubernetes for LLMs
While Kubernetes offers powerful tools for LLM deployment, it comes with its own set of challenges:
-
Complex setup : Getting started with Kubernetes requires configuring clusters, installing GPU plugins, setting up networking, managing storage classes, and deploying monitoring tools. Unlike serverless platforms, where you simply upload code, or access an API, Kubernetes demands a deeper understanding of concepts like pods, StatefulSets, and services. For teams without strong DevOps expertise, this can significantly delay deployment timelines.
-
Ongoing cluster management : Running Kubernetes isn’t a one-time task. You’re responsible for maintaining node health, applying security patches, upgrading Kubernetes versions, and managing capacity. Even with managed services like GKE, you’ll need to monitor resources, troubleshoot pod failures, and fine-tune scheduling policies. With over 2,500 tools and platforms in the Kubernetes ecosystem, choosing the right LLM tools for your stack can be daunting.
-
Operational overhead : Kubernetes requires careful cost management. Unlike serverless models, where you pay per execution, Kubernetes charges for the underlying nodes regardless of their utilization. To minimize costs, you might need to implement gang scheduling to ensure all pods in a multi-node deployment start together, configure readiness probes to verify server initialization, or use Spot VMs to save money - though these come with the risk of preemption. Additionally, managing stateful LLM deployments often requires external systems for model versioning, observability, and experiment tracking.
For teams with the expertise and resources to manage these complexities, Kubernetes provides unparalleled control. However, for smaller teams or projects with fluctuating traffic, the operational demands might outweigh the benefits. Recognizing these challenges can help teams decide if Kubernetes aligns with their goals for scalability, cost efficiency, and ease of use.
Scalability: Serverless vs Kubernetes for LLMs
When it comes to scaling, serverless computing and Kubernetes offer distinct advantages depending on workload patterns. Serverless is tailored for handling sporadic or bursty traffic, scaling up resources instantly when demand spikes and scaling back down just as quickly when traffic diminishes. For instance, if your chatbot sees unpredictable usage throughout the day, serverless can allocate resources on-demand, ensuring smooth operation. Kubernetes, on the other hand, relies on pre-warmed pods or nodes. While this approach ensures readiness, provisioning new nodes during sudden traffic surges can take several minutes.
One drawback of serverless is cold start latency , particularly when loading large LLM checkpoints. This delay can range from 1 to 5 seconds. However, solutions like ServerlessLLM have shown that multi-tier checkpoint loading can reduce startup times by 6–8x. Similarly, HydraServe achieves latency reductions of 1.7–4.7x by proactively distributing models. Kubernetes addresses this issue by keeping containers “warm”, ensuring they’re ready to handle requests immediately.
For workloads that are steady and high-volume, Kubernetes excels. Persistent pods preloaded with model weights can deliver throughput that is 14–24 times higher than typical setups. This performance boost, however, comes with a cost - continuous GPU resource allocation, even during idle periods. For those seeking efficiency and scalability, these differences are crucial when deciding between the two platforms.
“Serverless is great for the API layer but terrible for running large models yourself. Use it to route requests… Run the actual AI elsewhere.” - Field Guide to AI
Innovative approaches are also pushing the boundaries of what serverless can achieve for LLM scalability. For example, the λScale system demonstrated in 2025 that high-speed RDMA networks could optimize model multicast, achieving a 5x improvement in tail-latency while reducing costs by 31.3% compared to earlier solutions. Similarly, DeepServe leverages NPU-fork technology to scale to 64 instances in seconds, showcasing serverless’s ability to adapt rapidly to demand.
These scalability features highlight the operational trade-offs between serverless and Kubernetes, making it essential to align the platform choice with specific workload requirements.
Scalability Comparison Table
| Feature | Serverless Computing | Kubernetes (K8s) |
|---|---|---|
| Scale Speed | Instant (0 to 1,000s of requests) | Slower (depends on node provisioning) |
| Cold Start Latency | High (1–5 seconds for LLMs) | Low (pre-warmed/persistent pods) |
| Max Throughput | Limited by vendor concurrency | High (optimized with GPU scheduling) |
| Traffic Handling | Best for bursty/unpredictable loads | Best for steady, high-volume loads |
| GPU Efficiency | Limited; vendor-managed | High; configurable and dedicated |
Cost Efficiency: Serverless vs Kubernetes for LLMs
When it comes to deploying large language models (LLMs), cost efficiency is a critical consideration alongside scalability and operational ease. Serverless and Kubernetes follow fundamentally different pricing structures, which can significantly impact the overall cost depending on the usage pattern.
Serverless operates on a pay-per-request model, meaning you’re only charged for the tokens or requests processed, with no idle costs. In contrast, Kubernetes relies on fixed hourly rates for GPU instances, regardless of whether those resources are fully utilized. For example, an AWS g5.xlarge instance equipped with an A10G GPU costs about $1.01 per hour, translating to roughly $730 per month, even if it’s underutilized.
