

Evaluating AI prompts is no longer a casual task - it’s a necessary process to ensure outputs are accurate, relevant, and safe. Poorly tested prompts can lead to hallucinations , wasted resources, and a loss of user trust. This article breaks down the challenges of prompt engineering and evaluation and highlights the best metrics for scaling this process effectively.
Here’s what you need to know:
-
Traditional metrics like BLEU and ROUGE are fast but outdated, as they rely on exact word matches rather than meaning.
-
Modern metrics like BERTScore use contextual embeddings to better align with human judgment, though they require more computational resources.
-
Newer methods like LLM-as-a-Judge leverage AI models (e.g., GPT-4) to evaluate outputs using natural language rubrics, offering the highest alignment with human evaluations but at a higher cost.
-
Key evaluation areas include groundedness (factual alignment), correctness , and relevance.
-
Tools like Latitude streamline evaluation by combining automated metrics, human feedback, and observability workflows.
Standard Metrics for Prompt Evaluation
Limitations of BLEU and ROUGE
For years, BLEU and ROUGE have been the go-to metrics for evaluating text quality. BLEU became synonymous with machine translation, while ROUGE found its place in text summarization tasks [16, 19]. But both metrics share a fundamental flaw: they rely on exact n-gram overlap - essentially counting matching words rather than assessing meaning. As Tianyi Zhang from Cornell University puts it:
“Bleu… simply counts n-gram overlap between the candidate and the reference. While this provides a simple and general measure, it fails to account for meaning-preserving lexical and compositional diversity”.
This means that if a model generates “consumers prefer imported cars” instead of the reference “people like foreign cars”, BLEU and ROUGE would penalize the model, even though both phrases mean the same thing [16, 18]. These metrics struggle with paraphrases, alternative word orders, and distant dependencies. They also penalize outputs for semantically important changes in order but often fail to align with human judgment [16, 18, 20].
Adding to the complexity, BLEU prioritizes precision (relevance), whereas ROUGE leans toward recall (completeness). This can result in misleading scores when an output is precise but incomplete or overly verbose. Recognizing these shortcomings, newer metrics like BERTScore aim to bridge the gap.
BERTScore: Contextual Embeddings
Unlike BLEU and ROUGE, BERTScore evaluates semantic similarity using contextual embeddings. By calculating cosine similarity between token vectors, it captures meaning far better than simple word matches. This approach aligns much closer to human evaluations, with correlation coefficients reaching about 0.93, compared to BLEU’s 0.70. Tested across 363 machine translation and image captioning systems, BERTScore supports 104 languages and excels at identifying paraphrases and subtle semantic nuances that traditional metrics often miss.
The trade-off? BERTScore demands more computational power. For instance, using a model like RoBERTa-large requires around 1.4GB of memory and increases processing time by 2–3×. However, for teams focused on scaling prompt evaluations, this extra cost is often worth it. The metric’s stronger alignment with human judgment ensures evaluations better reflect nuanced expectations, making it a valuable tool for more accurate and meaningful assessments.
Modern Metrics for Evaluating Prompts
Modern approaches to evaluating prompts go beyond traditional metrics, incorporating deeper semantic and evaluative dimensions. These advancements are crucial for addressing challenges like detecting hallucinations and managing variability in AI-generated outputs.
Groundedness, Correctness, and Relevance
As AI systems evolve beyond simple text generation, three key metrics have become central to assessing quality: groundedness , correctness , and relevance.
-
Groundedness evaluates how well an AI model’s output aligns factually with the provided retrieval context. This is vital for avoiding hallucinations, especially in Retrieval-Augmented Generation (RAG) pipelines where responses must remain tethered to a knowledge base.
-
Correctness measures the factual accuracy of the output compared to a defined “ground truth” or reference answer.
-
Relevance ensures that the response directly addresses the user’s input or intent. It focuses on providing answers that are both informative and concise, avoiding unnecessary or tangential information.
LLM-as-a-Judge Metrics
The LLM-as-a-Judge approach leverages models like GPT-4 or Claude to evaluate outputs using natural language rubrics and chain-of-thought reasoning. This method frames evaluation as a reasoning task, often aligning more closely with human judgment than traditional metrics.
-
G-Eval employs chain-of-thought reasoning to generate evaluation steps before assigning a score, typically on a 1–5 scale.
-
QAG (Question Answer Generation) Score extracts claims from the output and generates close-ended “yes/no” questions to calculate a final score. This reduces the subjectivity often seen in direct scoring methods.
