

Human feedback is critical for improving large language models (LLMs). While automated systems are fast, they often miss nuanced issues like hallucinations or biases. Effective prompt engineering for developers can mitigate these risks during the initial design phase. Human judgment ensures models align better with user expectations, leading to safer and more accurate outputs.
Key points:
-
Human vs. Machine: Smaller, human-tuned models often outperform larger ones. For example, OpenAI’s 1.3B InstructGPT was preferred over the 175B GPT-3 in evaluations.
-
Feedback Methods: Preference rankings, rating scales, and iterative reviews are common. Each has strengths and weaknesses, with iterative reviews offering deeper insights.
-
Blended Approaches: Combining human feedback with automated tools improves efficiency. Techniques like RLHF (Reinforcement Learning from Human Feedback) fine-tune models based on user preferences.
-
Real-World Impact: Case studies in software, healthcare, and customer support show measurable improvements in model accuracy, safety, and user trust.
Human feedback isn’t just helpful - it’s necessary for refining LLMs, ensuring they meet practical needs and maintain reliability over time.
How Human Feedback Works in LLM Validation
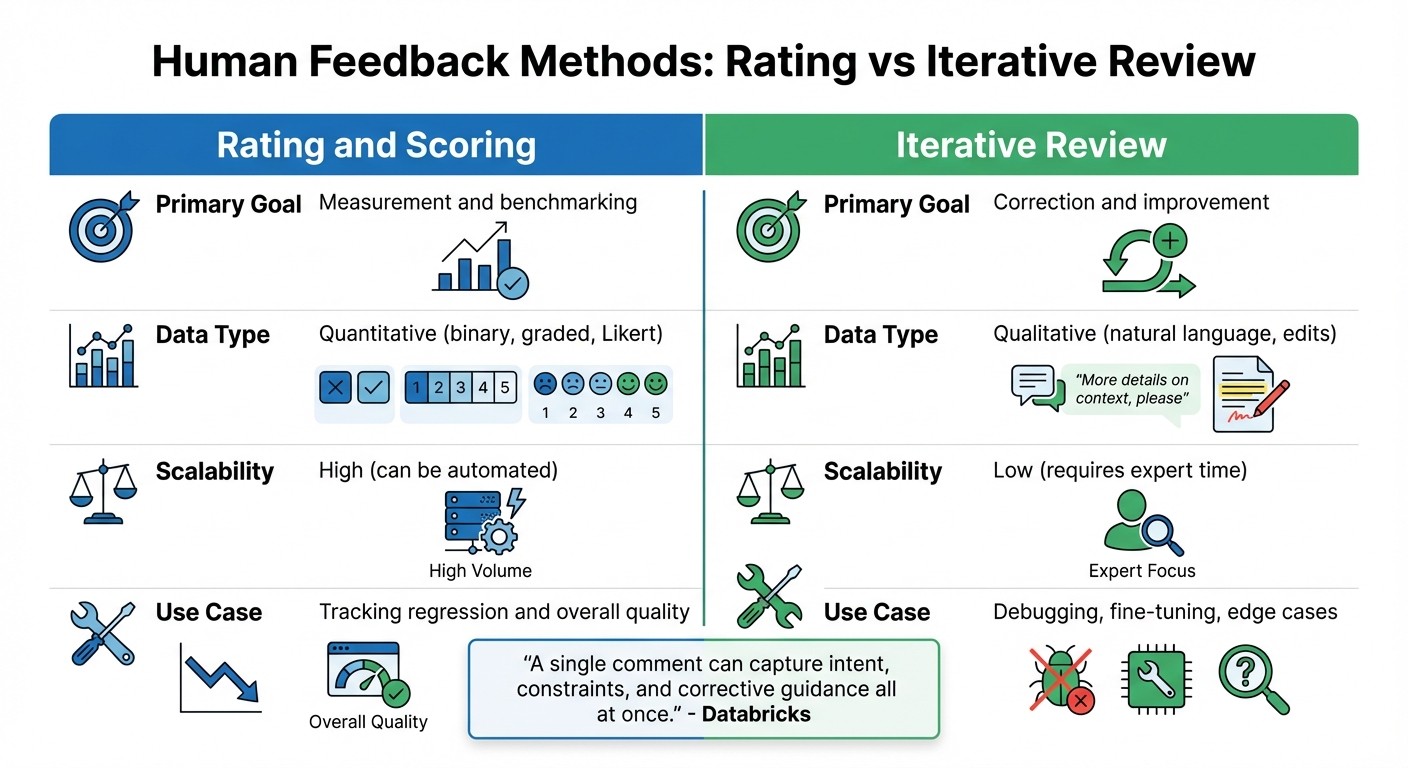
Human Feedback Methods in LLM Validation: Rating vs Iterative Review Comparison
Human feedback uses various methods to capture nuanced judgments, helping assess overall quality while identifying specific errors.