At a moderate usage of 50 million tokens per day, serverless deployment costs around $2,250 per month, while running a self-hosted Llama 70B model (one of many open source LLM projects available for deployment) on four A10G GPUs through Kubernetes costs approximately $5,175 monthly. However, as usage scales, the economics shift dramatically. At 500 million tokens per day, serverless costs skyrocket to $22,500 monthly, while Kubernetes costs drop to $4,360 - a 5x cost advantage for Kubernetes in high-volume scenarios. The tipping point where Kubernetes becomes more economical typically lies between 100 million and 200 million tokens daily.
Hidden Costs and Overhead
Serverless deployments come with additional costs beyond token pricing. Token fees account for only about 5% of total serverless expenses, with the bulk of spending distributed across vector storage (20–40%), query infrastructure (30–50%), and monitoring. Kubernetes, on the other hand, requires dedicated staffing for maintenance and management, ranging from 0.25 to 1.0 full-time equivalent (FTE) employees, which translates to annual labor costs of $37,000 to $150,000. Enterprises also often require supplementary tools like Azure API Management Gateway, which adds $2,795 monthly to the bill.
“Token pricing is noise. Token costs represent approximately 5% of total serverless LLM spend. The remaining 95% hides in vector storage, query infrastructure, and monitoring.”
- Likhon, Cloud Architect
Optimizing Costs
Both platforms offer opportunities for cost reduction through strategic optimizations. Some effective strategies include:
-
Context Caching : Can cut costs by up to 90% in platforms like Google Vertex AI.
-
Switching to Arm-based Graviton2 Instances : Offers a 20% savings.
-
Using Spot VMs : Delivers discounts ranging from 53% to 90%.
-
Batch Processing for Non-Real-Time Workloads : Reduces costs by 30–50% through managed APIs.
These approaches can significantly trim expenses, making either option more budget-friendly depending on the specific deployment needs.
Cost Efficiency Comparison Table
| Feature | Serverless (Pay-per-Request) | Kubernetes (Always-on) |
|---|---|---|
| Pricing Model | Variable (per token/request) | Fixed (per instance/hour) |
| Idle Costs | $0 (scales to zero) | High (pay for capacity always) |
| Cost at 50M tokens/day | ~$2,250/month | ~$5,175/month (4x A10G) |
| Cost at 500M tokens/day | ~$22,500/month | ~$4,360/month |
| Personnel Overhead | Minimal | $37,000–$150,000/year |
| Best Traffic Pattern | Spiky, unpredictable, low volume | Consistent, high volume (>100M tokens/day) |
| Hidden Costs | Vector storage, monitoring (95% of spend) | DevOps, data egress, cluster management |
Understanding these cost dynamics and optimization strategies can help organizations choose the most suitable infrastructure for their LLM deployments based on their workload patterns and budget priorities.
Ease of Use: Serverless vs Kubernetes for LLMs
When deciding how to deploy large language models (LLMs), ease of use is just as important as scalability and cost.
Serverless platforms simplify the process, allowing developers to get LLM features up and running in minutes. With just an API key, you can focus on writing application code and mastering prompt engineering without worrying about infrastructure, networking, or scaling configurations. It’s a straightforward, plug-and-play approach.
On the other hand, Kubernetes takes a more hands-on route. It involves provisioning clusters, configuring operators like KubeRay, and managing various components manually. This setup requires specialized DevOps expertise and ongoing maintenance.
The operational demands also differ significantly. Serverless deployments are largely managed by the provider, leaving minimal responsibility for the user. Kubernetes, however, requires continuous oversight for updates, resource management, and system monitoring. For teams just starting out with LLMs, serverless APIs offer a quick way to test ideas and validate use cases without diving into infrastructure complexities. But once API costs climb above $5,000 a month or traffic exceeds 10 million requests, Kubernetes often becomes more cost-efficient - despite its operational challenges.
Here’s a quick breakdown of the ease-of-use factors:
Ease of Use Comparison Table
| Feature | Serverless | Kubernetes |
|---|---|---|
| Setup Time | Minutes (API-key driven) | Hours to days (cluster configuration) |
| Technical Skills Required | Application development only | DevOps, orchestration, networking expertise |
| Operational Effort | Minimal (vendor-managed) | High (self-managed infrastructure) |
| Configuration Complexity | Abstracted/limited control | Granular/full control required |
| Maintenance | None (provider-handled) | Ongoing (upgrades, patching, security) |
| Cold Start Latency | 1–5 seconds when scaling from zero | Minimal (pre-warmed pods) |
| GPU Utilization | Limited/vendor-dependent | 30–40% higher with unified runtimes |
Each approach has its strengths, but the choice ultimately depends on your team’s expertise, workload demands, and budget.
When to Choose Serverless vs Kubernetes for LLM Deployment
Serverless is a great option when you’re prototyping new LLM features or dealing with unpredictable, bursty traffic. It lets you move quickly without worrying about managing infrastructure, and the pay-per-use model helps keep costs down, especially when traffic is light.