The efficiency of this approach is notable. As Cem Dilmegani, Principal Analyst at AIMultiple, explains:
“LLM-as-a-judge provides businesses with high efficiency by quickly assessing millions of outputs at a fraction of the expense of human review”.
However, using an LLM as a judge isn’t foolproof. To ensure factual and reliable evaluations, it’s recommended to set the temperature to 0, minimizing the risk of hallucinations at the judge level. Beyond numerical scores, assessing text coherence and consistency further enhances the evaluation process.
Coherence and Consistency
Coherence refers to the logical flow and internal consistency of the generated text. Frameworks like LEval test multi-turn dialogue coherence, examining how well models maintain logical progression over extended interactions.
Consistency (or reliability) is equally critical, as LLMs can be highly sensitive to minor changes in prompt phrasing. In May 2025, researchers from the Hebrew University of Jerusalem and Bar-Ilan University introduced ReliableEval. This framework evaluated five leading LLMs, including GPT-4o and Claude-3.7-Sonnet, and found that even the most advanced models showed significant sensitivity to meaning-preserving prompt variations. This underscores the importance of testing prompts across multiple iterations to ensure consistent performance in real-world applications.
Comparing Key Metrics
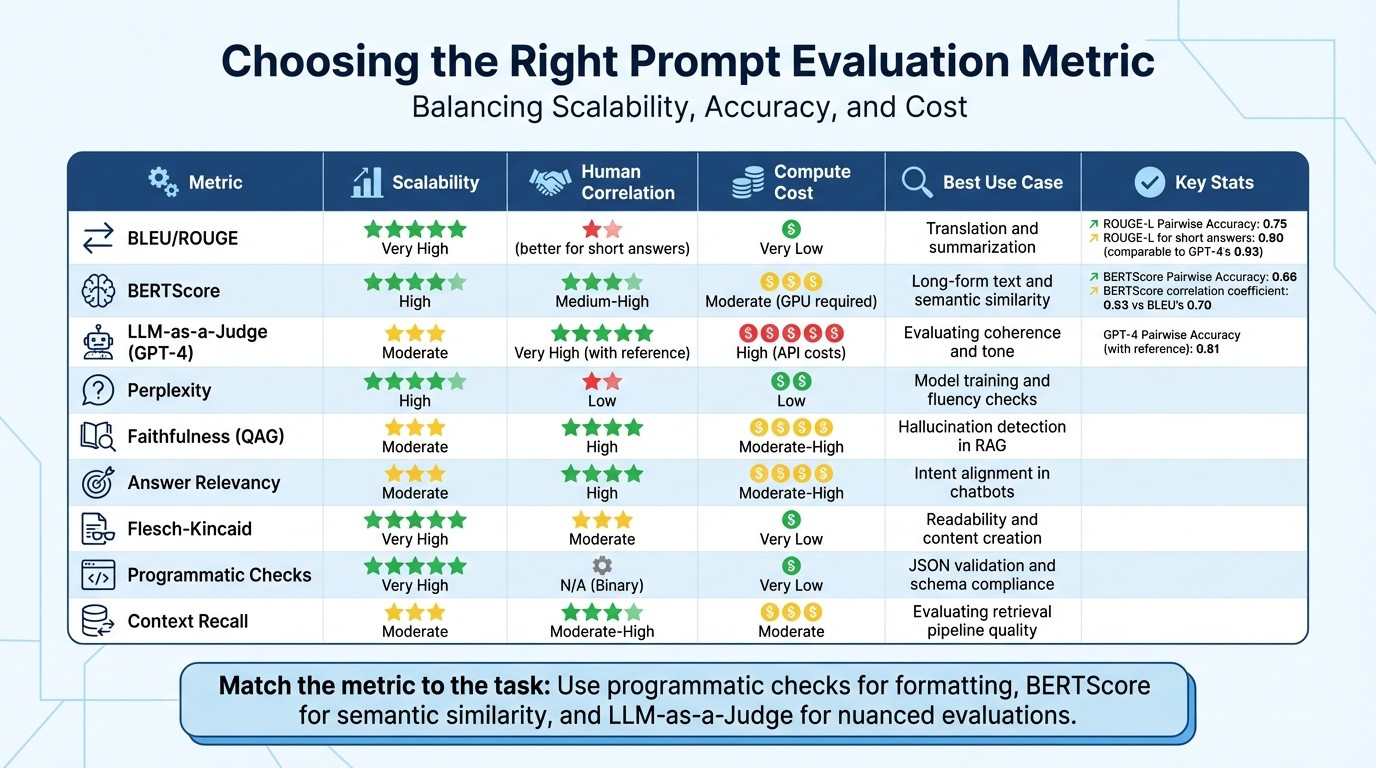
Comparison of AI Prompt Evaluation Metrics: Performance, Cost, and Use Cases
Choosing the right metric is a balancing act between scalability, alignment with human judgment, and computational expense. Traditional options like BLEU and ROUGE are lightning-fast and inexpensive because they rely on basic n-gram overlaps. However, they often fall short when it comes to reflecting human judgment in open-ended tasks. On the other hand, BERTScore uses contextual embeddings to better capture semantic meaning, offering a closer match to human expectations while still being computationally manageable. At the top of the spectrum are LLM-as-a-Judge methods, such as those powered by GPT-4, which show the strongest alignment with human evaluations but come with a higher computational price tag. These considerations set the stage for a deeper dive into key meta-evaluation results.