Preference-Based Feedback
This method involves ranking multiple outputs instead of scoring a single response. Evaluators compare two or more options to determine their order of preference. It’s especially useful for training Reward Models (RM), which act as stand-ins for human judgment during Reinforcement Learning from Human Feedback (RLHF).
The format of the output significantly impacts evaluation. Studies reveal a 60% disagreement between rating scales and pairwise rankings, with rating scales favoring detailed responses and pairwise comparisons focusing more on accuracy.
“Preferences inferred from ratings and rankings significantly disagree 60% for both human and AI annotators.” - Hritik Bansal, John Dang, and Aditya Grover
In October 2024, researchers introduced HyPER, a hybrid model that routed 10,000 complex cases to humans while assigning simpler ones to AI. This approach improved Reward Model performance by 7–13%.
Fine-grained preference feedback takes this a step further. Annotators can highlight specific “liked” or “disliked” spans within a response, rather than judging the entire output. This method is particularly effective for model tuning, as it pinpoints exactly what needs adjustment.
However, preference scores can sometimes mislead. A model’s confident tone might falsely imply factual accuracy, making qualitative comparisons a necessary complement to quantitative assessments.
Rating and Scoring Methods
Structured rating scales, like Likert scales (1–5), thumbs up/down, or binary pass/fail judgments, provide quick, scalable feedback. These methods are ideal for tracking performance trends over time, as they are faster and easier to implement than detailed reviews.
That said, simplicity has its downsides. Standard validation approaches often overlook “rating indeterminacy”, where multiple ratings could be equally valid. Ignoring this can lead to judge systems that perform up to 31% worse than those using multi-label “response set” ratings. Forced-choice ratings can also struggle to account for outputs that fall into gray areas.
“Differences in how humans and LLMs resolve rating indeterminacy when responding to forced-choice rating instructions can heavily bias LLM-as-a-judge validation.” - Luke Guerdan
While scoring methods provide quick benchmarks, they often lack the nuance needed to diagnose model failures. In critical fields like finance or law, scoring typically acts as a first step, with human review serving as the final decision point. Scoring is fast, but iterative reviews, as discussed below, offer deeper corrective insights.
Iterative Review and Refinement
This process emphasizes active improvement over simple measurement. Humans edit outputs, provide detailed feedback, or create corrected versions that serve as “gold standard” training data. Though more labor-intensive and costly than scoring, this method captures rich information about intent and corrective guidance.
“A single comment can capture intent, constraints, and corrective guidance all at once.” - Databricks
Iterative reviews don’t just identify errors - they guide improvement. By offering targeted feedback, they help refine model behavior.
| Feature | Rating and Scoring | Iterative Review |
|---|---|---|
| Primary Goal | Measurement and benchmarking | Correction and improvement |
| Data Type | Quantitative (binary, graded, Likert) | Qualitative (natural language, edits) |
| Scalability | High (can be automated) | Low (requires expert time) |
| Use Case | Tracking regression and overall quality | Debugging, fine-tuning, edge cases |
Natural language feedback stands out for its depth. A single comment can convey what might otherwise require multiple examples. This makes iterative review especially useful for addressing edge cases and debugging failure modes that scoring methods might simply flag without additional explanation.
Combining Human Feedback with Automated Validation
Blending human insight with automated processes adds strength to LLM validation systems. On their own, neither human judgment nor automated metrics can cover all bases. People can grasp nuance and intent but aren’t scalable, while automated systems handle volume but often miss subtle quality issues. The most effective workflows use both, playing to each method’s strengths.
Using Human Judgment with Quantitative Metrics
Automated benchmarks like AlpacaEval-2, HumanEval, and TruthfulQA offer quick, high-level performance checks. However, they fall short of explaining why a model fails or how to address the problem. This is where human evaluators step in, pinpointing issues that raw numbers can’t reveal.
