
AI Evals Playbook
Free Download
A practical guide to evaluating AI agents in production.
Download the playbook ↓
What’s inside
A step-by-step system for evaluating AI agents in production.
Including:
Why traditional testing breaks for LLMs (and what to do instead)
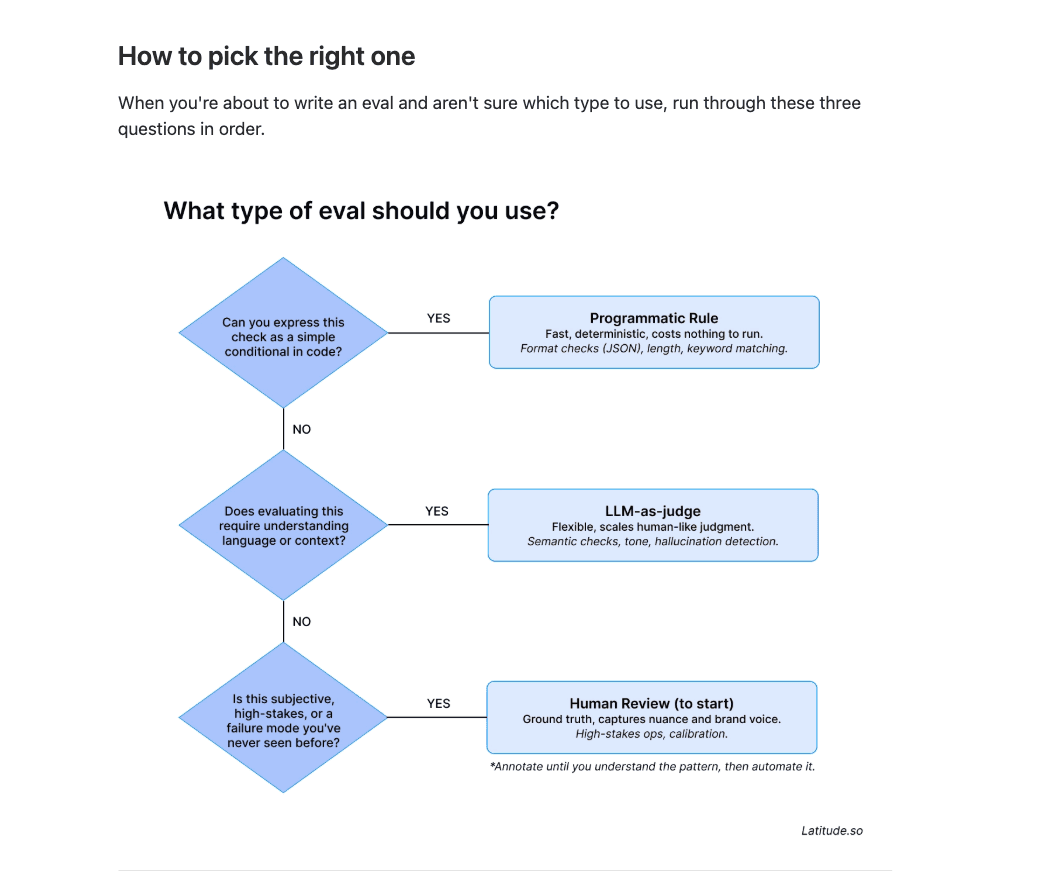
The three eval types and when to use each one
How to turn production failures into automated evals
A first-week checklist to go from zero to running evals
Why it matters
Evaluating LLMs is hard. Outputs are inconsistent, "good enough" is impossible to define, and most teams are still testing against a handful of examples and hoping nothing breaks in production.
This playbook answers the questions we hear every week:
How to evaluate LLM outputs beyond vibes
How to pick the right eval method for your use case
What metrics actually tell you something useful
How to build a system that catches failures before your users do.
Who this playbook is for
AI engineers and developers building agents, assistants, or any LLM-powered feature
Product managers responsible for the quality of AI features in production
Startups and product teams shipping AI and looking for a repeatable way to evaluate it
Anyone comparing eval tools and trying to figure out what actually matters
By Latitude
Latitude is the evaluation and observability platform for AI agents. Trace what's happening in production, find what's breaking, and build evals that actually match your product. Used by 400+ AI teams.
What is this page
Everything you need to evaluate LLMs and AI agents in production, in one place.
How to evaluate LLM outputs, responses, and agent behavior
How to build a repeatable LLM evaluation framework and pick the right metrics
How to compare AI evaluation tools for accuracy, speed, and reliability
Guides on AI evaluation metrics that actually matter for product teams
Comparisons of the best platforms for AI model evaluation and benchmarking