Meta-evaluation of English tasks reveals these distinctions clearly. When reference answers are available, GPT-4 achieves a Pairwise Accuracy of 0.81, while ROUGE-L and BERTScore lag behind at 0.75 and 0.66, respectively. However, without reference answers, GPT-4’s accuracy drops to 0.62, reflecting a tendency to favor longer outputs. Ehsan Doostmohammadi from Linköping University offers a key insight:
“GPT-4 aligns well with human judgments when gold reference answers are available. However, its reliability diminishes in the absence of these references, where it shows an overly positive bias”.
Metrics Comparison Table
Here’s a snapshot of each metric’s strengths and ideal applications:
| Metric | Scalability | Human Correlation | Compute Cost | Best Use Case |
|---|---|---|---|---|
| BLEU/ROUGE | Very High | Low (better for short answers) | Very Low | Translation and summarization |
| BERTScore | High | Medium-High | Moderate (GPU required) | Long-form text and semantic similarity |
| LLM-as-a-Judge (GPT-4) | Moderate | Very High (with reference) | High (API costs) | Evaluating coherence and tone |
| Perplexity | High | Low | Low | Model training and fluency checks |
| Faithfulness (QAG) | Moderate | High | Moderate-High | Hallucination detection in retrieval-augmented generation |
| Answer Relevancy | Moderate | High | Moderate-High | Ensuring intent alignment in chatbots |
| Flesch-Kincaid | Very High | Moderate | Very Low | Readability and content creation |
| Programmatic Checks | Very High | N/A (Binary) | Very Low | JSON validation and schema compliance |
| Context Recall | Moderate | Moderate-High | Moderate | Evaluating retrieval pipeline quality |
For short-answer tasks, ROUGE-L is almost on par with GPT-4, achieving a Pairwise Accuracy of 0.90 compared to GPT-4’s 0.93. This makes it a cost-effective and reliable option for high-volume evaluations. For example, teams using Braintrust reported a 30% improvement in accuracy by switching from subjective evaluations to systematic metric-driven assessments.
The key takeaway? Match the metric to the task. Use programmatic checks for formatting, BERTScore for semantic similarity, and LLM-as-a-Judge methods for nuanced evaluations of subjective elements like tone. These comparisons lay the groundwork for scaling strategies, which will be explored further in the discussion on Latitude-powered workflows.
Using Latitude to Scale Prompt Evaluations
Observability and Feedback Workflows
Latitude tackles scaling challenges by combining automated traceability with human judgment, aligning with previously discussed metrics. At the core of this process is the Reliability Loop - a continuous cycle of Design, Test, Deploy, Trace, Evaluate, and Improve. This loop transforms production data into better prompt strategies over time. Through its AI Gateway , Latitude automatically logs interactions, including inputs, outputs, metadata, and performance metrics, directly from production. This means teams don’t need to modify their code manually to gain insights into production behavior.
The Human-in-the-Loop (HITL) workflow plays a key role by allowing domain experts to manually review logs and provide scores or labels. This approach captures nuanced human judgments that automated metrics might overlook. Organizations using Latitude’s evaluation platform have reported up to a 40% improvement in prompt quality , alongside a significant drop in hallucination rates, achieving 92% accuracy in prompt assessments. A Senior Prompt Engineer highlighted the impact:
“The combination of human expertise and AI-powered evaluation tools has revolutionized our prompt development process. We’ve seen a 68% reduction in hallucination rates while maintaining high-quality outputs.”
Human reviewers’ assessments can vary by as much as 40% , but Latitude counters this with standardized 5-point rating rubrics and calibration protocols to minimize variability. These human-validated results are used to create “golden datasets”, which later help calibrate automated evaluations. By bridging subjective quality assessments with scalable tools, Latitude ensures a balanced and robust evaluation process. This automated observability complements earlier metrics by providing a strong foundation of reliable data.