Interestingly, research shows that even when the same annotators rate and rank outputs, their judgments can differ by as much as 60%. This highlights the limitations of automated benchmarks in capturing the finer details. For instance, human evaluators often favor detailed responses when rating outputs but lean toward accuracy when comparing them side-by-side.
“Human feedback is not gold standard… the assertiveness of an output skews the perceived rate of factuality errors, indicating that human annotations are not a fully reliable evaluation metric.” - Tom Hosking, University College London
This bias means that confident-sounding outputs can sometimes hide factual mistakes. To address this, validation workflows should incorporate multiple reward models , each focusing on a specific quality metric like factuality, relevance, or toxicity. A great example of this is the work of Vishvak Murahari and his team in May 2024. Using the QualEval framework on the Llama 2 model, they combined quantitative metrics with automated qualitative insights, improving performance on DialogSum by 15%.
For technical tasks such as coding or mathematical reasoning, external tool grounding - like running code or conducting web searches - helps verify outputs. This reduces both human bias and the risk of model errors like hallucination. These techniques are paving the way for reinforcement learning methods that incorporate human preferences directly into model training.
Implementing Reinforcement Learning from Human Feedback (RLHF)
RLHF turns human preferences into a dynamic signal that fine-tunes model behavior. It starts by collecting human rankings of model outputs. These rankings train a reward model , which predicts the types of outputs humans prefer.
In March 2022, OpenAI researchers, including Long Ouyang and Jan Leike, demonstrated RLHF’s potential by aligning GPT-3 with human preferences. Using human rankings, they trained a reward model to fine-tune a smaller 1.3B InstructGPT model. Despite having far fewer parameters than the 175B GPT-3, the smaller model outperformed its predecessor in human preference tests and produced less toxic content.
Traditional RLHF assigns a single score to each output, which can be limiting for longer text. Fine-grained RLHF addresses this by breaking feedback into smaller parts, such as sentences. For example, in June 2023, researchers from the University of Washington and the Allen Institute for AI applied fine-grained RLHF to detoxify GPT-2 Large. By using sentence-level toxicity scores from the Perspective API, they reduced toxicity scores to 0.081, compared to 0.130 with traditional RLHF.
“Fine-grained reward locates where the toxic content is, which is a stronger training signal compared with a scalar reward for the whole text.” - Zeqiu Wu, University of Washington
This approach helps models learn exactly where they went wrong. Instead of labeling an entire response as flawed, the feedback pinpoints specific sentences that are irrelevant, incorrect, or incomplete. For even more control, organizations can adjust the weights of different reward models during training to balance competing priorities like helpfulness and safety.
To reduce reliance on human input, some teams are exploring Reinforcement Learning from AI Feedback (RLAIF). Here, AI systems generate preference labels instead of humans, achieving results similar to human feedback but at a fraction of the cost. This strategy supports continuous validation in dynamic environments.
Continuous Validation and Improvement Loops
Building on RLHF, continuous validation loops keep models aligned over time. Static validation only identifies problems at a single point, while continuous validation loops adapt to evolving user needs and language patterns. A particularly effective method is online iterative RLHF , where both the reward model and policy are updated in cycles.
Unlike one-time training on a fixed dataset, online RLHF refreshes models regularly - weekly or monthly - with new feedback. This prevents models from drifting away from user expectations and often outperforms offline learning by integrating ongoing insights.
This system creates a feedback loop: the model generates outputs, which are then evaluated by humans or automated systems. The feedback updates the reward model, which in turn refines the policy. Over time, this cycle improves alignment. To avoid drastic changes during updates, a KL divergence penalty ensures the model stays fluent by limiting deviations from its original state.
For organizations with limited resources, proxy preference models - trained on open-source datasets - can fill in the gaps between manual review cycles. This allows for frequent updates without the high cost of constant human involvement. The key is maintaining a regular update schedule - whether weekly, biweekly, or monthly - rather than treating validation as a one-time task.
Case Studies: Human Feedback in LLM Validation
Building on earlier validation techniques, these case studies highlight how human feedback is applied across various fields, including software development, information retrieval, and healthcare. Each example showcases how human judgment can enhance large language model (LLM) performance in practical settings.
