

As AI continues to revolutionize industries, one area ripe for transformation is unstructured document processing. From court transcripts to medical records, extracting value from large-scale, heterogeneous data sources is a daunting challenge. This article explores the innovative research of Shrea Shankar, who combines data systems, human-computer interaction (HCI), and cutting-edge AI methods to address the complexities of processing documents at scale using semantic operators. Whether you’re a product manager striving to improve AI quality or an engineer optimizing workflows for large language models (LLMs), this comprehensive breakdown offers actionable insights.
Introduction: Unlocking the Power of Semantic Data Processing
Traditional data systems have been instrumental in managing and analyzing structured, tabular information. However, much of the world’s data today is unstructured, encompassing text, images, and audio. These formats pose unique challenges for querying and processing at scale. Enter semantic data processing - a paradigm that uses AI, specifically LLMs, to redefine traditional data operations like map, filter, and reduce. By allowing developers and analysts to express queries in natural language, semantic operators enable complex data transformations that would otherwise be infeasible.
Shankar’s work sheds light on this emerging field, offering methods to scale these operations, make them user-friendly, and align them with real-world tasks. Here, we’ll explore her key contributions, including the DocETL system , the DocWrangler interface , and innovative approaches to evaluation and optimization.
The Problem: Challenges in Document Processing at Scale
Unstructured data comes with several hurdles that make processing tasks, such as identifying patterns or summarizing insights, particularly difficult:
-
Heterogeneity : Data like court transcripts, police reports, or medical conversations often include diverse formats (e.g., audio, text, video).
-
Cost and Accuracy : Using state-of-the-art LLMs across massive datasets can be prohibitively expensive without guarantees of accuracy.
-
Subjectivity : Tasks like identifying implicit bias or summarizing human conversations often require nuanced reasoning that AI struggles to handle.
-
Scalability : Running LLMs at scale requires advanced query optimization to ensure affordable and efficient performance.
Shankar’s research tackles these issues directly, combining traditional database thinking with AI techniques to power end-to-end semantic data pipelines.
Semantic Operators: A New Paradigm for Data Processing
What Are Semantic Operators?
Semantic operators extend traditional data processing concepts like map, filter, and reduce by incorporating open-ended, natural language queries powered by LLMs. For example:
-
Semantic Map : Extract structured information, like judges’ names or biased statements, from raw text.
-
Semantic Filter : Identify and keep only documents meeting specific criteria, such as those containing evidence of bias.
-
Semantic Reduce : Summarize grouped data, such as all transcripts associated with a specific judge.
The true power of semantic operators lies in their composability - users can chain these operations to form pipelines that answer highly complex questions.
System Innovations: Scaling Semantic Operators with DocETL
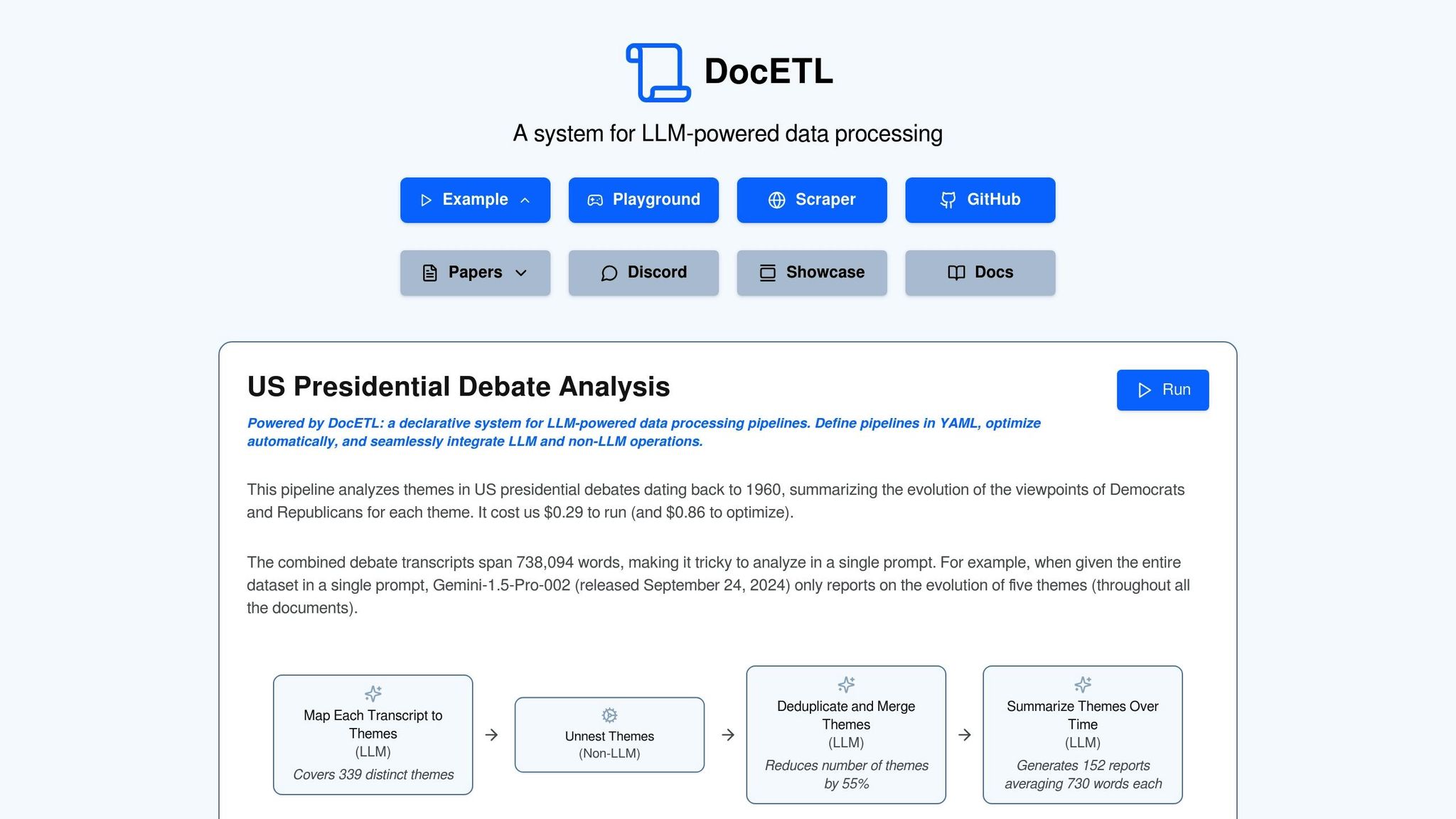
The DocETL System
Shankar’s open-source system, DocETL , pioneers scalable implementations of semantic operators. Two key questions drive the system’s design:
-
Scalability : How can we optimize queries to handle thousands of documents efficiently without inflating costs?