Running and Iterating Metrics at Scale
Latitude simplifies the process of running and refining multiple evaluation methods at scale. The platform supports three key methodologies: LLM-as-a-Judge for subjective evaluations like tone and creativity, Programmatic Rules for objective checks such as JSON validation and regex patterns, and Human-in-the-Loop for detailed quality assessments. Teams can execute these evaluations in Batch Mode for regression testing or in Live Mode to monitor real-time performance.
For example, a compliance implementation leveraging Latitude’s refinement process saw a 25% increase in accuracy , while reducing the need for manual oversight by 40%. Centralized dashboards provide a clear view of log scores, tracking time-series trends and composite scores. These features enable teams to detect performance regressions early. Additionally, teams can create Composite Scores to serve as high-level indicators of prompt performance, making it easier to monitor and improve outcomes over time.
Key Takeaways for Evaluating Prompts
When evaluating prompts, it’s essential to use multiple templates. Even small changes in template design can lead to performance differences of up to 76 points. To get a full picture of performance, analyze the distribution using the 95th percentile , median , and 5th percentile scores. This helps highlight expert-level results, typical outcomes, and potential risks for less experienced users.
A robust evaluation process combines several methods: leveraging LLM-as-Judge for tone analysis, applying programmatic rules for objective checks, and incorporating Human-in-the-Loop reviews to create comprehensive datasets. This approach can speed up development by 45% while maintaining 92% accuracy in prompt assessments. As Felipe Maia Polo and his team from the University of Michigan emphasized:
“An ideal evaluation framework should minimize dependence on any single prompt template and instead provide a holistic summary of performance across a broad set of templates”.
To simplify tracking and analysis, composite scoring merges various metrics into one performance indicator. This allows teams to monitor overall quality while diving into specific areas for improvement. For retrieval-based applications, the RAG Triad offers a structured evaluation framework by focusing on three key factors: faithfulness (is the response grounded in the provided context?), answer relevancy (does it directly address the question?), and contextual precision (is the retrieved context actually useful?). Additionally, Question Answer Generation (QAG) can be used to generate close-ended “yes/no” questions about claims, resulting in more reliable scoring.
Treat prompts as structured contracts with clear criteria and formats. Include explicit success benchmarks, well-defined input structures (like XML-style tags), and clear output expectations. Regular audits against human-annotated data ensure alignment with quality standards, helping refine and improve prompt design over time. These strategies provide a strong foundation for scalable and effective prompt evaluation.
FAQs
What are the limitations of using BLEU and ROUGE for evaluating prompts?
BLEU and ROUGE, while widely used, have some clear shortcomings when it comes to evaluating prompts. These metrics rely heavily on comparing text for exact matches or overlaps, which means they often miss the deeper semantic meaning behind a response. This can result in nonsensical or poorly constructed outputs earning high scores simply because they share similar words or phrases with the reference text.
Another issue is their assumption that there’s only one “correct” answer. For tasks that allow for multiple valid responses - like creative writing or nuanced discussions - this approach falls short. It can create incomplete or even biased evaluations, particularly for more complex language tasks where flexibility and creativity are key.
What makes BERTScore a better metric for evaluating prompts compared to traditional methods?
BERTScore is a standout method for evaluating prompts because it goes beyond surface-level word matching. Instead of relying on simple word overlap like traditional metrics such as BLEU, BERTScore uses contextual embeddings from the pre-trained BERT model to measure the cosine similarity between token embeddings. This allows it to capture deeper semantic connections, making it more effective at recognizing paraphrasing and lexical variations.
What sets BERTScore apart is how closely it aligns with human judgment. By focusing on the meaning of text rather than just matching words, it provides a more accurate evaluation. Research has shown that BERTScore performs particularly well in tasks like machine translation and image captioning, where it consistently shows stronger correlations with human assessments of quality. Its ability to handle diverse ways of expressing the same idea makes it a dependable choice for evaluating prompts on a large scale.
Why is the LLM-as-a-Judge method worth the higher cost for evaluating prompts?
The LLM-as-a-Judge method stands out for its high level of accuracy in ranking and evaluating models. By calibrating surrogate metrics, addressing calibration uncertainty, and enhancing coverage, it provides reliable and consistent evaluation results. While it may come with a higher price tag, the quality of insights it delivers makes it a worthwhile choice.
This method is especially effective for scaling evaluations, offering strong performance insights that play a key role in fine-tuning AI-powered features and workflows.