Test Summary Validation in Software Development
Software teams are increasingly using structured human feedback to refine AI systems. At NurtureBoss, an AI startup focused on leasing assistants, founder Jacob manually reviewed hundreds of traces in December 2025 using a custom data viewer. Guided by expert Hamel Husain, the team categorized failures through axial coding. They discovered that three recurring issues - date handling, handoff failures, and conversation flow - were responsible for most LLM errors. This insight led to the development of a targeted LLM-as-judge system for ongoing validation.
“The core challenge is to systematically measure the quality of our AI systems and diagnose their failures.” - Hamel Husain, Machine Learning Engineer
This approach relies on golden datasets , where domain experts provide clear PASS/FAIL judgments instead of subjective ratings. Binary decisions create a clear threshold for quality, enabling engineers to address specific flaws effectively.
Interactive workflows also show measurable improvements. For example, TiCoder’s human-in-the-loop system increased code pass@1 accuracy by 45.97% across four advanced LLMs. Similarly, CodeMonkeys resolved 57.4% of issues on the SWE-bench Verified dataset for approximately $2,300.
RAG (Retrieval-Augmented Generation) Output Assessment
Human feedback is equally critical for refining retrieval-augmented generation (RAG) systems. It helps diagnose failures by identifying whether issues stem from irrelevant document retrieval, hallucinated responses, or unclear sources. Reviewing just 10–20 examples weekly can uncover patterns that lead to significant quality improvements.
“If you deploy a RAG system without a solid plan for evaluation and improvement, you’re not building a smart assistant; you’re potentially building a confident liar.” - Label Studio
The vRAG-Eval system demonstrated that GPT-4 assessments aligned with human expert judgments 83% of the time for accept-or-reject decisions on RAG outputs. More advanced tools like ARES use prediction-powered inference to reduce errors in automated evaluations, achieving accurate results across eight knowledge-intensive tasks with minimal human annotations. Human reviewers validate metrics like faithfulness and relevance, ensuring they meet user needs rather than just hitting technical targets.
The most effective workflows route critical samples - those flagged for low faithfulness or relevance - directly to human reviewers. Tools like GenAudit assist by highlighting evidence from reference documents, enabling reviewers to systematically fact-check LLM outputs.
Clinical Applications of LLM Validation
In healthcare, where accuracy is paramount, human validation is crucial. Clinical experts provide “golden labels” that automated systems alone cannot replicate. At Stanford Health Care, researchers led by François Grolleau, MD, PhD, validated the MedFactEval framework between January 2023 and June 2024. Using 30 adult inpatients, a seven-physician panel established ground truth by voting on key facts in discharge summaries, such as new diagnoses or follow-up actions. The automated LLM Jury achieved 81% agreement with expert assessments (Cohen’s kappa), matching human performance.
“The gold standard for identifying such errors - expert human review - is prohibitively slow and expensive for the routine, iterative quality assurance these systems require.” - François Grolleau, MD, PhD, Stanford University
The MedVAL framework, developed in September 2025 by Asad Aali and Akshay S. Chaudhari, analyzed 840 physician-annotated outputs across six medical tasks. Using a taxonomy that classified errors by risk level (from No Risk to High Risk) and type (e.g., hallucinations, omissions), self-supervised distillation improved the F1 score for safe/unsafe classification from 66.2% to 82.8%. Among clinical errors, fabricated claims were most common (45.7%), followed by missing claims (14.0%) and incorrect recommendations (12.6%).
The EVAL framework , applied to upper gastrointestinal bleeding management, combined expert-generated questions with real-world queries from physician trainees. Its reward model, trained on human-graded responses, replicated human grading 87.9% of the time and improved accuracy through rejection sampling by 8.36%. These frameworks demonstrate how structured human feedback can scale clinical validation without requiring constant expert oversight for every output.
Next, we’ll explore how Latitude’s structured workflow builds on these strategies to refine LLM validation further.
Latitude’s Workflow for Structured Human Feedback
Latitude offers a structured workflow that builds on earlier methods to ensure consistent quality improvements in production environments. As an open-source AI engineering platform, it organizes the feedback loop from monitoring production behavior to implementing ongoing enhancements.