-
Steerability : How can users control the behavior of AI to ensure accurate results?
Key Contributions in Scalability
-
Query Optimization : Inspired by traditional database systems, DocETL explores different plans to execute semantic pipelines, balancing accuracy, latency, and cost. For instance, a simpler, cheaper model may handle easier tasks while complex cases are routed to more powerful LLMs.
-
Rewrite Directives : By breaking down tasks into smaller, more manageable operations (e.g., splitting a document into chunks), DocETL ensures that LLMs operate within their capabilities, improving both accuracy and cost-efficiency.
-
Task Cascades : This approach dynamically routes documents through a sequence of increasingly complex models or tasks, ensuring cost-effective processing without compromising accuracy.
User-Focused Design: The DocWrangler Interface
Even the most advanced systems need to be accessible to users with varying technical expertise. DocWrangler, another key contribution from Shankar’s research, provides a user-friendly interface for authoring, refining, and validating semantic pipelines.
The Three Gulfs Framework
Shankar’s team identified three key challenges, or “gulfs”, that users face when working with unstructured data and complex pipelines:
-
Gulf of Comprehension : Users often struggle to understand the data they’re working with. DocWrangler provides tools to inspect outputs, identify patterns, and uncover edge cases.
-
Gulf of Specification : Writing precise prompts for semantic operators is challenging. DocWrangler assists users by turning their feedback into refined prompts.
-
Gulf of Generalization : Ensuring that AI models perform well on unseen data is difficult. DocWrangler suggests rewrites and decompositions to improve accuracy at scale.
Key Features of DocWrangler
-
Interactive Pipeline Editor : A notebook-like interface for building and testing semantic pipelines.
-
Output Inspector : Allows users to review LLM-generated outputs, identify errors, and refine their specifications.
-
Assisted Prompt Refinement : User feedback is incorporated into iterative improvements of the LLM prompts.
-
Decomposition Suggestions : Identifies overly complex tasks and proposes breaking them into smaller, simpler operations.
Evaluation at Scale: Iterative and Adaptive Methods
Evaluation is a cornerstone of ensuring AI systems meet user needs. Shankar’s EvalGen system introduces methods to create adaptive evaluators as users interact with outputs. Key insights include:
-
Dynamic Criteria Formation : Users often refine their evaluation criteria after observing LLM outputs, highlighting the importance of iterative labeling workflows.
-
LLM Judges : These models assist in evaluating the quality of outputs, although Shankar emphasizes that user-driven evaluation remains critical for nuanced tasks.
Broader Applications and Future Directions
While Shankar’s work focuses on document processing, its principles have broader implications for any AI-powered system:
-
Generalization to Multimodal Data : Although primarily focused on text, the semantic operator framework can be extended to images, video, and audio.
-
Agent-Based Systems : As AI agents become more complex, tools like DocWrangler could help developers debug and align agent behavior.
-
Collaborative AI : By improving human-AI interactions, Shankar’s research contributes valuable paradigms for collaborative workflows.
Key Takeaways
-
Semantic Operators Redefine Data Processing : By enabling natural language queries, they unlock complex analysis tasks for unstructured data.
-
Scalability Requires Optimization : Techniques like query rewrites, task cascades, and cost modeling ensure that pipelines remain efficient and affordable.
-
User-Centric Design Matters : Interfaces like DocWrangler bridge the gap between users and AI systems, making advanced tools accessible to non-technical stakeholders.
-
Evaluation Is Iterative : Criteria evolve as users interact with outputs, underscoring the need for adaptive and user-driven evaluation methods.
-
Broader Applications Await : The principles of semantic data processing can extend to multimodal data and agent-based systems.
Conclusion
Shrea Shankar’s research represents a transformative step in the evolution of data systems, blending the rigor of databases with the flexibility of AI. Her contributions not only advance the field of semantic data processing but also provide a roadmap for building user-friendly, scalable, and accurate AI systems. Whether you’re managing unstructured data today or envisioning the next generation of intelligent systems, Shankar’s insights serve as a powerful guide.
Source: “How to Process Documents at Scale with LLMs” -Hamel Husain, YouTube, Jan 1, 1970 -https://www.youtube.com/watch?v=t6r4U0SlnPc