However, there’s a tipping point where Kubernetes becomes the better choice. If your API costs climb beyond $5,000 per month or you’re processing over 1 million requests, Kubernetes can slash expenses by 10× to 100× compared to serverless setups. Kubernetes also shines in scenarios requiring consistent, low-latency responses, like customer-facing chat or voice assistants, where serverless cold starts (1–5 seconds) just won’t cut it.
“Serverless accelerates the sprint, containers win the marathon.”
– James Fahey
Your team’s expertise in DevOps plays a big role here. Serverless minimizes the need for operational management, making it simpler to use. On the other hand, Kubernetes requires more technical know-how, including managing GPU scheduling, cluster networking, and observability. Many teams go for a hybrid model - using serverless for edge cases and experimental features while relying on Kubernetes for high-volume, latency-sensitive workloads. This approach offers a balance between fast iteration and cost-effective scaling.
How Latitude Supports LLM Infrastructure Decisions
Making the right choice between serverless and Kubernetes requires robust monitoring and observability. No matter which path you take, ensuring production reliability depends on having clear insights into your LLM’s performance. Latitude offers observability and quality management tools that work across both deployment models, helping you track model behavior, collect structured feedback from domain experts, and run evaluations to catch potential issues before they reach users.
With Latitude, you can monitor key metrics like latency, token usage, and overall quality. These insights help you decide when to scale, switch deployment strategies, or migrate from serverless to self-hosted setups. As your traffic grows and infrastructure costs take up a bigger slice of your budget, having this level of visibility becomes essential.
Conclusion
Deciding between serverless and Kubernetes for deploying large language models (LLMs) isn’t about finding a clear-cut winner - it’s about matching the infrastructure to your specific needs. Serverless shines when you need quick prototyping, the ability to handle unpredictable traffic, and minimal operational complexity. This makes it a solid choice for testing ideas or dealing with sporadic workloads. On the other hand, Kubernetes offers more control, making it ideal for high-volume production scenarios where low latency, consistent performance, and cost management are priorities.
For workloads under 100,000 monthly requests, serverless is a practical option. However, once API costs exceed $5,000 or requests surpass 1 million per month, Kubernetes becomes a more economical choice. It can scale to handle up to 4,000 tokens per second while improving GPU utilization by 30%–40%.
Many organizations find value in a hybrid approach: using serverless for experimental or edge-case scenarios and Kubernetes for core, high-throughput tasks. As Alex Buzunov, a GenAI Specialist, points out:
“Most LLM cost and latency problems are architectural, not prompt-related”.
This highlights the importance of focusing on smart routing, caching, and observability over micromanaging individual prompts. A balanced architecture that evolves with your needs is key to managing both performance and costs effectively.
Regardless of the chosen infrastructure, observability is critical. Metrics like latency, token usage, and costs provide the clarity needed for scaling and migration decisions. Tools like Latitude’s observability platform can help monitor these metrics across serverless and Kubernetes setups, ensuring performance stays optimized.
Ultimately, the best approach depends on your immediate goals and future growth plans. Start with the solution that lets you move quickly, and adjust your architecture as your traffic and requirements evolve.
FAQs
What’s the fastest way to estimate the serverless-to-Kubernetes break-even point?
To estimate when the shift from serverless to Kubernetes becomes cost-effective, start by analyzing your workload patterns, utilization rates, and projected expenses over time. For workloads with consistent demand and utilization levels above 60–70%, Kubernetes can deliver 30–50% savings over a three-year period. On the other hand, serverless is typically more efficient for handling unpredictable or fluctuating traffic.
To make an informed decision, model your usage patterns, compare both the upfront and ongoing costs of each approach, and leverage tools like Latitude for real-time monitoring. These steps will help pinpoint the point where serverless costs outpace those of Kubernetes.
How can I reduce cold-start latency for serverless LLM inference?
To reduce cold-start latency in serverless LLM inference, it’s crucial to streamline how models are loaded and deployed. For instance, using fast checkpoint loading with multi-tier formats and efficient data transfer can shave off significant startup time. Additionally, proactive model placement and live migration - which rely on local checkpoint storage - help eliminate the need for remote downloads, further speeding up the process. These approaches work together to create quicker and more responsive serverless LLM setups.
What’s a practical hybrid setup using both serverless and Kubernetes?
A practical way to deploy large language models (LLMs) is by using a hybrid setup that combines Kubernetes and serverless architectures. Here’s how it works:
-
Kubernetes is ideal for hosting core or high-demand models. It provides strong resource management and ensures consistent performance, making it perfect for large-scale inference and environments that need to stay active continuously.
-
Serverless architectures step in for handling sudden traffic spikes or unpredictable workloads. These are great for auxiliary tasks, as they scale automatically and efficiently manage bursts of demand.
Communication between these components is managed through APIs or message queues , creating a seamless operation. This setup strikes a balance between scalability, cost management, and operational control, making it a flexible approach for deploying LLMs.