Observing and Debugging LLM Behavior
Latitude captures full telemetry from live traffic, including inputs, outputs, tool calls, and context. This comprehensive visibility helps teams pinpoint where the AI system falls short of expectations. The platform groups these failures into recurring issues, and teams using Latitude have reported an 80% reduction in critical errors reaching production.
The Interactive Playground feature allows engineers to replicate specific runs from production logs, using real inputs to diagnose and address problems effectively. Once issues are identified, structured human feedback transforms these findings into actionable signals for improvement.
Structured Feedback Collection
Latitude’s Human-in-the-Loop (HITL) framework simplifies feedback collection by enabling experts to review logs and provide either binary pass/fail judgments or detailed numerical ratings. This approach converts qualitative expert analysis into measurable data that drives optimization.
In June 2024, Salus AI used Latitude-style workflows to improve LLM performance for marketing compliance tasks. By involving domain experts in analyzing failure modes and refining prompts, the project boosted model accuracy from 80% to between 95% and 100%. Feedback can be submitted manually through Latitude’s interface or programmatically via API to capture user input directly from end applications.
Running Evaluations and Driving Continuous Improvement
Latitude follows a six-stage Reliability Loop : Design, Test, Deploy, Trace, Evaluate, and Improve. This cycle systematically turns failures into opportunities for enhancement. By combining human judgment with automated metrics through Composite Scores, the platform offers a well-rounded view of prompt performance.
The GEPA system (Guided Exploratory Prompt Adjustment) automatically tests prompt variations to address recurring failures. Users have reported a 25% improvement in accuracy within the first two weeks of implementation, with prompt iteration becoming up to 8x faster when using GEPA optimization.
“LLM observability is no longer a luxury - it is a necessity for enterprise GenAI success.” - Snorkel AI
Latitude’s structured workflow tackles one of the most pressing challenges in AI: effectively measuring and improving quality while transforming production insights into continuous advancements.
Future Directions: Advancing Human Feedback in LLM Validation
The future of feedback systems for large language models (LLMs) is all about cutting costs, speeding up iterations, and creating seamless collaboration between product and engineering teams. Research is focusing on adaptive learning , scalable feedback systems , and collaborative workflows to make validation faster and more efficient while maintaining high standards.
Adaptive Learning Systems
Adaptive learning systems focus on areas where models are uncertain, using reinforcement learning to improve performance. For example, active learning algorithms like ADPO (Active Direct Preference Optimization) target “sub-optimality gaps”, which are areas where the model struggles most.
Techniques like PE-RLHF (Parameter Efficient Reinforcement Learning from Human Feedback) are game-changers. By using methods such as LoRA (Low-Rank Adaptation), PE-RLHF reduces the memory needed for training and speeds up processes significantly - cutting reward model training time by up to 90% and reinforcement learning time by 30%, while also reducing memory usage by 27% to 50%. This makes it feasible to continuously align models without the need for massive infrastructure.
A real-world example of adaptive learning in action comes from a 2025 pilot program with U.S.-based customer support agents. The Agent-in-the-Loop (AITL) framework incorporated real-time feedback using four types of annotations: pairwise preferences, agent adoption signals, knowledge relevance ratings, and missing knowledge identification. This approach led to an 11.7% increase in retrieval recall, a 14.8% boost in precision, and an 8.4% improvement in generation helpfulness - all while reducing retraining cycles from months to just weeks.
Building on these adaptive systems, scalable feedback mechanisms aim to further minimize the need for extensive human input.
Scalable Feedback Mechanisms
Scalable feedback systems focus on prioritizing the most critical data for human review. For instance, frameworks like RLTHF (Reinforcement Learning from Targeted Human Feedback) use reward distributions to identify the top 6%–7% of data samples that require human attention. The rest can be managed through AI-generated feedback or proxy models.
A promising approach is RLAIF (Reinforcement Learning from AI Feedback), which uses existing LLMs to generate preference labels on a large scale. This method has shown performance levels comparable to human-only feedback in tasks like summarization and dialogue.
“Human feedback is mostly collected by frontier AI labs and kept behind closed doors.” - Shachar Don-Yehiya
Emerging tools like Online AI Feedback (OAIF) are taking things a step further. These systems allow product teams to define validation criteria in natural language, which are then immediately operationalized by engineering systems. This eliminates the disconnect between what product teams want and how engineers implement those requirements.
These scalable systems are paving the way for better collaboration between product and engineering teams.
Improving Collaboration Between Product and Engineering Teams
One of the biggest challenges in LLM validation isn’t technical - it’s organizational. Human insights are crucial for aligning model performance, and frameworks like meta-alignment help formalize this process. For example, NPO (Alignment and Meta-Alignment) introduces “monitoring fidelity”, which creates inspectable systems that connect product goals with engineering reliability triggers. These frameworks use structured feedback - like overrides, abstentions, and scenario scoring - to determine when a model needs retraining or immediate intervention.
“NPO offers a compact, inspectable architecture for continual alignment monitoring, helping bridge theoretical alignment guarantees with practical reliability in dynamic environments.” - Madhava Gaikwad, Microsoft
Collaborative tools like CollabLLM turn models into active partners in the feedback process. By using multiturn-aware rewards, these systems better understand user intent, increasing satisfaction by 17.6% and cutting user interaction time by 10.4% in production trials. The move toward real-time, iterative feedback - where models adapt based on live responses instead of static datasets - ensures that alignment keeps up with evolving product requirements.
To make this collaboration seamless, engineering teams should embed feedback mechanisms directly into user interfaces. This approach captures high-quality signals without requiring separate annotation sessions. Meanwhile, product managers can set clear thresholds for when models need intervention, transforming alignment into an ongoing, measurable process.
Conclusion
Human feedback is essential for validating large language models (LLMs) effectively. While automated metrics can highlight surface-level issues, they often miss the deeper, more critical problems - like biased reasoning, insensitivity, hallucinations, or failing to align with user intent. Humans are the only ones capable of evaluating nuanced factors like tone, appropriateness, and coherence, which are crucial for building user trust and encouraging adoption.
The evidence backs this up: blending human judgment with automated validation creates a feedback loop that speeds up improvement cycles. For example, in October 2025, a U.S.-based customer support pilot using an Agent-in-the-Loop framework reduced model retraining times from months to weeks. This approach also increased generation helpfulness by 8.4% and agent adoption rates by 4.5%. Similarly, targeted human feedback frameworks like RLTHF (Reinforcement Learning through Human Feedback) achieved alignment comparable to full human annotation but required only 6% to 7% of the usual effort.
“User feedback isn’t just the cherry on top; it’s an essential ingredient for robust, adaptable, and - most importantly - ethical LLMs.” - Kayley Marshall, Deepchecks
The future of LLM validation lies in hybrid systems that strategically combine human and machine input. High-stakes decisions demand human-in-the-loop oversight. Scalable monitoring benefits from human-on-the-loop supervision. Rapid iteration thrives with LLM-as-a-judge scoring. But none of these approaches work without structured human feedback to define what “good” means and to adapt those standards as user needs evolve.
The best AI teams don’t see it as a choice between humans and automation. Instead, they design workflows where the two complement each other, creating AI products that don’t just meet benchmarks but also earn trust and deliver meaningful results in real-world applications.
FAQs
When should humans review LLM outputs vs automated checks?
Humans play a key role in reviewing outputs from large language models (LLMs), especially when automation falls short in delivering accuracy, reliability, or aligning with human expectations. This becomes particularly important for tasks that demand context, subtlety, or subjective interpretation - like evaluating appropriateness or handling complex outputs. Human input is also essential for refining evaluation standards, correcting any drift in criteria, and addressing the limitations that automated systems might inherit from the models. In situations where ambiguity arises, human judgment helps ensure better alignment and decision-making.
What’s the best human feedback method for my use case?
The most effective method for gathering human feedback depends on your specific objectives and workflow. Studies highlight the benefits of blending human-in-the-loop evaluation with active learning techniques. Human-in-the-loop involves integrating human judgment into the model validation process, ensuring the results align with user preferences. Meanwhile, active learning directs human attention to the most valuable and informative data points, making the process more efficient. When combined, these strategies help streamline workflows and achieve dependable, user-focused model performance.
How can teams reduce the cost of human feedback?
Teams can cut down on the expense of gathering human feedback by leveraging synthetic feedback from large language models (LLMs). This can take the place of some human evaluations, reducing costs. Additionally, techniques like optimizing prompts , applying model approximation methods , and routing tasks between human or AI feedback based on predicted performance can further streamline the process. These strategies ensure evaluation quality stays intact while minimizing the dependence on expensive human annotations.